Agentic SaaS Playbook 2026
1. Introduction
Pocket guide for shipping agentic SaaS products
If you're looking for a specific playbook, additional research, or hands-on support building your product, you can write me at agentnativedev (at) gmail (dot) com.
For a long time, I was looking for serious resources on building agentic products, resources for people who actually want to ship products that work and loved by users. I paid for courses, books, communities, and programs hoping one of them would go deep enough.
A lot of courses, books or content show you a clever workflow, maybe a framework, and then quietly skip the hard parts: identity, permissions, billing, retries, monitoring, data ownership, and the boring realities of operating software for customers.
And that gap is where most of the real work lives.
Users will stress-test your edge cases, your costs, your uptime, and your trust boundaries, and they will hold you accountable.
That's the part I needed help with when I started.
That's the part I couldn’t find.
So that's the book I wrote.
If you follow the sections at your own pace and build alongside the repository, you'll understand what it takes to design, implement, and operate a SaaS product with agentic capabilities.
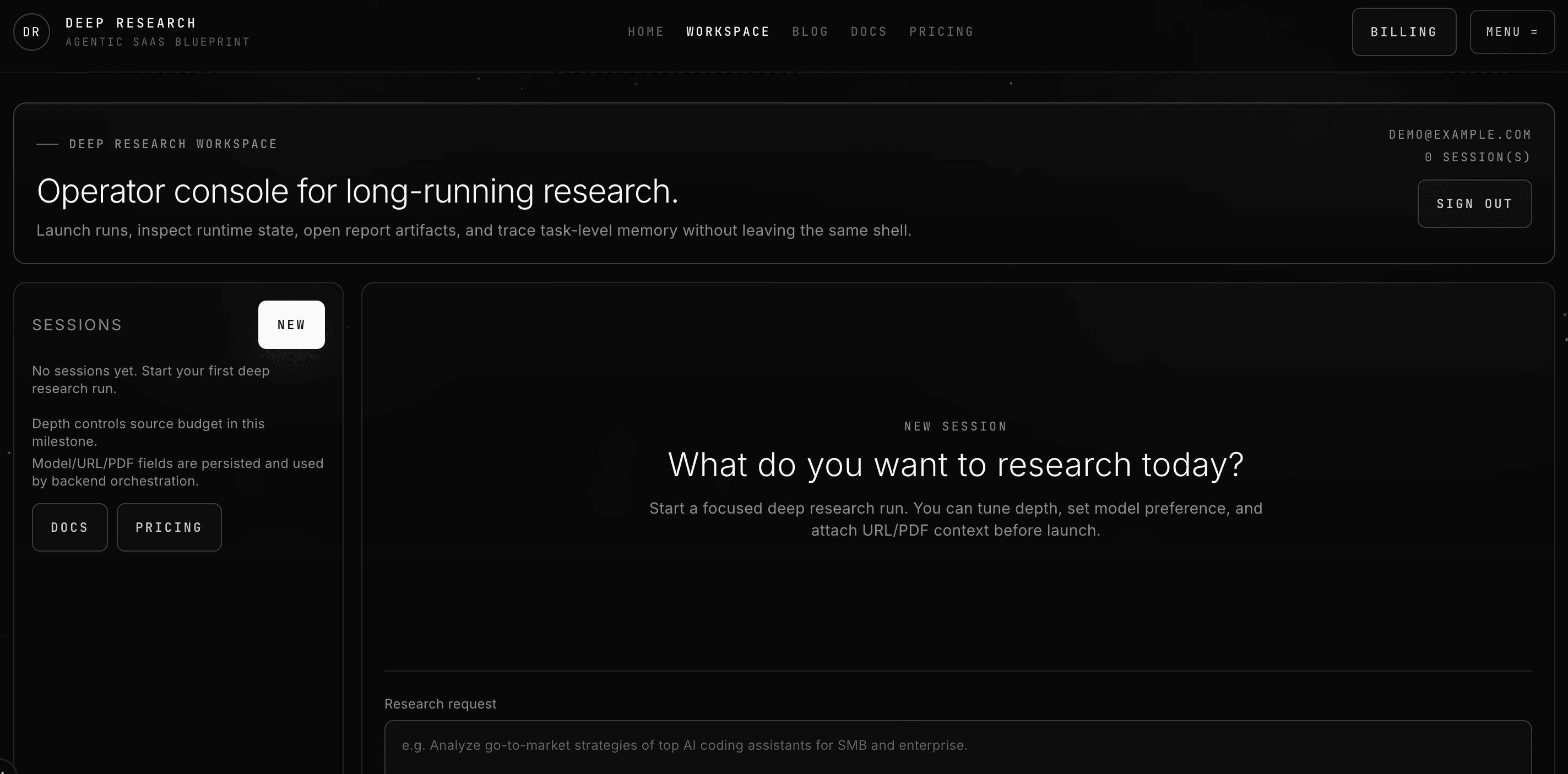
You'll build a Deep Research Agent that runs inside a real SaaS product: a public landing page, SEO optimized blog, a protected workspace, billing, recurring automation, and a backend that enforces identity and ownership, something you can actually put in front of customers.
