Just after 9:45 a.m. Pacific on 5 February 2026, Anthropic unveiled Claude Opus 4.6, and 20 minutes later, OpenAI counter‑punched with GPT‑5.3‑Codex.
With these models, we are entering an era of digital coworkers that demand as much orchestration and project management as technical skill.
These releases represent different design philosophies. GPT‑5.3‑Codex feels like a pragmatic engineer, i.e. faster, more efficient, and happy to be steered. It shines when building and debugging code, running test suites and integrating with existing developer tools.
The ability to interact mid‑task is particularly valuable when chasing down tricky bugs or exploring design alternatives.
Claude Opus 4.6, on the other hand, feels like a thoughtful architect. Its large context window allows it to ingest whole codebases or lengthy requirement documents and maintain coherence across multiple threads of reasoning. The agent‑team paradigm invites decomposition of work into specialised roles, which is how real development teams operate.
However, the deeper reasoning comes with slower responses and higher token consumption. For simple tasks, it may appear to overthink, requiring developers to dial down its effort level.
In practice, the “winner” depends on your workload. If you need to rapidly prototype, debug and iterate with tight feedback loops, GPT‑5.3‑Codex likely offers better throughput. If your work involves analysing sprawling codebases, drafting legal documents or coordinating multi‑agent workflows, Claude Opus 4.6 provides unmatched context and autonomy.
One shot emulator with Opus 4.6
Let’s further dive deeper into the details.
