Lead Feature
GET SHIT DONE: Meta-prompting and Spec-driven Development for Claude Code and Codex

GSD (“Get Shit Done”) aims to solve context rot, the quality degradation as the model’s context window fills.
•Feb 23, 2026•9 min read
Lead Feature
GSD (“Get Shit Done”) aims to solve context rot, the quality degradation as the model’s context window fills.
Archive

A practical guide to fixing OpenClaw memory failures and choosing the right memory substrate as your agent system scales.
Read Article
Most product bugs show up when a simple feature lands on a box with a 64MB RAM budget and a watchdog timer.
Read Article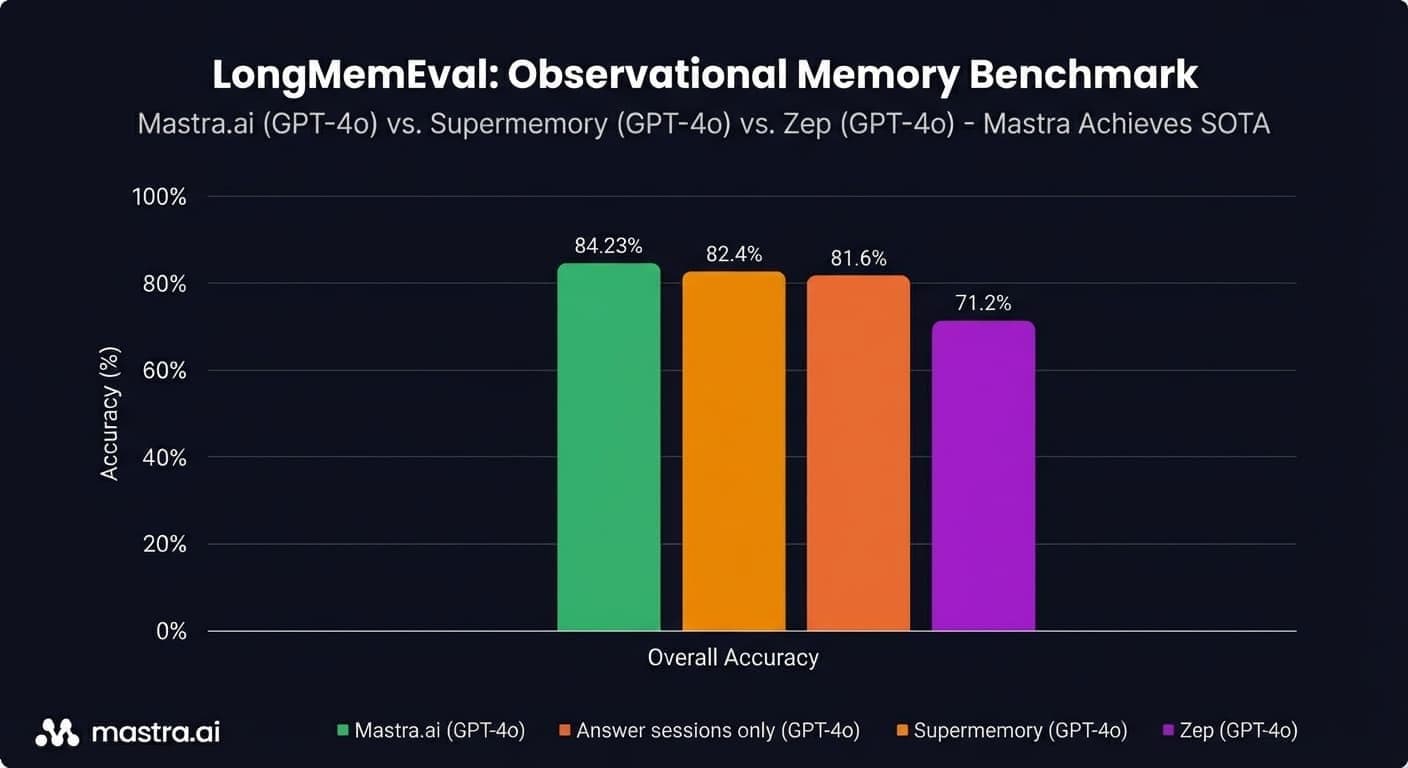
Always-on agents have unbounded context growth problem.
