If you ever open the billing dashboard and you feel something cold, this article is exactly written for you.
I can't remember how many times a single conversation has burned through six figures of tokens in my projects.
Easiest way to achieve the unnecessary goal is to hit a search API that returns a hundred JSON objects and pastes it in a stack trace.
None of it probably felt expensive in isolation but added up, on a model where output costs five times input and every turn re-sends the entire transcript, it is a tax I was paying on every single call for the rest of the session.
So that is why I want to explain how context compressors work in this article.
Every byte a compressor removes is a byte your model no longer reasons over, but you have to remember that the only metric that matters here is task-completion accuracy under the lossy view.
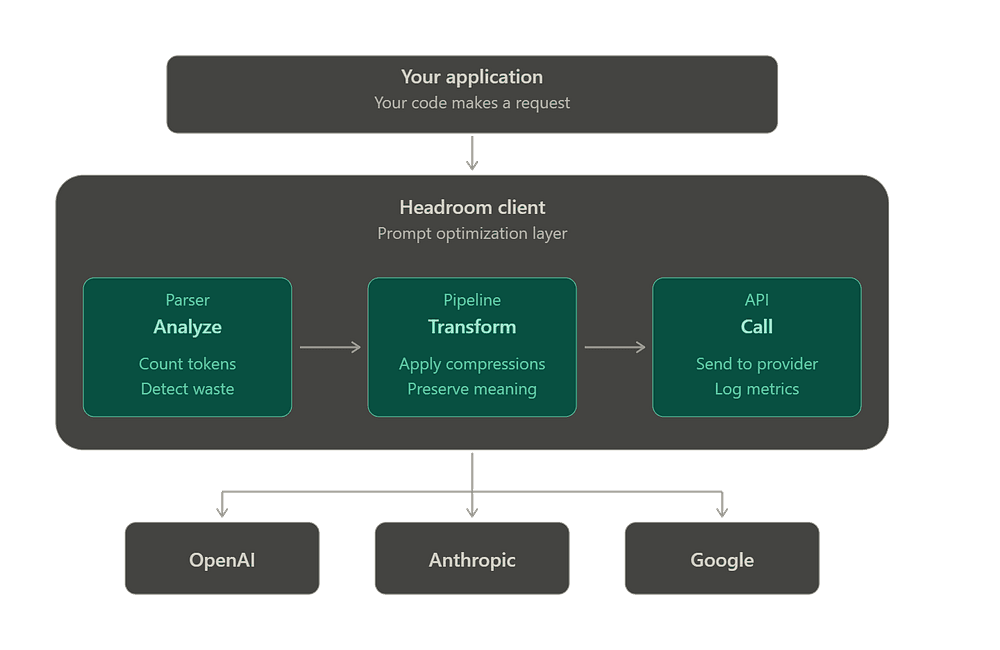
To explain the concepts and usage, I'll use the open-source tool Headroom, built by Netflix engineer Tejas Chopra.
It's a thoughtfully designed piece of software, and reading its own numbers carefully is a way to understand what this entire category can and can't do.
Also to note, the criticism here is of a way of talking about compression, not of one tool.
TL;DR
- A context compressor is an information router on the reasoning path, not a lossless codec, so the metric that matters is task accuracy under the lossy view, not the compression ratio
- The 90%+ headline numbers come from deduplicating highly redundant machine output; general prose compresses around 15 to 30%, and code is often safest at zero
- Compression can destroy a large prompt-caching discount, turning a 30% token saving into a bigger bill, so measure cache hit rate before and after
- Reversibility (compress-cache-retrieve) only protects you when the model knows the view is insufficient, which silent-failure cases hide by construction
Four-figure surprise in your agent's context window
An agent's context is an accumulating log.
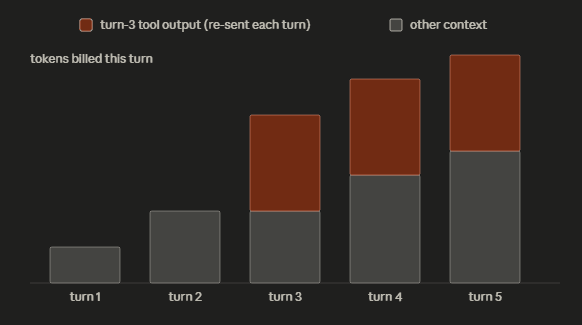
Each turn, the model emits a tool call, your harness runs the tool, the raw output gets appended to the message list; and the entire list is re-sent on the next turn so the model can keep reasoning.