I want to draw on official release notes, benchmark data and early community reactions to compare the two flagships from a software‑engineering perspective.
Simon Willison’s mandatory pelican: https://simonwillison.net/2026/Feb/5/two-new-models/
Claude Opus 4.6: 1M token context and focus on knowledge work
Opus 4.6 improves its predecessor’s coding skills by planning more carefully, sustaining long agentic tasks and working more reliably in large codebases.
The headline feature is a 1 million‑token context window (in beta), the first time an Opus‑class model has offered such capacity.
A million tokens equates to around 750 000 words of input, enough to fit several novels or the contents of a large repository into memory.

This long window is paired with context compaction, a mechanism that automatically summarises older sections of the transcript to avoid hitting limits.
Anthropic also introduces adaptive thinking and effort controls: the model dynamically decides when to do deeper reasoning and developers can choose between low, medium, high and maximum effort levels to trade off speed, cost and intelligence.
Hyper realistic simulation of an atom in Threejs
For enterprises, Opus 4.6 integrates with Excel and debuts a PowerPoint plug‑in, reflecting Anthropic’s ambition to embed AI deeply into office workflows.
On benchmarks, Opus 4.6 leads several evaluations.
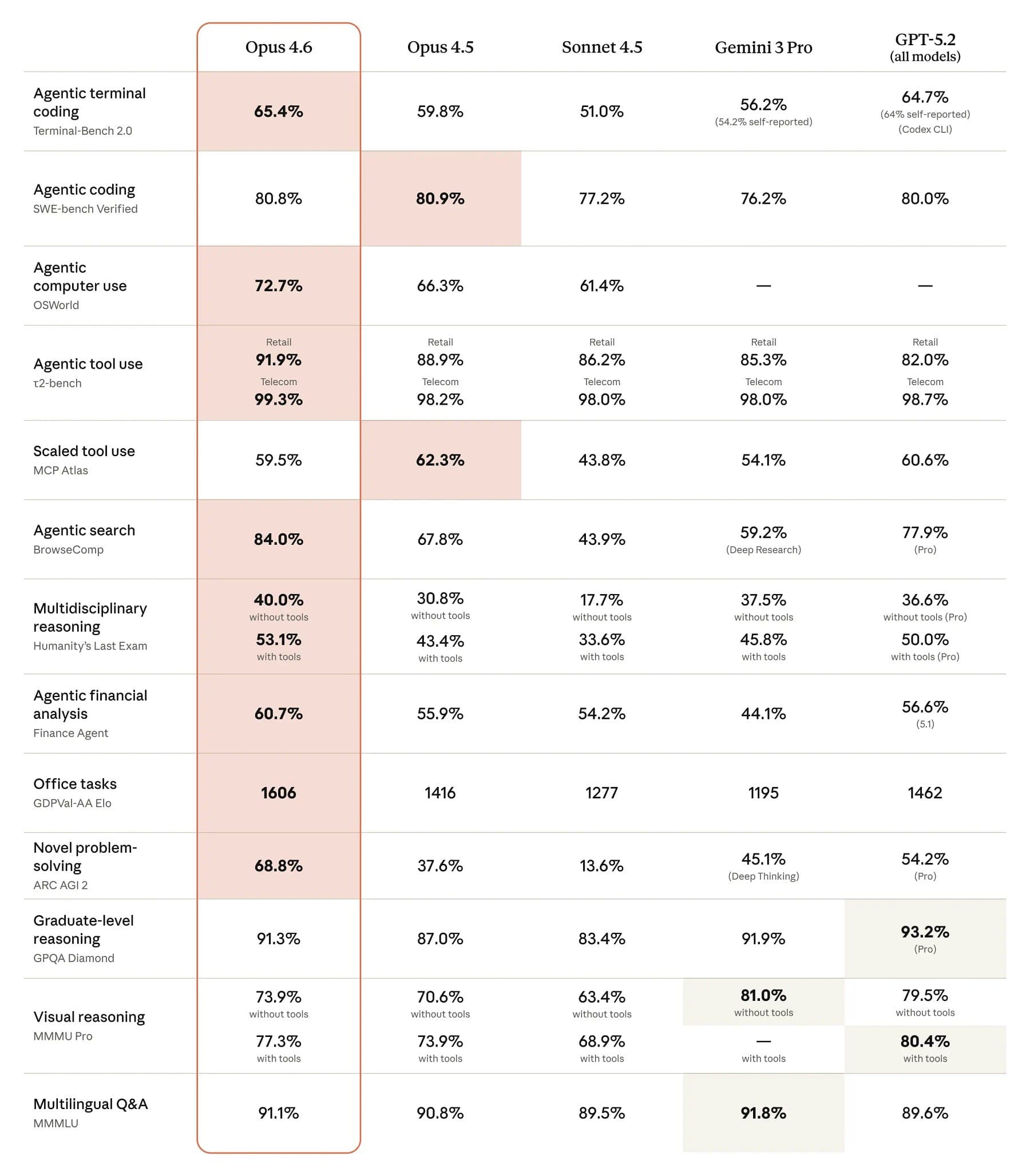
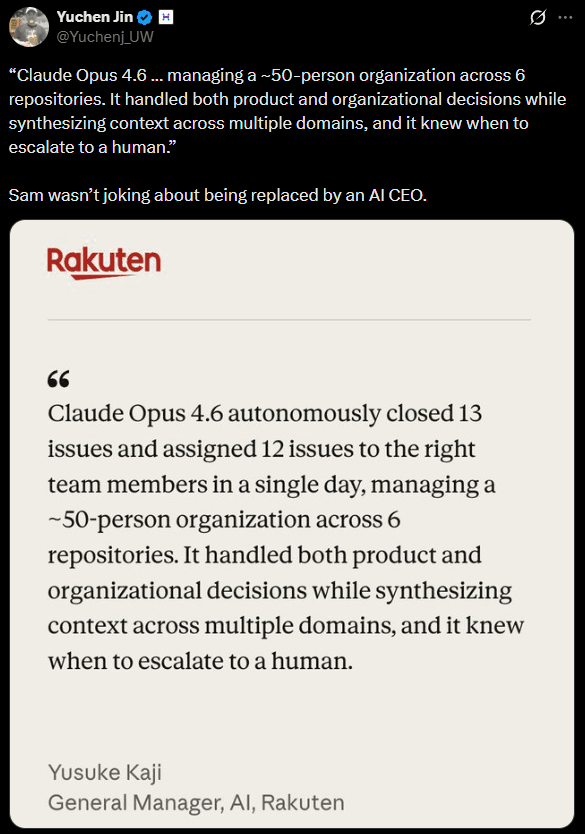
Opus 4.6 achieved the highest score on Terminal‑Bench 2.0 and leads on Humanity’s Last Exam and GDPval‑AA, an evaluation of economically valuable knowledge work.