Read Article
Whether you think it’s hype or not, people are already trying to run fully autonomous companies on OpenClaw.
Read Article
Before any Claude fans boo me: I’m not claiming “M2.5 is Opus” but the pricing + throughput + agent-oriented training forces a new engineering question:
Read Article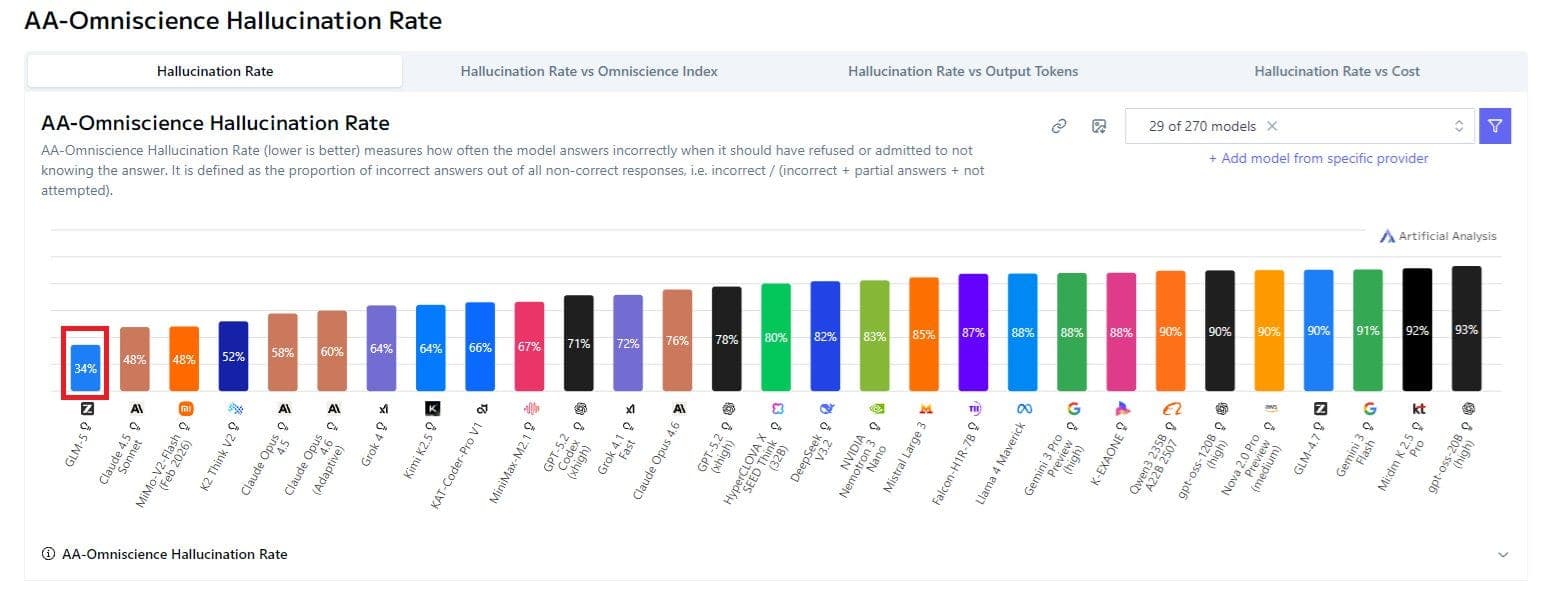
One of the most interesting parts of the GLM-5 launch is that you can run an open-weights model inside a proprietary agentic coding workflow and get something close to frontier-...