Three properties make this expensive in a way a single chat completion is not:
- Tool outputs are not written for a reader. For example, a search API returns a hundred records or
kubectl logsdumps ten thousand lines. The signal-to-token ratio of machine output is horrendous. - Everything is paid for repeatedly. That hundred-record JSON blob from turn three is still in the context at turn fifteen, billed every single turn in between. Cost grows roughly with the integral of context size over the session, not its final value.
- Output is the expensive half and it compounds the input. On a frontier model, generated tokens cost several times what input tokens cost, and every generated token becomes input on the next turn. A verbose model re-printing the file you just showed it is paying the premium rate to inflate the base rate of every subsequent call.
This is the real shape of the problem.
So I think we all agree that the biggest, most compressible thing in a typical agent context is redundant machine output such as arrays of near-identical records, repetitive logs, boilerplate-heavy HTML.
Hold that thought, because it's the key to reading every compression number you'll ever see.
Context compressor is not a codec
A codec is lossless: gzip a file, ungzip it, get the identical file back, and the model never sees the compressed form.
That is not what these tools do.
They sit between your harness and the model and decide, per request, what the model is allowed to see.
They are an information router on the reasoning path and token saving is a side effect of the routing decision.
The routing decision is the actual product.

That single distinction reorganizes everything:
- A codec's quality metric is the compression ratio, because the output is guaranteed identical. A router's quality metric is whether the model still completes the task, because the output is deliberately different. Using the ratio to evaluate a router is a category error: it measures the side effect and ignores the product.
- A codec fails loudly: corruption, a checksum mismatch, a crash. A router fails silently. It hands the model a plausible-looking, smaller context, the model produces a confident answer from it, and nothing anywhere reports that the answer was computed from a lossy view. The failure surfaces as a subtly wrong result three steps downstream, attributed to "the model hallucinated," instead of "we deleted the row it needed."
- A codec is on a side path but a router is on the critical path. Once a compressor is in your proxy, a bug in its sampling logic is a correctness bug in every call your agent makes, including the ones where the stakes are highest.
Every legitimate use of compression and every way it bites you both fall out of this frame.
The rest of the article is just applying it.
Context was never free
If I only made the case against compression, I'd be lying by omission, because there's a genuinely strong argument for it that has nothing to do with cost.
It's this: a smaller, denser context is often a more accurate context, independent of price.
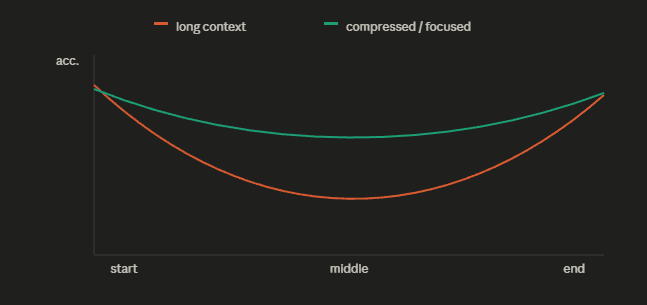
This is the widely known lost-in-the-middle problem.
Across multiple model families, on multi-document QA and key-value retrieval, researchers found a U-shaped performance curve: models use information at the very start and the very end of a long context well, and information buried in the middle poorly, with accuracy on mid-context facts degrading by more than thirty points relative to the edges.
The mechanism is partly architectural: rotary position embeddings have a long-term decay property that systematically reduces attention to distant tokens, and softmax normalization concentrates whatever attention remains on the highest-scoring positions, reinforcing the primacy and recency advantage.
The implication for our router is uncomfortable in the right direction. If you remove a hundred redundant log lines that were pushing the actual error into the lossy middle of a 60K-token context, you may have done the model a favor that shows up as higher accuracy and a lower bill simultaneously.
