Conversational interface framing is too small to describe agentic products.
Because the quality of agentic products entirely depends on the infrastructure around that interface.
The LLM is often being asked to operate inside a half-built product with no durable memory, no recovery path, no tool boundary, no cost discipline, and no idea what happened five steps ago.
The real product is a loop:
- Understand what the user wants.
- Retrieve the right context.
- Choose a plan.
- Call tools.
- Observe what happened.
- Recover when the world disagrees.
- Learn enough to do better next time.
This loop needs infrastructure and your agentic stack should allow you to build it with a set of layers that make that loop reliable enough to deliver at every user interaction.
Let's have a look at 7 layers to build truly great products.
- Frameworks: Pick the runtime first
- Models: Stop sending everything to the smartest brain
- Memory: RAG is the floor
- Ingestion: The most underrated layer
- Tools: Treat every tool call like a production API
- Durable Execution: Pay for each step once
- Observability: Logs are not enough
Finally, I will share the default stack I would start with and present options for scale.
Let's dive in.
We cover a lot more in our Agentic SaaS Playbook, and we go further inside The Agent Foundry on framework comparisons, model routing, memory architecture, ingestion pipelines, MCP tool safety, observability, deployment, and implementation checklists.
The stack has split but your team hasn't caught up
Traditional SaaS stacks became boring in a good way.
Postgres, React, object storage, queues, auth, billing, observability. You can still make bad choices, but the shape is stable.
Agentic stack is less settled because the model is an active participant in the control flow.
That changes the stack and now you need layers for:
- Framework and orchestration
- Model integration and routing
- Memory and retrieval
- Data ingestion
- Tools and integrations
- Durable execution and observability
- Infrastructure, isolation, and cost controls
The mistake that I see often is treating these as optional add-ons whereas they are the actual product boundaries.
If your agent cannot remember, retrieve, call tools safely, resume after failure, explain what it did, and keep costs inside a margin envelope, you just have a demo that invoices your API key.
1. Frameworks: Pick the runtime first
The first stack decision is "what owns the loop?"
An agent framework gives you the control structure for planning, tool calls, state, retries, handoffs, and intermediate steps.
You can write that loop yourself, but most teams should not start there.
Hand-rolled loops are fun until you need human approval, partial retries, tool-call validation, branch recovery, memory injection, and traces across 14 steps.
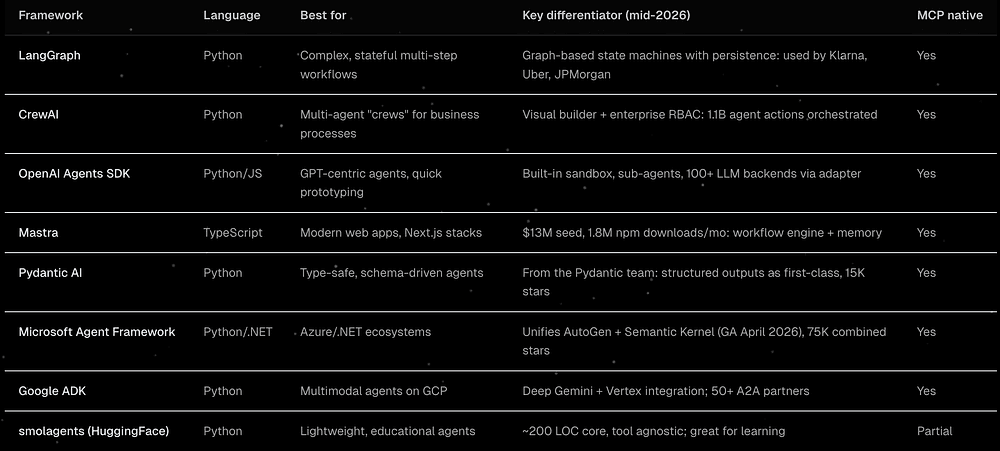
For example, a practical choice may look like this:
- LangGraph when the workflow is stateful, branching, and must resume cleanly.
- Mastra when you are a TypeScript or Next.js team and want agent logic close to the product surface.
- Pydantic AI when schemas, typed outputs, and correctness matter more.
- OpenAI Agents SDK when you are building around OpenAI primitives and want the shortest path to a working agent.
- Microsoft Agent Framework when Azure, .NET, and enterprise integration are already the center of gravity.
The important part is picking one execution model and staying consistent, because every framework has its own idea of state, tools, memory, traces, and recovery.
2. Models: Stop sending everything to the smartest brain
Model selection is now cost architecture.