Opus 4.6 also outperforms OpenAI’s GPT‑5.2 by about 144 ELO points on GDPval‑AA, meaning it wins roughly 70 % of head‑to‑head comparisons.
There are improvements in long‑context retrieval: Opus 4.6 scores 76 % on a needle‑in‑a‑haystack benchmark, compared with 18.5 % for the earlier Sonnet 4.5 model.

Another feature is agent teams.
Within Claude Code, you can assemble multiple AI agents that work on separate subtasks and coordinate autonomously.
This focuses on compound workflows where several agents specialise and communicate, rather than one monolithic assistant attempting everything.
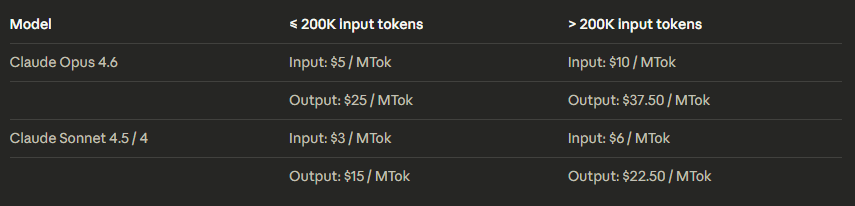
Pricing remains at $5 per million input tokens and $25 per million output tokens, though premium pricing applies for prompts exceeding 200 k tokens.
You can find further information in official announcement.
GPT‑5.3‑Codex: Faster execution and interactive coding
OpenAI positions GPT‑5.3‑Codex as the most capable agentic coding model in its lineup.
The official release notes describe it as combining the coding performance of GPT‑5.2‑Codex with the reasoning and professional knowledge of GPT‑5.2, while being 25 % faster.

Video game where demons chase you through a solarpunk environment
The model supports long‑running tasks that involve research, tool use and complex execution, and developers can “steer” its work by interacting with it mid‑task without losing context.
OpenAI notes that early versions of GPT‑5.3‑Codex were used to debug its own training, manage deployment and diagnose evaluations, making it the first model that contributed materially to its own creation.
Key improvements are:
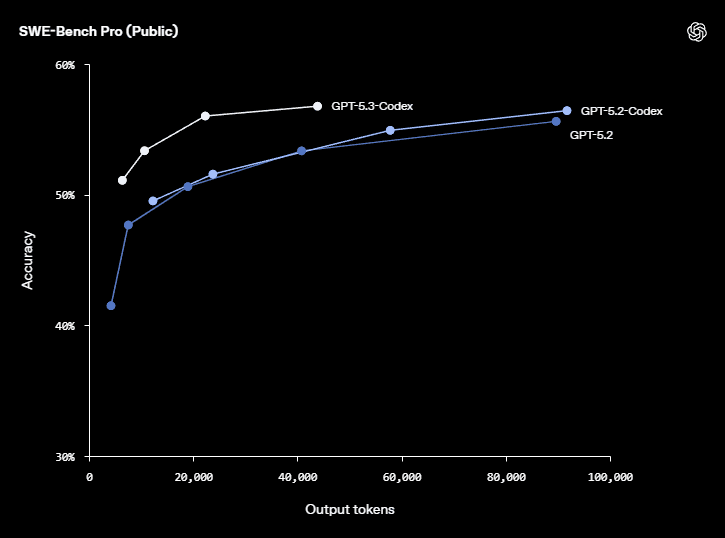
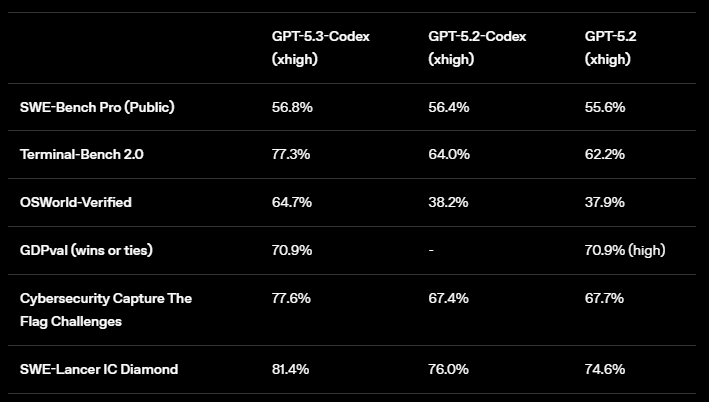
- State‑of‑the‑art scores on SWE‑Bench Pro and Terminal‑Bench 2.0
- Better performance on OSWorld‑Verified (a benchmark for desktop interactions),
- More interactive supervision in the Codex app
The app now delivers frequent updates while the model works, and users can adjust direction mid‑task (“steering”).
