Small team of engineers can easily burn >$2K/mo on Anthropic’s Claude Code (Sonnet/Opus 4.5). As budgets are tight, you might be wondering if you could leverage local LLMs without compromising quality.
Could a weaker open model under the hood still do “almost Claude Code” for small to mid-sized developer teams?
Models like Qwen3**-Coder (32B)**, DeepSeek V3, GLM-4.7, and MiniMax M2.1 are pushing frontier levels of code understanding.
In fact, recent benchmarks show the latest Qwen and DeepSeek models rival proprietary ones, and they could be even leading coding LLMs now.
These advances suggest a small teams could get by with local LLMs, if the hardware and integration hurdles aren’t fatal.
Let’s continue.
Shortlisted OSS Models to Replace Claude Code
There’s no shortage of candidates to run in-house.
Here are some of your options
Qwen3**-Coder (32B MoE, 128K context)**
It has 235B params (22B active) and is explicitly tuned for coding and agentic tasks. Zhipu AI’s benchmarks show Qwen3 competes with (or beats) deep proprietary models like OpenAI’s GPT-4 in coding tests. Even Qwen3’s smaller versions (14B, 8B) offer strong coding support on much lighter hardware.
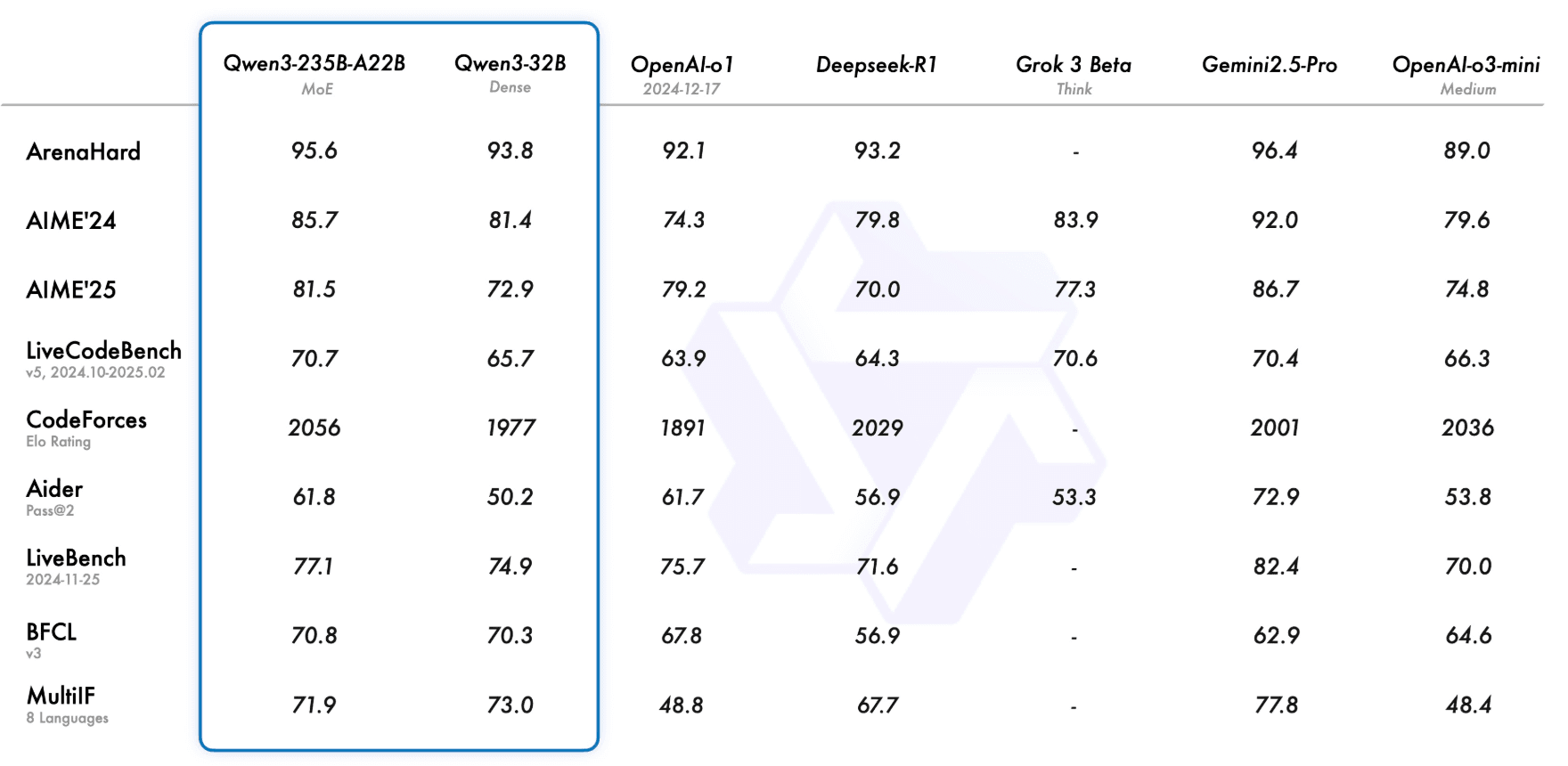
https://qwenlm.github.io/blog/qwen3/
DeepSeek V3/Coder
The V3 “Terminus” family is strong at math/reasoning and code, though official weights aren’t fully open yet. (DeepSeek’s R1 671B was quantized across 6×A100 GPUs, ~$100K hardware.)
