There is a fashionable claim going around that the unit of work in software has moved from the prompt to the loop, that you should stop typing instructions to a coding agent and instead write the small program that types them for you.
The people making the claim are credible.
Anthropic’s Boris Cherny describes having shifted his own workflow from prompting Claude Code to writing the loops that prompt it.
Now it’s actually leveled up, I think, again, to the next wave of abstraction where I don’t prompt Claude anymore. I have loops that are running. They’re the ones that are prompting Claude and figuring out what to do. My job is to write loops.
Peter Steinberger frames the same shift as designing loops rather than operating agents.
Geoffrey Huntley turned the idea into a now-famous bash technique and Steve Yegge built a multi-agent orchestrator out of it.
The shape of the thing is real, and it works.
But the way it’s being explained is missing the important part.
Almost every walkthrough I’ve read organizes itself around plumbing like schedulers, isolated checkouts, subagents, memory files as if the engineering problem were assembly, it isn’t.
That stuff is solved infrastructure, the products ship it now.
The unsolved problem, the one that decides whether your loop is cheap or ruinous, stable or thrashing, trustworthy or quietly lying to you, is a single component that most write-ups mention in passing and move on from.
So let’s reframe the whole thing in terms of a discipline that actually has rigor here, because what you are building when you write a loop is not new and it is not a social media trend.
It is a feedback controller, and control engineers have known for a century exactly which part is hard.
Before code examples, let’s strengthen our fundamentals and also understand when not to build one.

What you’re actually building
A feedback controller has five parts.
Name them and the entire topic reorganizes itself.
- The setpoint is the target: what you want the system to reach and hold. In a loop, this is your goal, expressed in terms something can actually measure: something like '
pytest tests/authexits zero and the type checker is clean.' - The plant is the thing being controlled: the system that responds to inputs in ways you don’t fully control. Here, the plant is the coding agent acting on your codebase. Crucially, this plant is stochastic: the same input does not produce the same output twice. That single property is what makes this hard, and we’ll return to it.
- The actuator is how the controller acts on the plant. For an agent, the actuators are its tools, e.g., file edits, shell commands, an MCP connector that opens a PR or queries a database.
- The sensor is how the controller observes the plant’s actual state. In a loop, the sensor is your verifier: the test suite, the build, the linter, the second agent reading the diff. The sensor produces the error signal, which is the gap between where the system is and where the setpoint says it should be.
- The controller logic is the rule that turns the error signal into the next action. In a loop, this is the orchestration: read the sensor, decide whether you’re done, and if not, compose the next prompt and run the agent again.
That is what every agent loop is, from a five-line bash script to Yegge’s orchestrator.
The 2022 ReAct paper also described the minimal version: reason, act, observe, repeat, which is a single proportional controller with a human reading the sensor.
Huntley’s ralph technique is the minimal practical version: feed a fixed prompt to a fresh agent process on every iteration so the context never rots, and let it run.
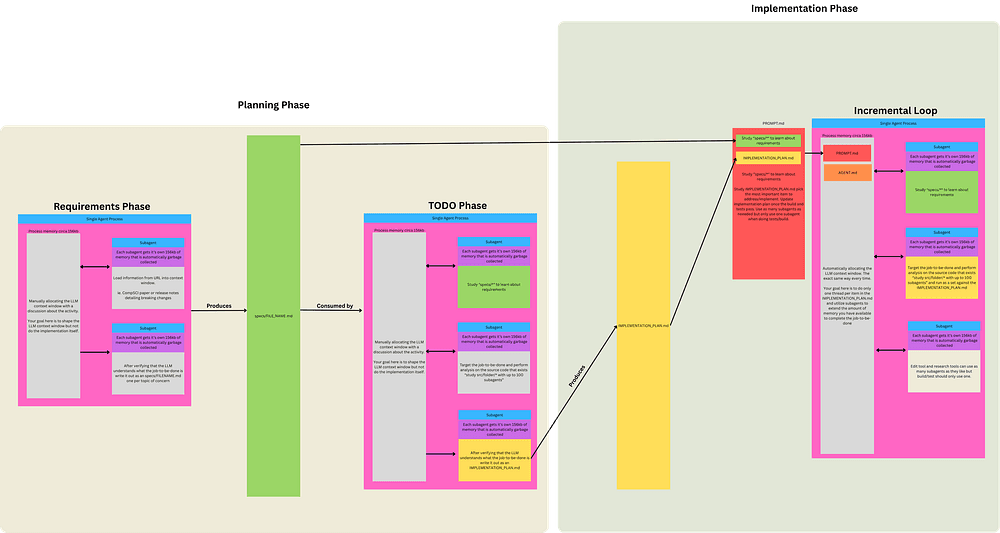
Everything since like scheduled triggers, parallel worktrees, a separate model grading completion is the same controller with better engineering around the edges.