OpenAI also classifies GPT‑5.3‑Codex as “High capability” for cybersecurity under its Preparedness Framework and is deploying staged access with trusted‑access programs.
On the hardware side, GPT‑5.3‑Codex is co‑designed for and served on NVIDIA GB200 NVL72 systems, underscoring how compute advances enable these agentic workloads.
While OpenAI’s announcement does not specify a context length, but reports suggest a context window of roughly 400 k tokens, considerably smaller than Opus 4.6’s million tokens but still a significant increase over previous Codex versions, and still very capable.
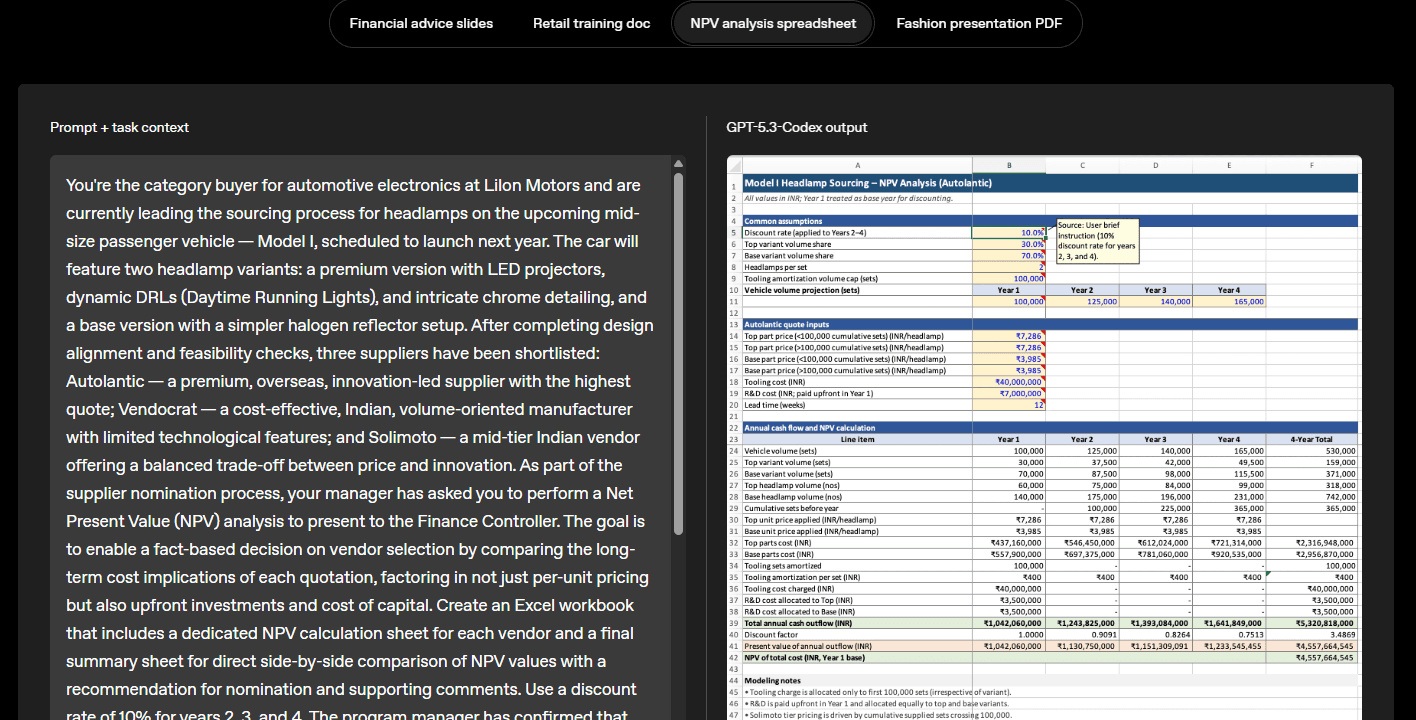
The new model requires fewer tokens for equivalent work, reducing costs for developers. GPT‑5.3‑Codex achieved 77.3 % on Terminal‑Bench 2.0 (a jump from 64 % for GPT‑5.2‑Codex) and 64.7 % on OSWorld‑Verified, indicating notable gains in both coding and general computer‑use tasks.
