TL;DR
Effort: 12 min- Most agent forgetfulness is memory architecture failure, not model randomness.
- Fix harness-level memory first: flush checkpoints, working-set control, hybrid retrieval, and session indexing.
- When harness tuning stops being enough, choose your substrate deliberately: QMD, Mem0, Cognee, Obsidian.
- - OpenClaw installed
- - Multi-step workflows where state continuity matters
- - Willingness to treat memory as a production system
- - Diagnose missed writes vs missed retrieval vs compaction loss.
- - Know which architectural change to make first.
If your agent has ever ignored a decision you know you already made, it is usually not random.
It is your memory system.
We were mid-migration with one hard rule: after cutover, do not write to the old table. We agreed explicitly, and the next day the agent generated code that wrote to both old and new tables "just to be safe."
If you are building multi-step workflows, cutovers, runbooks, incident response, multi-day projects, this failure mode is the default unless you engineer around it.

Memory behavior in production is mostly a systems problem: write path, read path, and compaction policy.
Memory is now more important than ever
I recently wrote about persistent memory for Claude Code:
Persistent Memory for Claude Code: Never Lose Context Setup Guide
We are now talking about multi-day horizon tasks, specialist agents, and a chief-of-staff agent that keeps the plan. But there is a hard constraint that does not care how smart your model is:
- Models are stateless between calls.
- Context windows are bounded.
- Anything not made durable eventually falls out of view.
So memory becomes the difference between:
- an assistant that can execute a plan across sessions,
- and a confident autocomplete engine with amnesia.
Treat memory as read/write/GC system
In practice, memory behaves like three subsystems:
What gets extracted and persisted, and exactly when.
How relevant state gets retrieved and injected into active context.
What gets summarized, pruned, or dropped under token pressure.
Whether you can inspect what was saved, retrieved, and ignored.
OpenClaw's default posture is usually painful for real systems:
- writes are discretionary,
- reads are optional,
- compaction gets aggressive under limits.
Memory SLOs
A useful framing is to define three service-level objectives:
- Durability: important decisions and constraints survive sessions.
- Retrievability: relevant facts get surfaced when needed.
- Compaction stability: long sessions do not silently erase critical state.
Harness-level fixes (before substrate changes)
1) Add checkpoint before compaction (memory flush)
{
"compaction": {
"memoryFlush": {
"enabled": true,
"softThresholdTokens": 32000,
"prompt": "Write a durable session note to memory/YYYY-MM-DD.md. Capture: decisions, constraints, open questions, owners, and any state that would break the plan if forgotten. If nothing meaningful happened, write NO_FLUSH.",
"systemPrompt": "Be terse. Prefer bullet points. Do not rewrite the conversation."
}
}
}Why this works:
- decisions and constraints are what break systems when lost,
- owners matter for multi-agent coordination,
- open questions prevent repeated loops.
Trade-off: extra tokens and latency. If flush prompts are sloppy, retrieval becomes noisy.
2) Control working set with TTL pruning
{
"contextPruning": {
"mode": "cache-ttl",
"ttl": "4h",
"keepLastAssistants": 4
}
}TTL pruning helps interactive coherence and cost, but it is cache policy, not durable memory policy.
3) Use hybrid retrieval for real engineering queries
{
"memorySearch": {
"enabled": true,
"sources": ["memory", "sessions"],
"query": {
"hybrid": {
"enabled": true,
"vectorWeight": 0.6,
"textWeight": 0.4
}
}
}
}If your corpus contains identifiers (HTTP status codes, service names, ticket IDs), lexical weight usually needs to be higher than expected.
4) Index sessions so "last week" is queryable
{
"memorySearch": {
"sources": ["memory", "sessions"]
},
"experimental": {
"sessionMemory": true
}
}Session indexing improves coverage but adds noise. That is why flush quality matters more once session indexing is enabled.
Common memory failure modes
Missed persistence
highTrigger: No checkpoint write before compaction
Detection: Critical constraint appears in chat but absent in memory files
Mitigation: Enforce pre-compaction flush with typed durable notes
Missed retrieval
highTrigger: Semantic-only retrieval misses exact identifiers
Detection: Agent ignores known IDs/policies despite existing notes
Mitigation: Hybrid retrieval + corpus-specific weighting
Compaction loss
mediumTrigger: Long sessions summarized without state guarantees
Detection: Policy drift after long runs
Mitigation: Checkpoint SLO + concise, typed memory entries
Memory contract (non-optional)
If you want memory to behave, define an explicit contract:
- Checkpoint: before compaction, persist decisions/constraints/state.