Read Article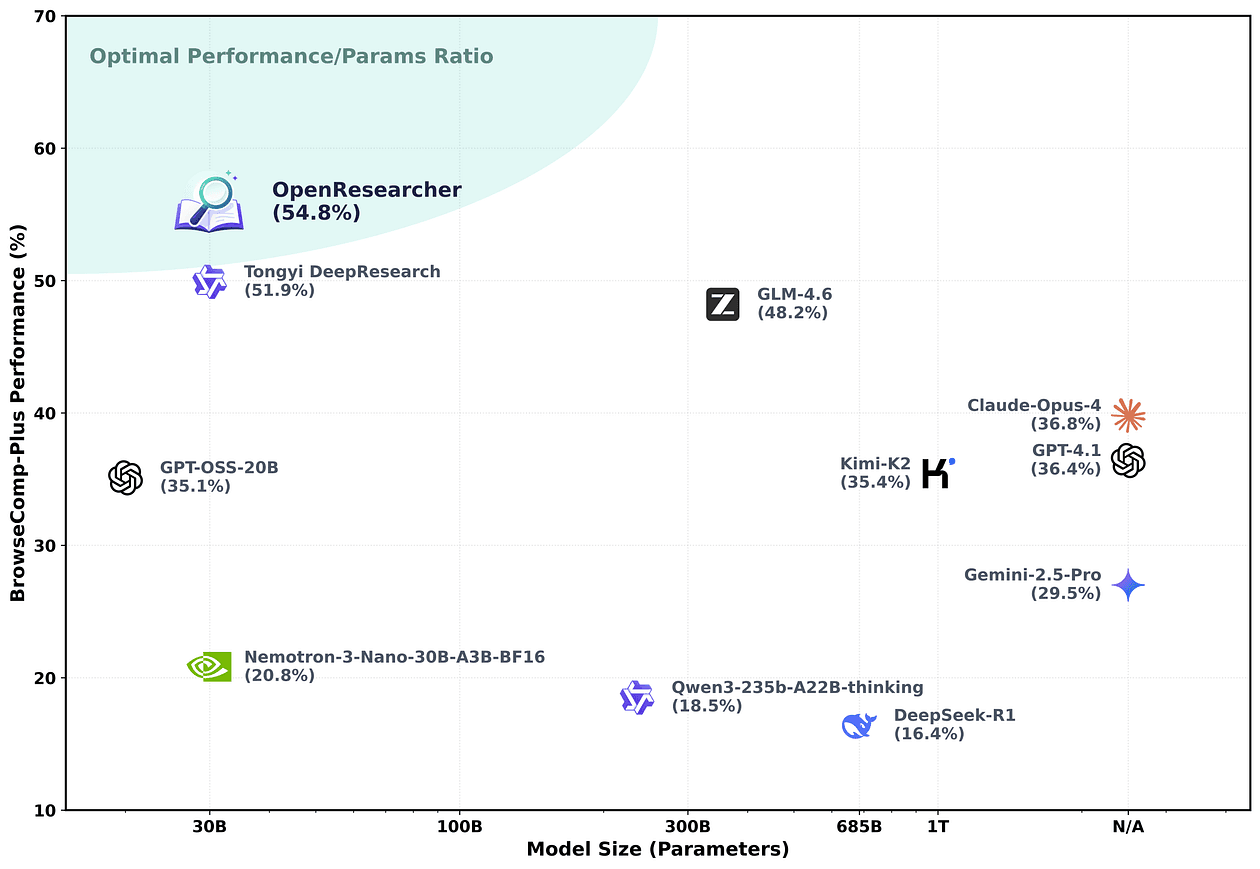
Imagine synthesizing human-like research trajectories exceeding 100 turns entirely offline, no reliance on search or scrape APIs, no rate limits, and crucially, no nondeterminism.
Read Article
We risk resurrecting the original sin of computing, a flaw that has enabled remote code execution exploits for decades.