Once you see the loop as a controller, you would ask: Does it converge? To the right place? And what does it cost when it doesn’t?
Editor’s note: To celebrate our growing community, we released Compass: a blueprint of a production-grade customer support agent built to demonstrate how modern agent systems are actually engineered and operated in real environments. Compass is part of our Agent Foundry program and you can get it here completely for free.
The only three things a loop can do
A controlled system can do exactly three things, and your entire job is to bias it toward the first and bound the cost of the other two.
It can converge to a correct state. The agent reaches a point where the sensor reports the setpoint is met, and the sensor is telling the truth. This is the only good outcome. Everything you build is in service of making this more likely and getting there in fewer steps.
It can converge to a wrong state. The loop stops because the sensor reports success but the sensor is wrong. The tests passed because they tested the wrong thing. The build is green because the broken path isn’t exercised. The second agent approved because it was too agreeable. This is the dangerous outcome, far worse than the loop running forever, because it terminates confidently.
It can diverge. The loop never reaches a state the sensor accepts. It oscillates, or it spins making no progress, or it wanders off the goal entirely. Left alone, it runs until something external stops it such as a rate limit, a budget alarm, or you noticing the bill.
Hold this taxonomy in your head, because it sorts every technique in the field into one of two jobs: increasing the probability of convergence-to-correct, or bounding the damage from the other two.
The sensor problem
Here is the thesis, stated plainly:
The quality of your verifier sets the cost, the stability, and the trustworthiness of the entire loop. Everything else is secondary, and the verifier is the part you can’t outsource to the model.
Let me defend that on all three axes, because it’s the part the orchestration-first explanations get wrong.
The sensor sets the cost. A loop’s total cost is, to a first approximation, the cost of one agent step multiplied by the number of steps it takes to converge. The number of steps is not a property of the model. It’s a property of how much information your sensor hands back on each iteration. A sensor that says only pass or fail gives the agent almost no gradient to follow, it’s told it’s wrong but not how, so the next attempt is barely more informed than the last, and the loop wanders.
A sensor that hands back the name of the failing test, the assertion that blew up, the stack trace, and the diff that introduced it collapses the search space immediately.
The agent isn’t guessing anymore but correcting a specific defect.
That’s why the highest-leverage money you can spend on a loop is a more informative sensor.
Most people get this exactly backwards: they reach for the strongest, most expensive model to write the code, then verify it with a weak check, and pay for the thrashing that follows.
The sensor sets the stability. This is the real content of the open loop versus closed loop distinction that the popular write-ups gesture at without explaining.
The terms come straight from control theory and they mean something precise.
- Closed-loop controller feeds the sensor reading back into the next decision, it corrects toward the setpoint.
- Open-loop controller does not, it acts on a fixed plan with no feedback.
Open-loop control is fine when the plant is perfectly predictable, and useless the moment there’s disturbance, because errors accumulate with nothing to pull them back.
Now recall that your plant (the agent) is stochastic. It is the single most disturbance-prone plant imaginable.
Running an agent loop without a sensor that actually measures correctness is running open-loop control on a system that guarantees drift.
That is the entire reason exploratory, 'let it roam' loops feel exciting and then turn into expensive slop generators: they’re not closed at all.
They’re open-loop control wearing a feedback costume, because the goal they’re chasing ('build something good') is one the sensor can’t measure, so there’s no real error signal to close the loop on.
The sensor sets the trustworthiness. The whole proposition of a loop is that you stop watching. You can only stop watching if you trust the sensor to fail bad work in your absence.
This is why the verifier cannot be the same agent that did the work for a structural reason: a maker grading its own output has correlated error.
Whatever blind spot caused the bug also causes it to miss the bug. You need an independent sensor with a different vantage.
The maker is an optimist by construction. Your sensor has to be a pessimist by construction.
And now the uncomfortable part: the model cannot design your sensor for you.
It can write the loop, the scheduler, the worktree glue, even draft the tests but the question of what 'correct' means for your system, e.g., which invariants must never break, which behaviors define done, what a passing test must actually exercise, is domain truth.
It lives in your head and your requirements.
The loop is the part that’s been automated and the sensor is the part that’s still, irreducibly, engineering.
That’s the work that moved up an altitude and it didn’t disappear at all.
And also real sensors aren’t perfect, and the most common defect in a code loop is the flaky test, a check that fails intermittently with no change in the code.
That’s sensor noise, and it’s poison to a controller, because the loop can’t distinguish a real regression from a false reading.