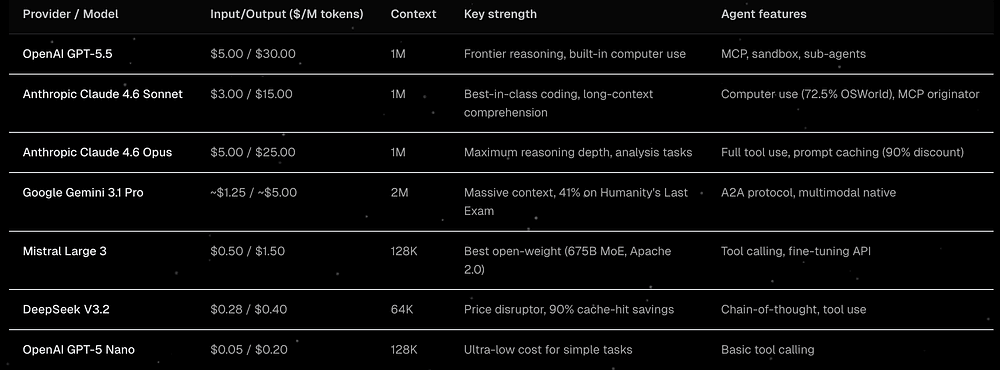
The spread between cheap routing models and frontier reasoning models is enormous (e.g., Opus vs DeepSeek).
If every request goes to the strongest model, your margins are worse than they need to be.
The default production pattern should be cascade routing:
cheap model -> standard model -> frontier model
Use the cheapest model that can plausibly do the job, then escalate when the task is complex, high-risk, or low-confidence.
A simple version looks like this:
type TaskTier = "route" | "standard" | "frontier";
function chooseModel(input: {
taskType: string;
risk: "low" | "medium" | "high";
requiresLongContext: boolean;
userPlan: "free" | "pro" | "enterprise";
}): TaskTier {
if (input.risk === "high") return "frontier";
if (input.requiresLongContext) return "standard";
if (input.taskType === "classify" || input.taskType === "extract") return "route";
if (input.userPlan === "enterprise") return "standard";
return "route";
}That is not a perfect router but a good first router because it forces the product to admit that not all requests deserve the same model.
Then add caching:
- Provider prompt caching for repeated system prompts and long static context.
- Semantic caching for repeated or near-duplicate user requests.
- Edge caching for identical public responses and bursty traffic.

The order matters here and routing and caching should arrive before fine-tuning. They are easier to ship, easier to measure, and usually more important for gross margin.
Once you get familiar with your task space and become comfortable with the idea of model routing, you can try more advanced alternatives such as vLLM Semantic Router v0.2 Athena.
3. Memory: RAG is the floor
Agents need memory because customers expect continuity.
They expect the product to remember their company, their data, their preferences, their workflows, their last run, and the exception they already explained three times.
Basic RAG gives you document recall which is useful, but it is not the whole memory layer.
A real memory system has several kinds of state:
- Conversation state: what is happening in this session.
- User memory: preferences, constraints, recurring facts.
- Workspace memory: team conventions, documents, entities, decisions.
- Task memory: what happened during a run and why.
- System memory: evaluations, failures, regressions, cost patterns.
For most early products, Postgres plus pgvector is the right default.
It keeps relational data, metadata, permissions, and embeddings in one operational system, and you also avoid dual-write bugs between your app database and a separate vector database.
Move to a dedicated vector system when you have a real scale or retrieval-quality reason, not because your architecture diagram wants another logo.
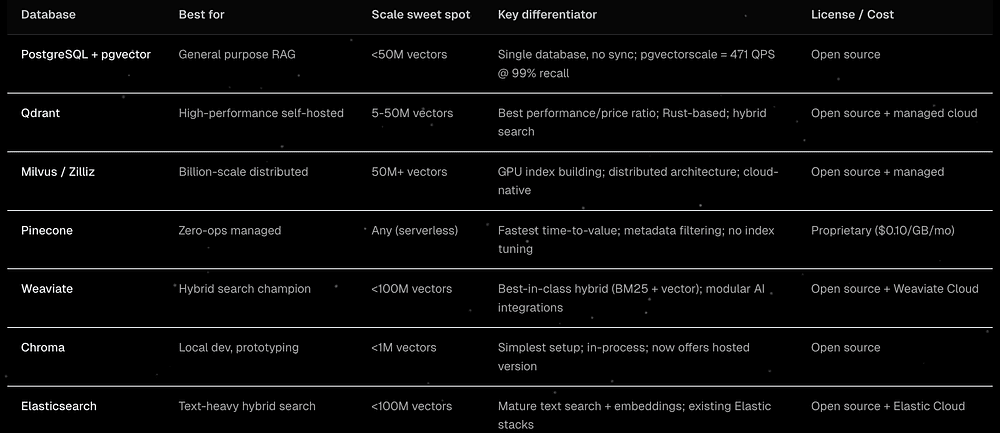
The retrieval pattern should also mature:
query -> rewrite -> retrieve -> rerank -> compress -> answer -> cite
The strong version decides what to search, reranks the candidates, compresses context, cites sources, and records what was useful.