But read that carefully, because it cuts both ways. The upside exists only when what you delete is genuinely redundant or irrelevant.
The compressor cannot tell the difference from token statistics alone, which brings us to what actually gets deleted.
Field guide to what gets deleted
Compression is an umbrella over at least four mechanically different techniques.
They delete different things and fail in different ways.
Conflating them is how a 90% number for one becomes an implied promise for all.

Let's have a look at each.
Token-level extraction
The most general technique treats the text as a stream of tokens and drops the low-information ones.
Microsoft's LLMLingua pioneered this with a small language model scoring per-token perplexity and a budget controller deciding what to cut, reporting up to 20x compression with little performance loss on benchmarks like GSM8K and BBH.
Its successor, LLMLingua-2, reframed the problem as token classification: train an encoder transformer to label each token keep-or-drop, and reported 2 to 5x compression while being several times faster, now integrated into LangChain and LlamaIndex.
This is the lineage that matters for our example, because Headroom's text compressor, kompress-v2-base, is a direct instance of it: a ModernBERT-base encoder (149M parameters) with a LoRA adapter and a dual head that predicts a keep/drop probability per subword token.
Mechanically, it is the LLMLingua-2 approach with a newer backbone.
What it deletes: articles, filler, predictable continuations, the tokens a language model would guess anyway.
How it fails: it drops the one token that carried disproportionate meaning. For example a negation, a unit, a variable name.
The service did not return 500 and The service returned 500 differ by one low-frequency token that a perplexity-based scorer is tempted to cut.
The published recall numbers make this concrete and honest.
The kompress-v2-base model card reports, at its default threshold, a keep rate of 0.815, meaning roughly 18% of tokens removed, with a must-keep recall of 0.974.
Push it to its most aggressive published setting and you get to about 30% removed, but must-keep recall falls to 0.908.
Read that as: on real prose, the honest ceiling is well under a third, and you buy the last few points of compression by accepting that roughly one important token in eleven gets dropped.
The general-purpose, works-on-any-text compressor lands around 15 to 30%, not 90%, and it degrades measurably as you push it. So where does 90% come from?
Structural sampling and dedup
It comes from here, and it's a fundamentally different operation.
When a tool returns an array of a hundred near-identical JSON objects, you recognize the structure and keep a representative subset: the schema (first few items), the recent items (last few), every anomaly (errors, outliers, distribution boundaries), and a coverage sample of the rest, with constant fields factored out into a single shared header.
Headroom's SmartCrusher does exactly this, using statistical scoring and the Kneedle knee-detection algorithm to pick how many representatives to keep; its docs report 83 to 95% on JSON arrays of dicts and 85 to 94% on logs.
It is deduplication plus sampling of highly redundant records.
The 90% is a property of input that was 90% repetition. If your hundred records are genuinely distinct, the same machinery keeps most of them and your ratio collapses.
The compression ratio here is a measurement of your data's redundancy, wearing the compressor's name.
What it deletes: records judged redundant given the ones it kept.
How it fails: the record you needed wasn't in the sample. The whole approach is a bet that errors, outliers, head, and tail, plus a coverage sample captures everything task-relevant (usually true).
AST pruning for code
Code gets its own treatment because token-dropping mangles syntax. The structural approach parses the file into a syntax tree and keeps the skeleton like signatures, class and function names, imports, and type annotations while pruning bodies and comments.
You hand the model the shape of the codebase instead of all of it.
What it deletes: function bodies, implementation detail, comments.
How it fails: the bug is in the body you pruned. Signature-level context is great for knowing what functions exist and how they connect, and useless for knowing why one returns the wrong value.
By default many tools, Headroom included, pass code through uncompressed (its own benchmarks show 0% on a Python source file) precisely because the failure cost is high.
AST pruning is opt-in, and the default reflects that the safe ratio for code is often zero.
Provider-native conversation compaction
The model providers now do their own version, summarizing or dropping old conversation turns when you approach the window limit.
It's the most convenient option because it requires nothing from you.
What it deletes: old turns, by the provider's opaque policy.
How it fails: you don't control it and can't easily inspect it. It's a black box tuned for the average case, not your workload.