Read Article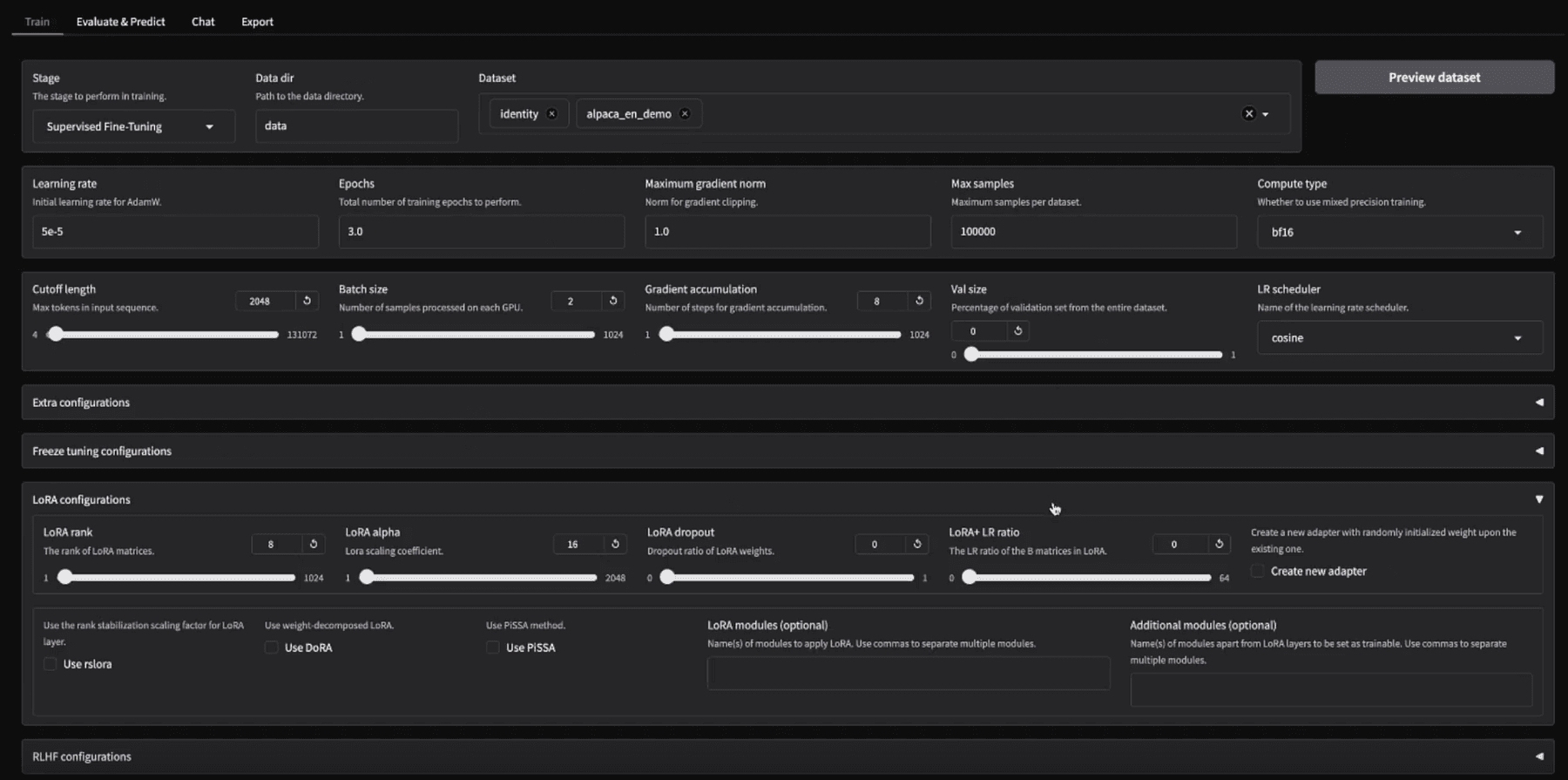
How well fine-tuning performs still depends on three factors: model size, hardware capability, and the framework you choose.