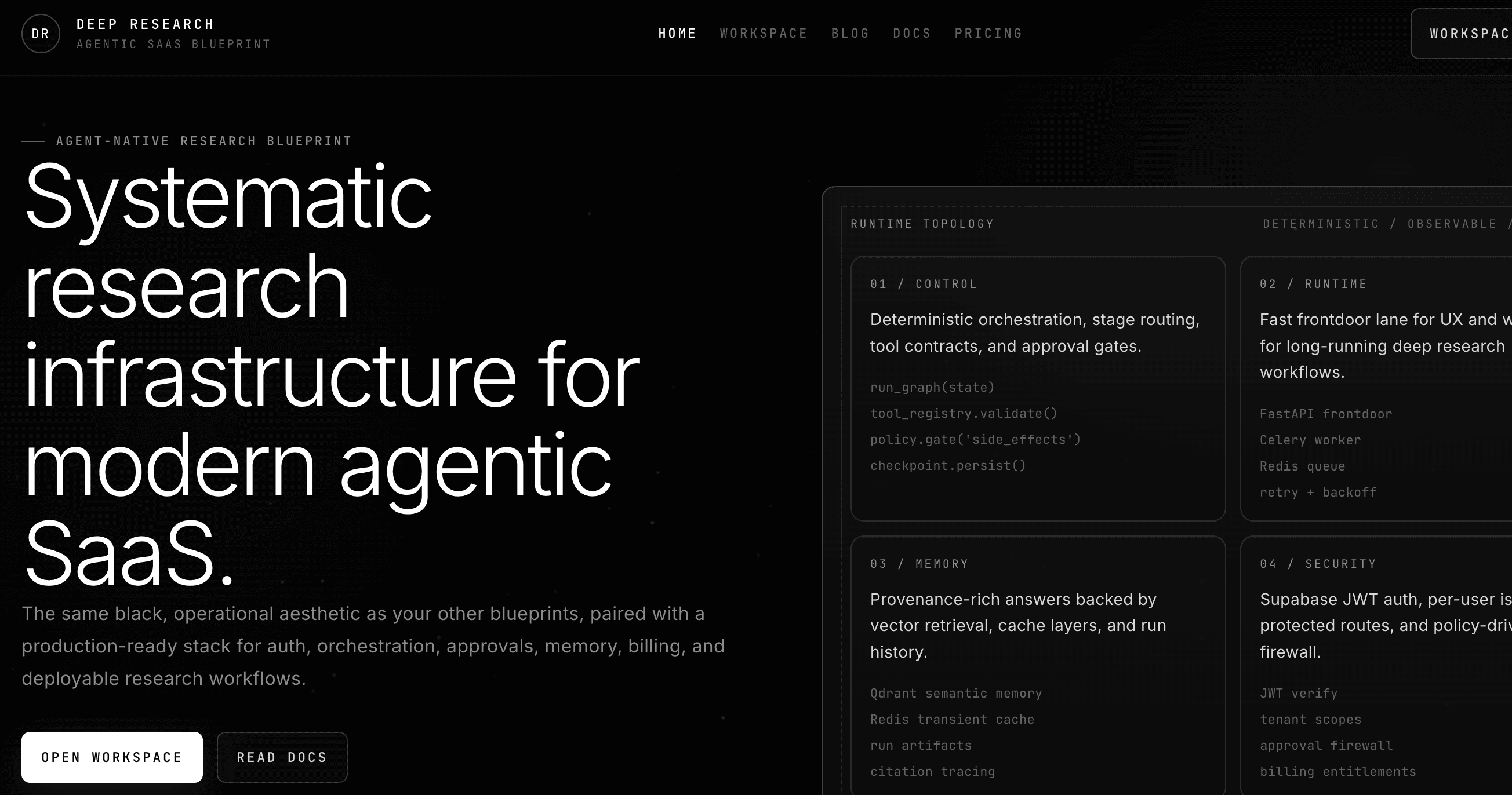
Throughout the book, I'll use planes as a practical way to reason about the system: UX, orchestration, runtime, memory, data, integrations, security, and observability.
Each plane is where specific failure modes show up, and where specific investments pay off.
Here's what you'll end up with:
- A public SaaS surface (landing, docs, pricing) that transitions cleanly into a protected workspace.
- A protected product area where users launch runs, approve steps, ask follow-ups, and download reports.
- A full run lifecycle: search → collect sources → summarize → approval gates → memory indexing → PDF report.
- Monitors that schedule recurring research runs like a lightweight operations layer.
- Stripe-based entitlement gating so runtime access is enforced server-side, not just in the UI.
- A mock vs live mode switch so you can demo and test fast without breaking production contracts.
This book, and the assets that come with it are for people building a product that works, that people trust and that lasts.
I hope you enjoy the freely available sections and deep dives. They're not light previews, they're genuinely substantial, and I put as much emphasis on them as I did on the gated sections. They're absolutely worth studying and practicing.
And if you're serious to take things a lot further, then I'd love for you to join The Agent Foundry. It's an exclusive membership for builders who want to ship products the right way, with depth and discipline. I hope to see you inside.
Continue: the Architectural Planes & the Agentic SaaS Stack
Unlock Chapters 2 and 3 — the full eight-plane architecture (UX, Control, Runtime, Memory, Data, Security, Observability) and the complete Agentic SaaS stack, with the production repo.
The Agent Foundry unlocks advanced implementation sections, architecture playbooks, production templates, and repository access.
Enter your email to continue — we'll send a one-click sign-in link and bring you back here.