As models grow their context size, you can also convert some of your workloads to leverage long-context instead of building a RAG layer.
Once you reach the RAG or long-context milestone, you will find yourself building a memory layer, which is entirely another topic on its own.
Conversational memory has evolved far beyond appending the last N messages to a prompt.
Modern agent memory systems provide long-term storage that persists across sessions, with semantic retrieval and structured knowledge extraction.

For most SaaS products, the pragmatic memory architecture combines three layers: (1) a conversation buffer for the current session (last N messages), (2) a vector memory store for long-term retrieval of facts and documents, and (3) a structured knowledge graph for entity relationships and temporal queries. Start with layers 1 and 2; add layer 3 only when you see the bot "forgetting" important details across sessions.
4. Ingestion: The most underrated layer
Bad ingestion creates bad agents.
It does not matter how good your model is if the PDF parser drops tables, the CSV pipeline loses column semantics, the website crawler captures navigation junk, or the sync job embeds stale data without lineage.
Ingestion should answer five questions:
- Where did this information come from?
- Who is allowed to see it?
- When was it last synced?
- What transformations were applied?
- Can we delete or re-index it cleanly?
That means the ingestion stack needs more than "upload file, split chunks, embed."
You need connectors, parsers, chunking strategy, PII handling, lineage, retries, and incremental sync.

The practical default:
- Use robust document parsers for PDFs, tables, slides, and scanned files.
- Store source metadata and permissions beside every chunk.
- Redact or classify sensitive data before embedding.
- Keep a lineage trail from source document to chunk to embedding to answer.
- Re-index incrementally instead of rebuilding everything on every update.
Most agent quality problems that look like "the model hallucinated" are actually ingestion problems wearing a model costume.
5. Tools: Treat every tool call like a production API
Tool use is where agents leave the text world and touch reality.
That makes it the highest-risk part of the stack.
A tool is not just a function. It is a contract:
- What inputs are valid?
- What permissions are required?
- What side effects can happen?
- What happens on timeout?
- Can the action be retried?
- Can the action be undone?
- What should be logged?
The unsafe pattern is letting the model improvise against loosely described tools.
The safer pattern is a tool gateway:
agent -> tool policy -> schema validation -> execution sandbox -> audit log -> result validation
Use MCP where possible, but do not confuse protocol support with safety. MCP makes tools portable. It does not automatically make them safe.

For production SaaS, tools need policy.
The more valuable the workflow, the more explicit the tool boundary should be.
6. Durable Execution: Pay for each step once
Agents fail in expensive ways.
A normal API request fails and returns a 500.
An agent run can fail after 12 model calls, 4 retrieval passes, 3 tool calls, and one half-finished external action.
If the only recovery strategy is "start again," you are burning money and creating duplicate side effects.
Production agent runs need durable execution:
- Step-level checkpoints
- Idempotency keys
- Retries with backoff
- Timeouts
- Human approval pauses
- Resume from last safe state
- Dead-letter handling
Framework-level persistence helps, but long-running product workflows often need a durable execution engine too.
Temporal, Inngest, Step Functions, and similar systems matter because they turn agent work into recoverable jobs instead of fragile request lifetimes.
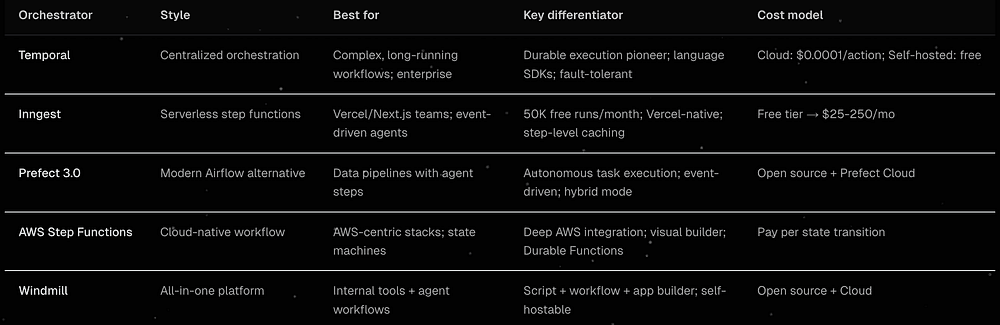
The rule is simple:
If a run can outlive a request, cost real money, or touch an external system, it needs durable execution.