Unofficial reports suggest DeepSeek’s coder models are powerful but similarly require a serious G****PU cluster.
Even quantized, DeepSeek-V3.2 needs 350–400+ GB of VRAM (multi-GPU) for inference.
DeepSeek class models are data-center scale and could be beyond a typical team’s setup, but definitely a must-try if you have the infra at hand.
GLM-4.7
GLM-4.7 delivers major math/reasoning boosts over its predecessor, and they even call it a “Claude-level coding model at a fraction of the cost”.
GLM-4.7 weights are open (on HuggingFace/ModelScope) and it can be served with frameworks like vLLM or SGLang.
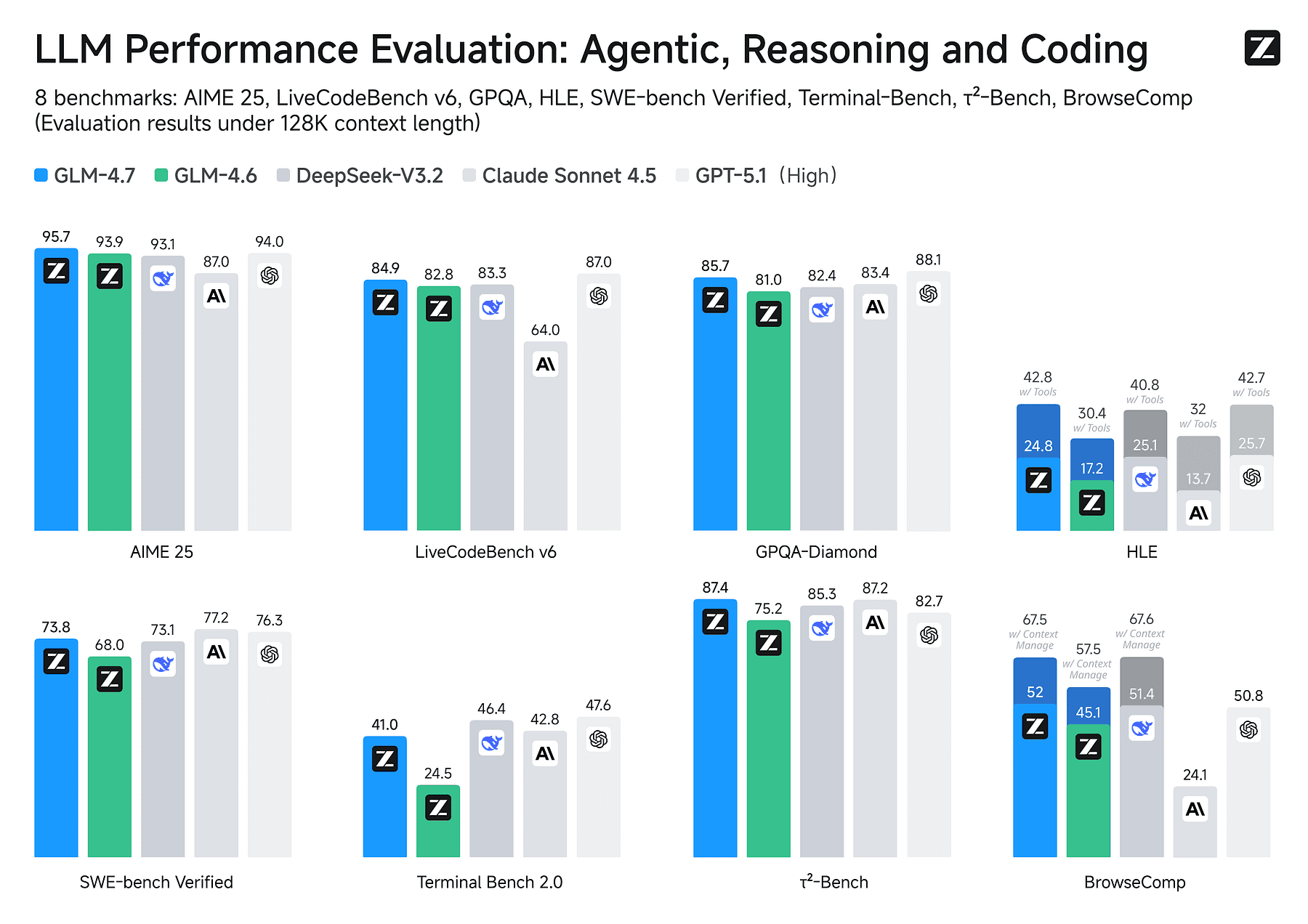
In head-to-head benchmarks, GLM-4.7 actually holds its own, and also in practice, GLM-4.7 works well for many coding queries, and it runs on far lighter hardware than full Sonnet.

GLM-4.7 Interleaved Thinking