Compression vs. prompt caching
You already have a token-reduction mechanism, and it's bigger than any compressor: provider prompt caching.
When you send a request whose prefix is byte-for-byte identical to a recent one, the provider reuses the cached attention state instead of recomputing it, and charges you a fraction of the price.
The catch is that caching keys on the prefix being byte-identical. One drifting character before the cache boundary like a timestamp, a session ID, or a per-request tier string, and the prefix hashes differently, the cache misses, and you pay full price plus the write premium.
Now combine that with a per-request compressor.
Compression changes the bytes of the prompt.
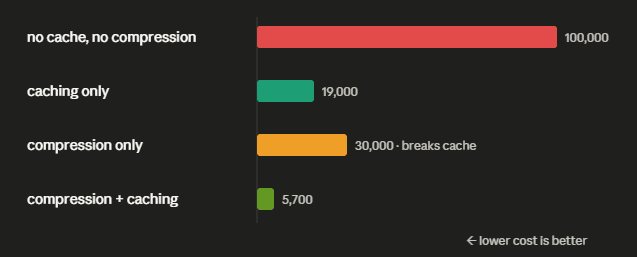
A naive compressor that rewrites your context on every turn produces a different prefix every time, and if your workload was benefiting from a 90% cache discount on a large stable prefix, a compressor that breaks prefix stability can destroy that discount to save 30% on the raw tokens, and 30% off full price is far more expensive than 10% of full price.
You compressed your way to a bigger bill.
Do the arithmetic on a 100K-token prompt that repeats across turns:
This is exactly why a serious compressor has to ship something like Headroom's CacheAligner, which hoists volatile content (dates, IDs) out of the stable prefix into a trailing block specifically so caching survives.
Before and after enabling any compressor, measure your cache hit rate, not just your token count. If compression dropped your cache hits, compute the all-in cost both ways.
There are real workloads where the correct amount of compression, given aggressive caching, is none, and you cannot see that from a token dashboard that doesn't break out cached versus fresh.
Reversibility is the entire safety argument
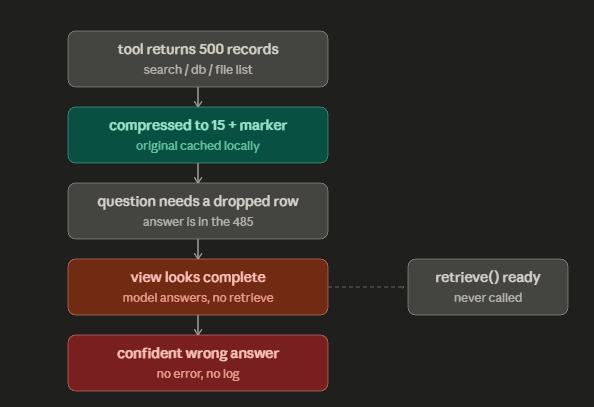
Every honest compressor knows that lossy routing on the critical path is dangerous, so the best ones offer an escape hatch: don't actually throw the data away, cache the original locally, and let the model retrieve it on demand if the compressed view turns out to be insufficient.
Headroom calls this CCR (Compress-Cache-Retrieve): the original payload is stored keyed by a hash, a retrieval tool is injected into the model's toolset, and a marker like [1000 items compressed to 20, retrieve: hash=abc123] is left in the context.
The claim is that you get aggressive-compression savings with zero risk, because nothing is ever truly gone.
This is the most important feature in the category and the one that deserves the hardest look, because the safety it promises has a load-bearing assumption hiding inside it.
Reversibility only protects you if the model actually retrieves, and the model only retrieves if it knows the compressed view is insufficient.
Walk the failure mode:
- A tool returns 500 records. The compressor keeps 15 plus a summary and a retrieval marker.
- The model is asked a question whose answer lives in one of the 485 dropped records.
- The 15-record view looks complete. It's well-formed JSON, it has the right schema, it answers the shape of the question. Nothing about it screams "the row you need is missing" because the whole design goal of good sampling is to produce a representative-looking subset.
- The model, which is built to be helpful and confident, answers from the 15 records. It does not call retrieve, because from its perspective there was nothing to retrieve, the data looked sufficient.