7. Observability: Logs are not enough
You cannot debug agents with plain logs.
You need to see the run as a structured object:
- Initial intent
- Model choices
- Prompt versions
- Retrieved context
- Tool calls
- Intermediate decisions
- Cost
- Latency
- Errors
- Final output
- User feedback
Without this, every production issue becomes a séance.

The useful primitive is a run_id that follows the work everywhere: logs, traces, costs, tool calls, evals, and customer-visible history.
{
"run_id": "run_01J...",
"tenant_id": "tenant_123",
"workflow": "invoice_reconciliation",
"model": "standard",
"retrieval_chunks": 8,
"tool_calls": 3,
"cost_usd": 0.042,
"status": "completed"
}Then add product evals:
- Did the task complete?
- Did the answer cite the right sources?
- Did the tool call obey policy?
- Did the agent escalate when confidence was low?
- Did cost stay inside the budget?
- Did the user accept or correct the result?
Observability tells you what happened, and evals tell you whether it was good.
You need both.
Default stack I would start with
For a serious but still small team, I would keep the first stack boring:
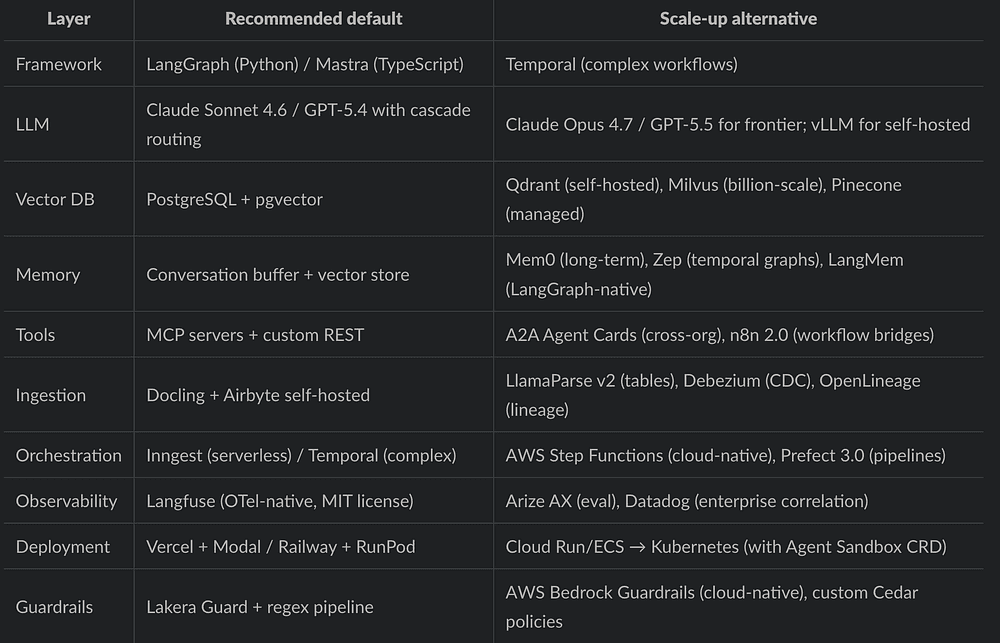
The goal is to preserve optionality while you are still learning what the product actually is.
Do not start with a platform you cannot operate, or self-host frontier models before you understand utilization.
Adding multi-agent choreography before a single agent can complete the job reliably will burn you out.
Forget about the second database unless retrieval quality or scale forces you.
Concluding Thoughts
The winning products are the ones where the agent loop is wrapped in enough boring infrastructure that customers can trust it with real work.
For the complete version, read the full Agentic SaaS Stack chapter inside The Agent Foundry.
- 1The real agentic product is a loop: understand, retrieve, plan, call tools, observe, recover, and learn, and each step needs its own infrastructure layer.
- 2Pick one framework runtime to own the loop, then route requests with cascade routing and caching so not every request hits the most expensive model.
- 3RAG is the floor, not the whole memory layer: start with Postgres plus pgvector and add structured memory only when continuity breaks.
- 4Bad ingestion creates bad agents, so treat parsers, lineage, and incremental sync as first-class, and treat every tool call like a production API with policy.
- 5Durable execution and run-level observability with evals are what turn a fragile demo into a product customers trust with real work.