MiniMax M2.1 (230B MoE)
A newcomer from the MiniMax team (Dec 2025), M2.1 is a Mixture-of-Experts model with 10B active/230B total parameters, explicitly designed for coding agents and tool use.
The team confirmed the model weights are fully open-source.
We haven’t tested it yet, but it promises “top-tier coding performance without closed APIs” and fast inference (MoE means only parts of the network activate per request).
If M2.1 lives up to its hype, it could be a game-changer, but even running it will require multiple GPUs (10B active weights still need >80GB of VRAM).
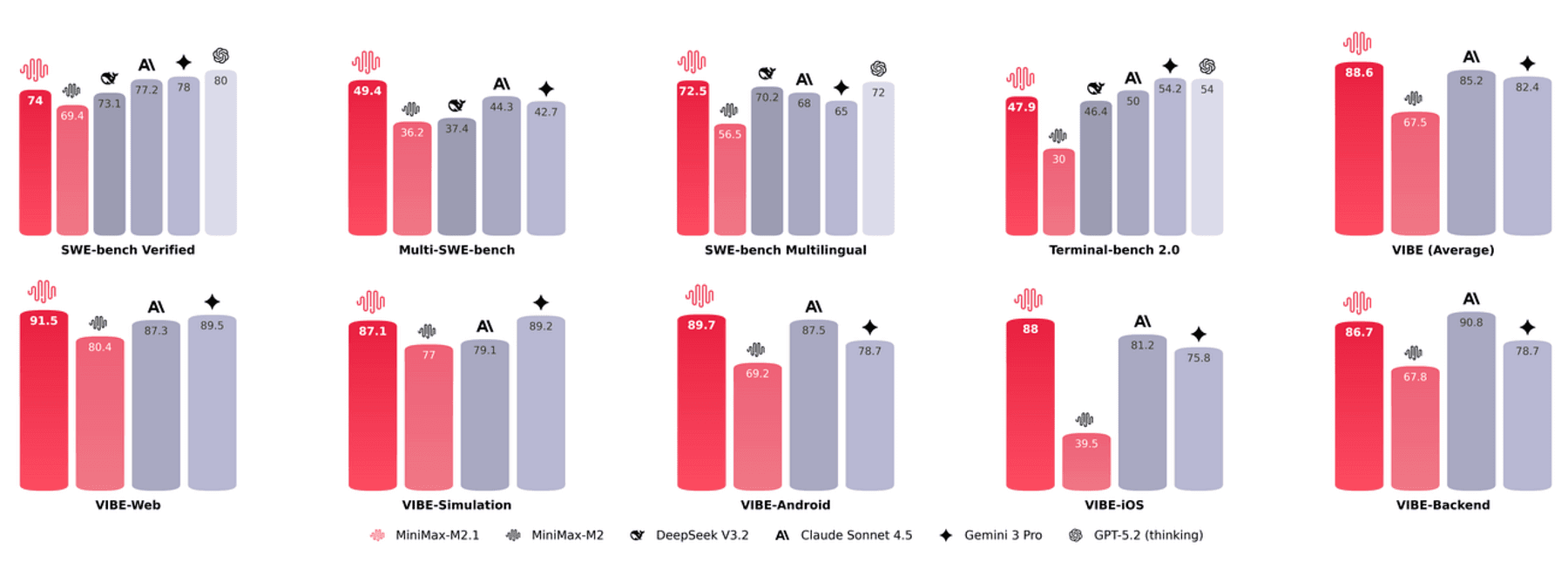
https://www.minimax.io/news/minimax-m21
Smaller Models
Beyond the giants, there are efficient coders:
- Qwen 14B/8B
- GPT-OSS 120B
- Llama-4 variants
These run on a single GPU (8–24GB VRAM) and are quite competent for simpler tasks.