Read Article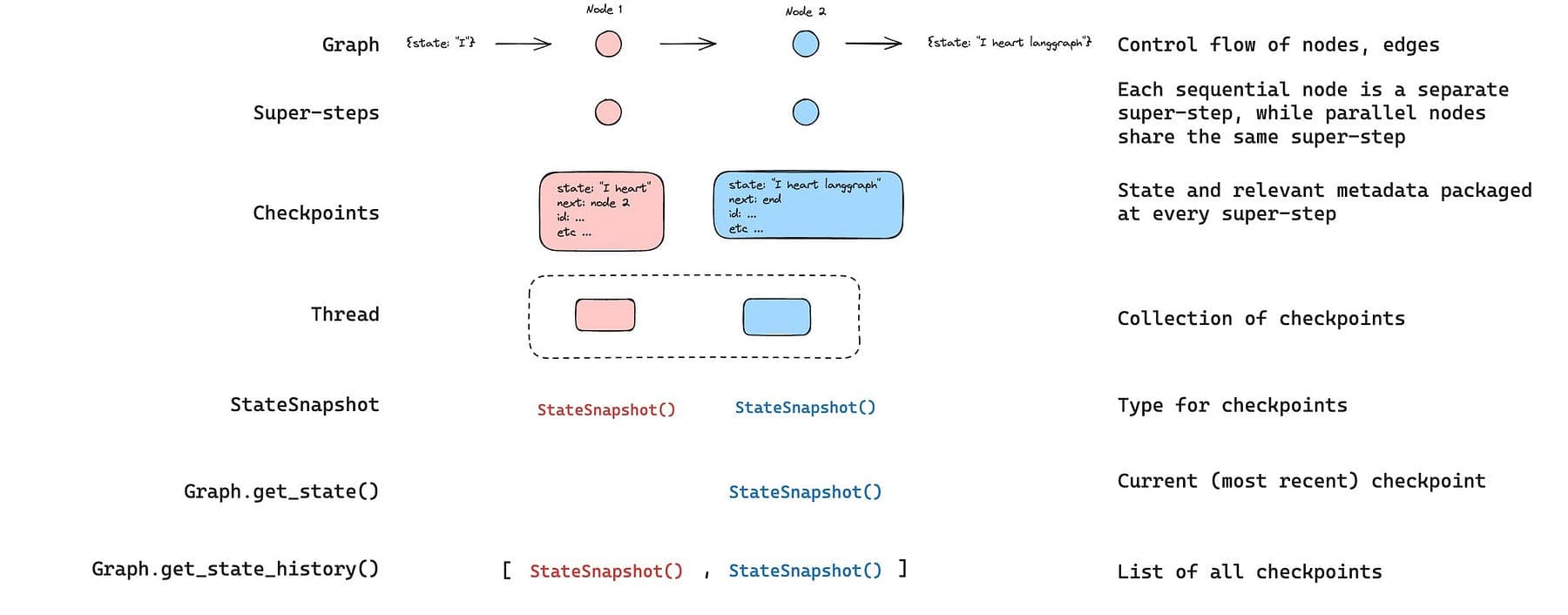
If you’ve built an LLM agent that does anything non-trivial, you’ve hit this moment:
Read Article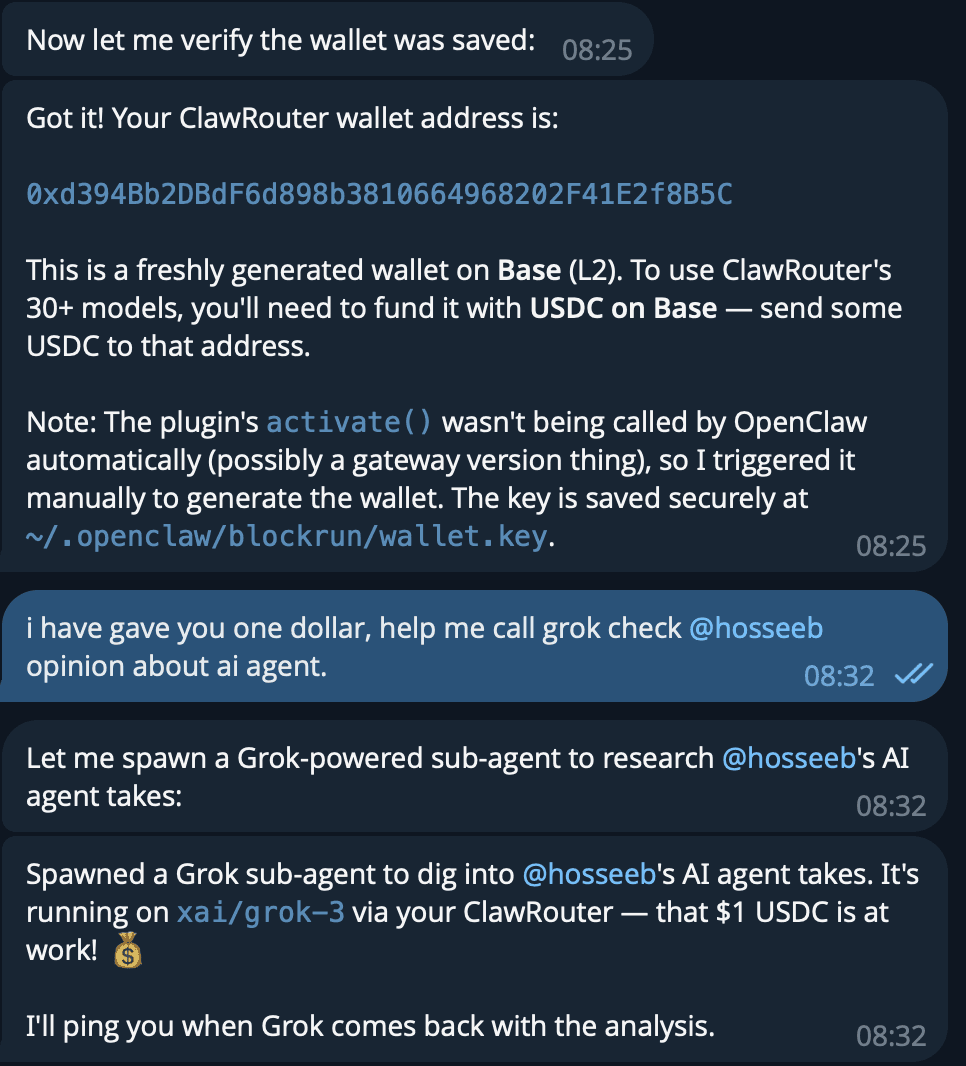
Last month I opened my credit‑card statement and almost threw up. Anthropic charged me $4,660.87, just for Claude.
Read Article
Just after 9:45 a.m. Pacific on 5 February 2026, Anthropic unveiled Claude Opus 4.6, and 20 minutes later, OpenAI counter‑punched with GPT‑5.3‑Codex.
Read Article
If you want to research, build, and launch your products fast, this is the solo founder stack for AI-native apps, zero-to-launch weekends, and practically infinite leverage.