- You get a confident, wrong answer. The reversibility mechanism was present, ready, and never invoked. The escape hatch protects against a danger the model can perceive; this danger is invisible to it by construction.
A lossy summary that looks complete gives the model no signal to recover.
Reversibility converts a guaranteed-correct-but-expensive situation (all the data) into a might-be-correct-and-cheap one, and the "might" is doing enormous unacknowledged work.
There are two more practical constraints on reversibility that the demos gloss over.
- TTL: originals are cached locally with an expiry (Headroom's default store TTL is an hour). A long-running or resumed session can outlive the cache, at which point retrieving the original becomes the original is gone.
- Latency and round-trips: every retrieval is an extra tool call, which is an extra model turn, which is more tokens and more wall-clock, so a workload that needs to retrieve often is paying back the savings with interest, and a workload that's been tuned to retrieve rarely is one where the model is mostly trusting the lossy view.
Reversibility is a backstop against errors the model can notice, and the dangerous errors are the ones it can't.
How to evaluate one of these on your own workload
Everything above reduces to one instruction: stop measuring tokens, start measuring task completion on your own distribution.
Here is how to actually do that. The vendor benchmarks won't do it for you.
Minimal reversible content-typed compressor
This is deliberately small and written from first principles, a clean illustration of the same idea so you can reason about where it loses information.
It compresses a JSON array by keeping head, tail, anomalies, and a coverage sample, factors out constant fields, stores the original in SQLite keyed by a content hash, and emits a retrieval marker.
"""
mini_ccr.py — a from-scratch illustration of reversible, content-typed
compression. Standard library only. Runnable as-is: `python mini_ccr.py`.
This exists to make the mechanism legible, not to be production code.
"""
import json, sqlite3, hashlib, statistics
from typing import Any
STORE = sqlite3.connect(":memory:")
STORE.execute("CREATE TABLE originals (h TEXT PRIMARY KEY, payload TEXT)")
def _hash(payload: str) -> str:
return hashlib.sha256(payload.encode()).hexdigest()[:12]
def _looks_anomalous(item: dict) -> bool:
"""Keep anything that smells like an error/outlier, unconditionally."""
blob = json.dumps(item).lower()
return any(k in blob for k in ("error", "fail", "exception", "fatal", "warn"))
def compress_json_array(items: list[dict],
head: int = 3, tail: int = 2, sample: int = 5) -> dict:
"""Return a compressed view + a retrieval handle. Original is stored."""
original = json.dumps(items, sort_keys=True)
h = _hash(original)
STORE.execute("INSERT OR REPLACE INTO originals VALUES (?, ?)", (h, original))
if not items or not all(isinstance(x, dict) for x in items):
return {"view": items, "handle": h, "kept": len(items), "total": len(items)}
# Factor out fields that are constant across every item.
keys = set().union(*(x.keys() for x in items))
constants = {k: items[0][k] for k in keys
if all(k in x and x[k] == items[0].get(k) for x in items)}
keep_idx: set[int] = set(range(min(head, len(items)))) # schema
keep_idx |= set(range(max(0, len(items) - tail), len(items))) # recency
keep_idx |= {i for i, x in enumerate(items) if _looks_anomalous(x)} # anomalies
# Even coverage sample across the remaining middle.
middle = [i for i in range(len(items)) if i not in keep_idx]
if middle and sample > 0:
step = max(1, len(middle) // sample)
keep_idx |= set(middle[::step][:sample])
def strip(x: dict) -> dict:
return {k: v for k, v in x.items() if k not in constants}
view = {
"_constants": constants,
"_note": f"{len(items)} items compressed to {len(keep_idx)}. "
f"Retrieve full set with handle={h}.",
"items": [{"_i": i, **strip(items[i])} for i in sorted(keep_idx)],
}
return {"view": view, "handle": h, "kept": len(keep_idx), "total": len(items)}
def retrieve(handle: str, contains: str | None = None) -> list[dict]:
"""The escape hatch. Optionally filter, à la BM25-lite, by substring."""