- Ground truth: separate durable memory from transient chat.
- Retrieval policy: define when the agent must search.
- Noise control: type stored notes (decision vs preference vs task).
- Observability: log what was stored and what was retrieved.
When harness tuning is no longer enough
Signs you need real memory infrastructure:
- multi-day projects,
- multiple agents with coordination overhead,
- knowledge base beyond a handful of markdown files,
- provenance requirements (where memory came from, when, why).
Memory substrate selection
| Option | Retrieval quality(w:3) | Persistence guarantees(w:3) | Relationship reasoning(w:2) | Operational complexity(w:2) | Weighted score |
|---|---|---|---|---|---|
| QMD | 5 | 3 | 2 | 3 | 68% Best when retrieval quality is your main bottleneck. |
| Mem0 | 4 | 5 | 2 | 3 | 74% Best when missed writes and compaction loss are primary failures. |
| Cognee | 4 | 4 | 5 | 2 | 76% Best when relationship queries are first-class requirements. |
| Obsidian + curation | 3 | 4 | 3 | 4 | 70% Best when human governance and editable knowledge are priority. |
QMD: retrieval as a first-class service
If you set memory.backend = "qmd", you replace built-in indexing with a local-first sidecar combining lexical + vectors + reranking.
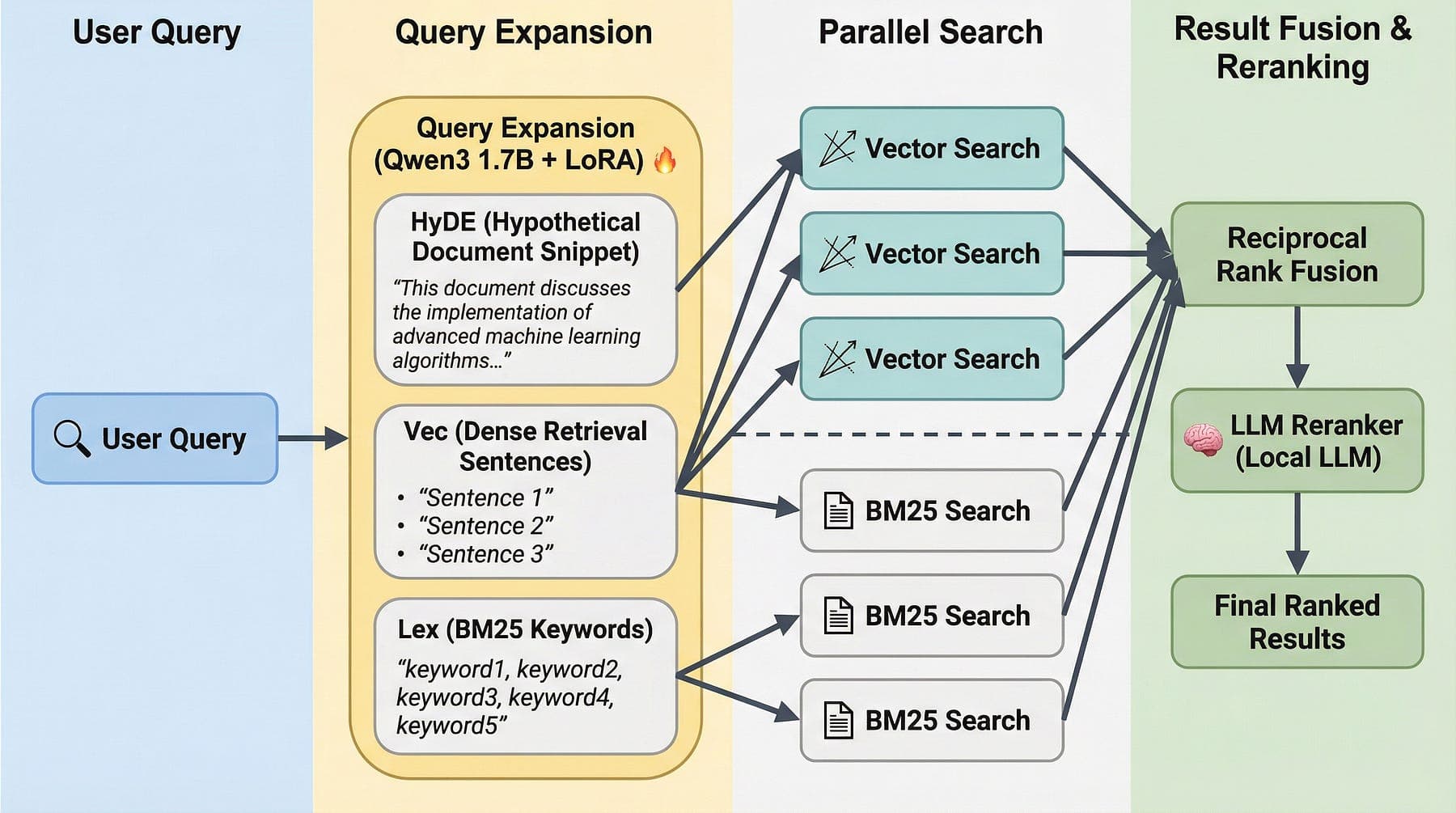
QMD quickstart
npm install -g @tobilu/qmd
qmd collection add ~/notes --name notes
qmd collection add ~/Documents/meetings --name meetings
qmd context add qmd://notes "Personal notes and ideas"
qmd context add qmd://meetings "Meeting transcripts"
qmd embed
qmd query "quarterly planning process"- - Treat QMD sidecar as a production service: health checks, versioning, backups.
- - Context trees in QMD materially improve retrieval selection quality.
Mem0: system-owned memory, not model discretion
Mem0 changes write path and compaction resilience by auto-capturing and auto-recalling memory outside context windows.
from openai import OpenAI
from mem0 import Memory
openai_client = OpenAI()
memory = Memory()
def chat_with_memories(message: str, user_id: str = "default_user") -> str:
relevant_memories = memory.search(query=message, user_id=user_id, limit=3)
memories_str = "\n".join(f"- {entry['memory']}" for entry in relevant_memories["results"])
system_prompt = f"You are a helpful AI. Answer based on query and memories.\nUser Memories:\n{memories_str}"