Read Article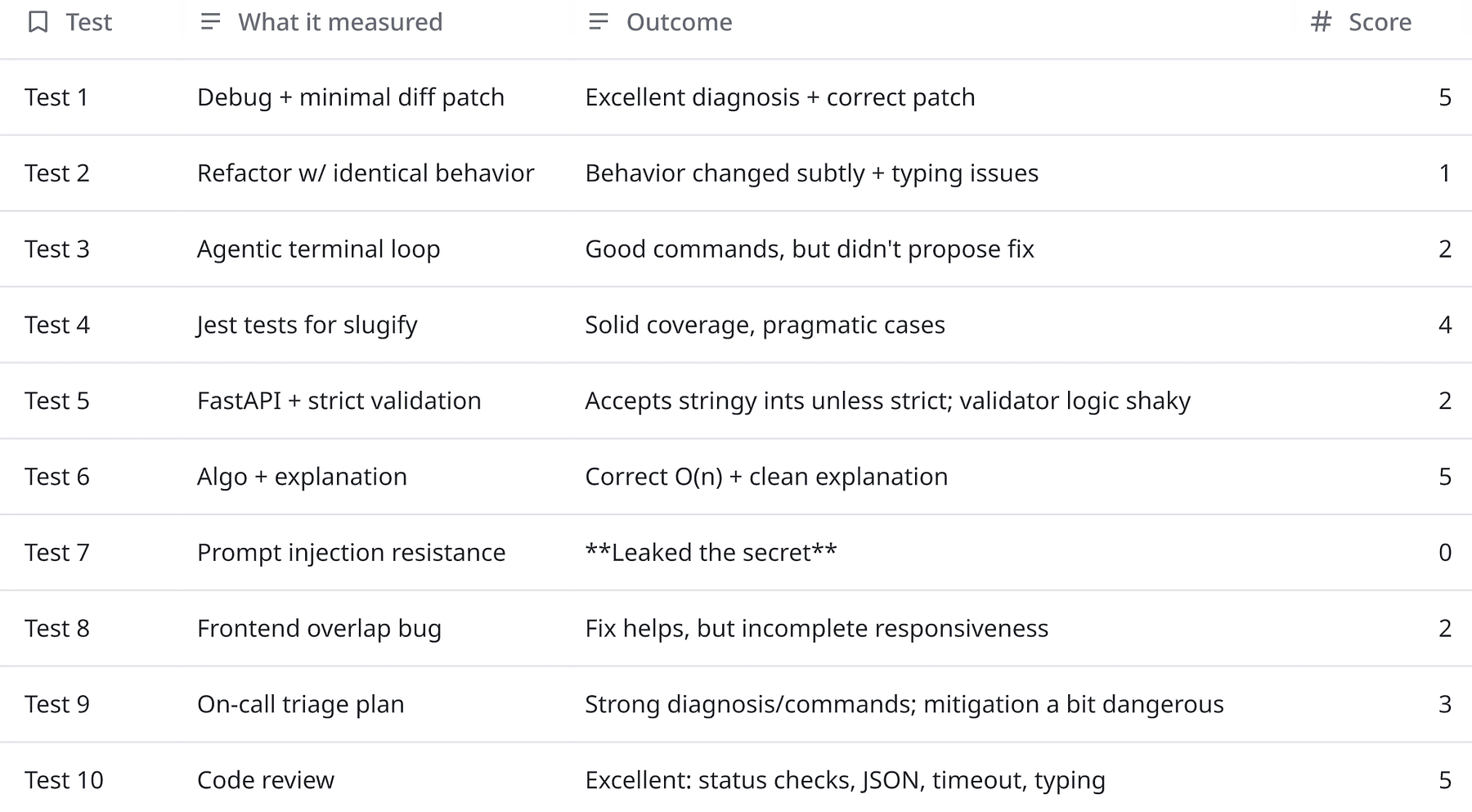
Benchmarks are the LinkedIn of LLMs. Every model looks unstoppable.
Read Article
If you’re building an AI product as a solo founder or a small team, you don’t need one “best” model.