row = STORE.execute("SELECT payload FROM originals WHERE h=?", (handle,)).fetchone()
if not row:
raise KeyError(f"handle {handle} not in store (expired or never written)")
items = json.loads(row[0])
if contains:
items = [x for x in items if contains.lower() in json.dumps(x).lower()]
return items
if __name__ == "__main__":
# 200 boring records, one needle in the unremarkable middle (row 137).
data = [{"id": i, "status": "ok", "service": "api", "latency_ms": 40 + (i % 5)}
for i in range(200)]
data[137] = {"id": 137, "status": "ok", "service": "api",
"latency_ms": 41, "owner_email": "alice@corp.example"} # the answer
out = compress_json_array(data)
kept_ids = [it["_i"] for it in out["view"]["items"]]
print(f"kept {out['kept']}/{out['total']} records "
f"({100*(1-out['kept']/out['total']):.0f}% compression)")
print("needle (row 137) survived compression:", 137 in kept_ids)
print("but retrievable on demand:",
retrieve(out["handle"], contains="owner_email")[0]["owner_email"])Run it and you'll see the honest result: 95% compression (it keeps 10 of 200 records), the needle row 137 is not in the kept set (it has no error flag and isn't head/tail/sampled), and yet it's perfectly recoverable via retrieve(...).
That single output is the entire dilemma in miniature: the ratio looks great, the data is not lost, and the model will still answer wrong unless it knows to call retrieve, which the compressed view gives it no reason to do.
Eval harness that measures what matters
Now the harness.
It runs your agent task twice, full context and compressed context, over many planted-needle cases, and reports task accuracy and retrieval-trigger rate.
It's runnable as written against a deterministic stand-in for the model, so you can see the methodology and the output format, then swap run_agent_turn for a real provider call to evaluate your actual stack.
"""
eval_compression.py — measure task accuracy + retrieval rate under
compression, on a planted-needle workload. Runnable with the bundled
stub model; replace `run_agent_turn` to test a real agent.
"""
import json, random
from dataclasses import dataclass
from mini_ccr import compress_json_array, retrieve
random.seed(0)
@dataclass
class TurnResult:
answer: str
called_retrieve: bool
def make_case() -> tuple[list[dict], str, str]:
"""200 records, one needle. Returns (records, question, gold_answer)."""
n, needle = 200, random.randint(20, 180)
token = f"TENANT-{random.randint(1000, 9999)}"
recs = [{"id": i, "status": "ok", "region": "us-east", "code": 200}
for i in range(n)]
recs[needle] = {"id": needle, "status": "ok", "region": "us-east",
"code": 200, "tenant": token} # the needle
q = "Which tenant id appears in the records? Reply with the tenant id only."
return recs, q, token
# ---- Replace this stub with a real provider call to test your own agent. ----
# The stub models TWO behaviors so the harness runs and the contrast is visible:
# - In the FULL-context condition it can read the needle directly.
# - In the COMPRESSED condition it answers from the visible view, and only
# calls retrieve when the view's _note makes the omission explicit AND we
# simulate a model that acts on it (toggle RETRIEVES_WHEN_PROMPTED).
RETRIEVES_WHEN_PROMPTED = False # flip to True to simulate a retrieval-aware agent
def run_agent_turn(question: str, context_obj, handle: str | None) -> TurnResult:
blob = json.dumps(context_obj)
if "tenant" in blob and "TENANT-" in blob: # needle is visible
tok = next(p for p in blob.replace('"', " ").split() if p.startswith("TENANT-"))
return TurnResult(answer=tok, called_retrieve=False)
if handle and RETRIEVES_WHEN_PROMPTED: # escape hatch fires
hit = retrieve(handle, contains="tenant")
if hit:
return TurnResult(answer=hit[0]["tenant"], called_retrieve=True)
return TurnResult(answer="unknown", called_retrieve=False) # confident-wrong path
# ----------------------------------------------------------------------------
def evaluate(n_cases: int = 200) -> None:
rows = []
for condition in ("full_context", "compressed"):
correct = retrieved = 0
for _ in range(n_cases):
recs, q, gold = make_case()
if condition == "full_context":
res = run_agent_turn(q, recs, handle=None)
else:
c = compress_json_array(recs)
res = run_agent_turn(q, c["view"], handle=c["handle"])
correct += (res.answer == gold)
retrieved += res.called_retrieve
rows.append((condition, correct / n_cases, retrieved / n_cases))
print(f"{'condition':<16}{'task_accuracy':>15}{'retrieval_rate':>16}")
for name, acc, rr in rows:
print(f"{name:<16}{acc:>14.0%}{rr:>16.0%}")
if __name__ == "__main__":
evaluate()With the stub's default (RETRIEVES_WHEN_PROMPTED = False), you'll see full-context accuracy at 100% and compressed accuracy collapse toward 0% with a 0% retrieval rate, the silent-failure regime, where the data is recoverable but never recovered.