messages = [{"role": "system", "content": system_prompt}, {"role": "user", "content": message}]
response = openai_client.chat.completions.create(
model="gpt-4.1-nano-2025-04-14",
messages=messages,
)
assistant_response = response.choices[0].message.content
messages.append({"role": "assistant", "content": assistant_response})
memory.add(messages, user_id=user_id)
return assistant_responseTrade-offs to evaluate explicitly:
- external dependency uptime,
- privacy/retention/deletion policy,
- per-operation cost at scale.
Cognee: when chunks are not enough
Cognee shifts representation toward graph-aware memory.

import asyncio
import cognee
async def main():
await cognee.add("Cognee turns documents into AI memory.")
await cognee.cognify()
await cognee.memify()
results = await cognee.search("What does Cognee do?")
for result in results:
print(result)
if __name__ == "__main__":
asyncio.run(main())Use graph-backed memory when relationship queries matter: ownership, dependencies, hierarchy, and cross-agent responsibility.
Obsidian: human-in-the-loop governance layer
Obsidian is useful because humans can curate what the agent considers true.

Two practical patterns:
- symlink memory folder into an Obsidian vault for review/edit,
- index vault via retrieval backend for curated search.
That creates a governance loop:
- agent writes memory,
- human curates memory,
- retrieval prioritizes curated store,
- behavior quality improves.
Multi-agent memory design (org-chart style)
Layered memory topology for agent teams
- - Shared memory without boundaries causes cross-contamination.
- - Private-only memory without canonical docs causes drift.
- Canonical policy updated once
- All agents retrieve canonical policy before execution
- Coordinator detects and corrects policy drift
Closing recommendations
Start in this order:
Launch checklist
0/6Then ask hard questions:
- What is source of truth when memory conflicts with current chat?
- How do we test memory behavior over long runs without anecdotes?
- What must be deterministic (policy) vs learned (what to remember)?
- How do we prevent memory from becoming a junk drawer?
If you have already shipped an agent system, your scars likely fall into one of three buckets: missed persistence, missed retrieval, or compaction loss.
Which one was yours?