Personal take: Codex 5.3 vs Opus 4.6
Speed and efficiency vs. depth and breadth
The most striking trade‑off is between speed and efficiency versus context capacity and deep reasoning.
OpenAI’s GPT‑5.3‑Codex is designed to execute tasks faster and with fewer tokens.
In benchmarks, it uses 93.7 % fewer tokens than previous models for lightweight tasks and is 25 % faster overall.
This makes it attractive for real‑time coding and scenarios where cost and latency matter.
By contrast, Claude Opus 4.6 is built to think more deeply, Anthropic advises developers to dial down the effort parameter if the model appears to overthink simple tasks.
The million‑token context window allows it to keep enormous documents or codebases in memory and to answer questions without resorting to retrieval‑augmented generation.
This is powerful for research, legal work or cross‑cutting code analysis but may be overkill (and more expensive) for straightforward coding tasks.
Agentic workflows
Both models are explicitly agentic.
GPT‑5.3‑Codex can run autonomous workflows over hours or days, using tools and responding to steering.
OpenAI demonstrates this by having the model build two web games autonomously over millions of tokens, highlighting endurance and tool integration.
Users can query the model mid‑task, adjust prompts and continue seamlessly, which is invaluable during iterative software development.
Claude Opus 4.6, meanwhile, introduces agent teams, multiple agents working in parallel on different subtasks and coordinating autonomously.
This resembles a team of specialists handling frontend, backend and testing concurrently, potentially speeding up multi‑component projects.
Opus 4.6 also supports adaptive thinking and effort controls, giving developers explicit levers to trade off reasoning depth against latency or cost.
Developers who prefer granular control over the model’s cognitive budget may appreciate this flexibility.
Context window
For code synthesis, a 100 k–200 k window is often sufficient because code can be decomposed into modules and relevant snippets can be retrieved.
Larger windows increase computational cost and may introduce hallucinations if the model’s attention is spread too thin.
However, for back‑office automation, legal analysis and research, the ability to ingest entire documents or multi‑chapter briefs without retrieval is transformative.
OpenAI emphasises long, complex tasks and interactive workflows, while Anthropic positions its model as deeper‑thinking and more autonomous.
Ultimately, whether a million‑token context is overkill or a game‑changer depends on the application.
Large‑context models reduce reliance on retrieval pipelines, vector databases and chain‑of‑thought heuristics, simplifying architecture at the cost of higher compute.
Developer experience and tooling
Beyond raw model performance, the surrounding ecosystem matters.
OpenAI’s Codex app now offers more frequent status updates and allows users to steer tasks mid‑execution.
It integrates with the CLI, IDE extensions and the web, with API access promised once safety mitigations are in place.
OpenAI also launched a trusted‑access program for cybersecurity work and classifies GPT‑5.3‑Codex under a high‑capability tier.
Anthropic is investing heavily in productivity integrations. Opus 4.6 gains improved Excel support and a PowerPoint feature.
Within Claude Code, agent teams enable parallel workflows, and the API offers adaptive thinking and effort controls.
Both companies thus move toward holistic platforms rather than standalone models.
As the models continue to evolve, you should experiment with both, calibrate effort parameters and leverage the right tool for each job.