Flip the toggle to True and compressed accuracy climbs back up with a non-zero retrieval rate, the regime where the escape hatch actually engages. The point isn't the toy numbers.
It's the shape of the measurement: two dials, task accuracy and retrieval rate, that together tell you whether compression is safe on your workload or just cheaper.
No token count appears anywhere in the output, on purpose.
Wire this to your real agent and your real tool outputs, plant needles where your actual failures live (the unremarkable row, the mid-context log line, the pruned function body), and run it before and after enabling any compressor.
- If accuracy holds and retrieval rate is near zero, congratulations, your data really was that redundant, compress aggressively.
- If accuracy drops, you've found the silent failure the token dashboard was hiding.
- If retrieval rate is high, you're paying for those round-trips, so re-check that the savings survive them.
When to reach for it and when it's a foot-gun
Stepping back to the actual engineering decision.
Compression on the agent path is a sharp tool with a specific blast radius.
Reach for it when:
- Your tool outputs are genuinely redundant. High-volume agents drowning in big JSON arrays, repetitive log dumps, or boilerplate-heavy scraped HTML are the canonical fit.
- You're cost-dominated and you've measured accuracy holds. If the bill is the binding constraint and your needle-eval shows task accuracy is preserved on your distribution, the savings are real and worth taking.
- You're hitting the context window, not just the bill. When sessions overflow the window, you're going to drop something; a content-aware compressor that keeps schema, anomalies, and recent turns is a smarter dropping policy than blind truncation, and it lets you stay under the limit while keeping the signal that survives lost-in-the-middle.
Treat it as a foot-gun when:
- Your context is low-redundancy prose or code. If the bulk of your tokens are dense reasoning, documentation, or source you actually need read, the general path gives you 15 to 30% and you're spending recall to get it.
- You're already well-served by prompt caching. If a large stable prefix is giving you a 90% cache discount, a compressor that disturbs the prefix can be a net loss. Measure cache hit rate before committing.
- A single missed record is catastrophic and the model won't retrieve. High-stakes, single-shot tasks, anything where a confidently-wrong answer from a sampled view does real damage, are exactly where the silent-failure mode is unacceptable and the reversibility backstop is least reliable.
- You can't run a local process. Several of these tools are local proxies by design (your data stays on your machine, which is a genuine privacy virtue). In a locked-down or serverless environment where you can't run the proxy, that architecture is a non-starter.
Concluding thoughts
The compression ratio is a vanity metric.
It measures bytes removed, not value retained, and the headline number is always the best case of the most aggressive technique on the most redundant input anyone could find.
The number that predicts your bill is the ratio on your traffic; the number that predicts your agent's quality is task-completion accuracy under the lossy view, measured with planted needles where your real failures live.
Those are different numbers, and only the second one tells you whether you bought a saving or a silent regression.
Measure the thing that matters, and watch the cache.
Assume the escape hatch won't fire unless you've proven it does. Then, and only then, enjoy the smaller bill because now you know it didn't cost you the answer.
- 1A context compressor is an information router on the reasoning path, so judge it by task-completion accuracy under the lossy view, not by the compression ratio
- 290%+ ratios come from deduplicating highly redundant machine output; general prose lands around 15 to 30% and code is often safest at zero
- 3Compression can break byte-identical prompt caching and turn a 30% token saving into a larger bill, so measure cache hit rate before and after
- 4Reversibility (compress-cache-retrieve) only helps when the model knows the view is insufficient, and the dangerous failures are the ones it cannot perceive
- 5Evaluate on your own workload with planted-needle cases, watching two dials: task accuracy and retrieval-trigger rate