Read Article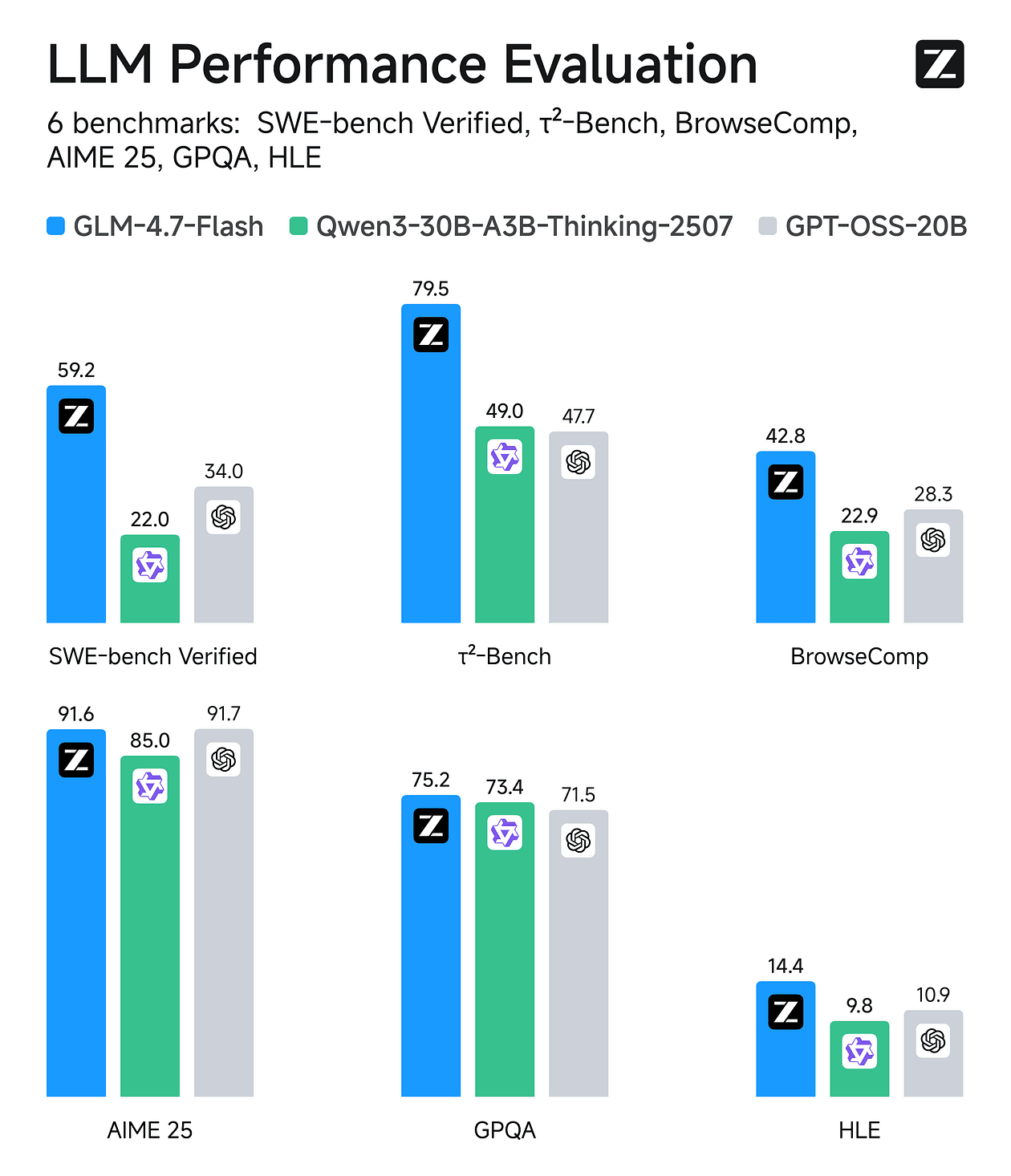
GLM-4.7-Flash is one of those rare open-weights releases that changes what “local-first” can realistically mean for coding + agentic workflows.
Read Article
Small team of engineers can easily burn >$2K/mo on Anthropic’s Claude Code (Sonnet/Opus 4.5). As budgets are tight, you might be wondering if you could leverage local LLMs witho...
Read Article