Qwen3–14B gets ~58% on GitHub issues, and running Qwen 14B on one RTX 4090 (24GB) at Q4 quantization is smooth for routine coding suggestions.
These smaller models won’t match Opus/Sonnet for novel complex problems, but they dramatically widen feasibility as $1–2K GPU can serve one developer.
Hardware and Performance Reality
As mentioned, DeepSeek-V3.2 (685B MoE), even quantized to 4-bit, needs 350–400+ GB of GPU RAM, meaning an 8×A100/H100 cluster. (Full precision would exceed 1 TB!).
In other words, DeepSeek’s top models are pure data-center territory.
By contrast, the open models above vary from a few GB to a few dozen.
The Qwen3–32B model needs ~24GB VRAM (16GB if 4-bit quant), which fits on one high-end desktop card (e.g. RTX 6000/4090) if quantized.
Qwen3–14B needs ~12GB (8GB Q4 quant).
GLM-4.7 is comparable in size (reportedly 2.5T tokens but weight size similar to 28–32B range) and you can run it on a 48GB H100 (one card) with ease.
MiniMax M2.1’s active 10B would need at least 80GB of GPU memory (10B×8 bytes + overhead), so that’s a 2× H100-level job.
In practice, a small team can build a modest inference rig: 2×48GB GPUs, 256GB RAM, using vLLM for serving.
You can load Qwen3–32B (quant 16-bit) and GLM-4.7 simultaneously and support a few concurrent devs.
You can process thousands of input tokens per second of throughput once models were warm (vLLM’s batch & KV-cache helped).
For perspective, a single 48GB card can churn out ~10K tokens/s of “context prefill”.
Typical coding prompts (~500 tokens) can be completed in 0.5–1 second. (Slower than cloud APIs, but acceptable on LAN.)
Naturally, more concurrency means more GPUs.
You can split load across 2 cards; each dev’s Claude CLI session gets routed to whichever GPU is free.
You can also experiment with Nvidia MIG partitions to pack multiple smaller models onto one card for light-weight tasks (Minimax M2.1 has multi-GPU support, GLM-4.7 too).
It’s not zero overhead and sometimes vLLM would stall waiting for the GPUs to swap cached contexts.
But as hardware gets cheaper, one can parallelize easily (8×4090 setups are ~$30K, and will only drop in price).
Integrating with Claude Code (and Alternatives)
Claude Code CLI honors an environment variable for model names. You can set CLAUDE_MODEL=glm-4.7 (or similar) in the CLI config.
You can also use open-source agent frameworks. Projects like OpenCode, Roo Code, or Cline let you plug in any LLM backend.
You can plug your local Qwen or MiniMax model into a Claude-like CLI interface.
One advantage of staying within Claude Code’s ecosystem is that the agentic prompt engineering is very mature. The quality of output isn’t just the model but it’s the system prompt, the conversation formatting, the retrieval of code context.
By reusing Claude’s templates, you can get decent results even from smaller models.
Result
Small dev teams can replace most of Claude Code’s function with a local models but only if you treat it as proper infrastructure.
Do not have each dev run a different model on their laptop. Instead, serve one consistent model behind the same Claude Code CLI (or an equivalent agent).
That way, all devs see the same behavior, and you can tweak prompts globally.
This can give you very similar outputs for day-to-day coding: code completion, bug fixes, PR summaries, etc.
In summary, nothing stops this train.