It will chase phantom errors, paying the agent to fix things that were never broken, and it may also do the reverse: pass on a run where a real failure happened to flake green.
The control answer is the same as in any noisy system, filter before you act.
- The cheap filter is retry-once-then-believe: re-run a failing check a single time, treat only a failure that reproduces as a real error signal, and log a failure that vanishes as flake rather than acting on it.
- The correct-but-expensive fix is to make the sensor deterministic in the first place.
Either way, never wire a noisy sensor straight into the controller, because every false reading is a full agent step you paid for and a step that may have made the code worse.
The brakes, and why one of them is always missing
Failure mode here is financial rather than physical: a loop with no brakes doesn’t crash a turbine, it runs up a bill that arrives at the end of the month.
There are three limiters, and you need all three.
- Step ceiling caps the number of iterations. Simple, blunt, non-negotiable. If the loop hasn’t converged in N tries, something is wrong and continuing is throwing money at it.
- Budget ceiling caps tokens or dollars for the whole run. This one matters because the step ceiling alone doesn’t bound cost when a single step can balloon, a fleet that spawns subagents can spend wildly inside one 'iteration.' Cap the spend directly.
- No-progress detector is the one almost nobody implements, and it’s the most important of the three.
The first two catch a loop that runs too long but the third catches a loop that’s stuck, burning steps and tokens without changing anything.
It’s the derivative term of the controller: don’t just watch the error, watch whether the error is moving, e.g., if the sensor returns the same signal three iterations running, or the repository HEAD hasn’t advanced, the agent is spinning.
The asymmetry across these three is the design philosophy in miniature: the agent’s own claim that it’s finished is a soft signal you may consider, and the limiters are hard signals that don’t trust the agent at all.
Building one, with the parts named
Let’s have a look at a controller written simply, with labeled components so you can see the mapping.
import time
from dataclasses import dataclass
@dataclass
class Setpoint:
"""The target, in terms the sensor can actually measure."""
spec_path: str # standing spec, reread every tick
invariants: list[str] # things that must never break
@dataclass
class Limiter:
"""Saturation. The loop physically cannot exceed these."""
max_steps: int = 20
max_tokens: int = 500_000
max_seconds: int = 3600
stall_after: int = 3 # no-progress trip threshold
def sense(setpoint: Setpoint) -> tuple[bool, str]:
"""The SENSOR. Returns (converged?, signal).
Must be able to FAIL the work with no human present. This is a
test / build / type check that returns an exit code - never a
second model asked 'did you do well?'. The richer the signal,
the fewer steps to converge, the less the whole loop costs."""
import subprocess
tests = subprocess.run(["pytest", "-q", "tests/auth"], capture_output=True, text=True)
types = subprocess.run(["mypy", "src/auth"], capture_output=True, text=True)
converged = tests.returncode == 0 and types.returncode == 0
# hand back the actual failure text, not just pass/fail
signal = (tests.stdout + tests.stderr + types.stdout)[-2000:]
return converged, signal
def actuate(prompt: str) -> dict:
"""The PLANT + ACTUATOR. Runs the stochastic agent on the codebase.
Returns {'summary': str, 'tokens': int}. Wire this to your harness:
Claude Code headless, a raw API call, whatever you run."""
...
def compose(setpoint: Setpoint, history: list[str], last_signal: str) -> str:
"""CONTROLLER LOGIC. Turns the error signal into the next action.
Anchor on the spec + recent history + the latest sensor reading.
Fresh, bounded context each tick - don't replay the whole transcript."""
spec = open(setpoint.spec_path).read()
recent = "\n".join(history[-8:])
rules = "\n".join(f"- never: {i}" for i in setpoint.invariants)
return (
f"{spec}\n\n## Invariants\n{rules}\n\n"
f"## Progress so far\n{recent}\n\n"
f"## Latest failure to fix\n{last_signal}\n\n"
f"Make the smallest change that moves the failure forward. Then stop."
)
def control(setpoint: Setpoint, limiter: Limiter):
history: list[str] = []
steps = tokens = stalls = 0
last_signal = "(none yet)"
t0 = time.monotonic()
while True:
# --- saturation / anti-windup: checked first, every tick ---
if steps >= limiter.max_steps: return "halt: step cap", history
if tokens >= limiter.max_tokens: return "halt: token cap", history
if time.monotonic() - t0 > limiter.max_seconds: return "halt: time cap", history
steps += 1
out = actuate(compose(setpoint, history, last_signal))
tokens += out["tokens"]
history.append(out["summary"])
converged, signal = sense(setpoint)
if converged:
return "converged", history # the only good exit
# --- derivative term: is the error even moving? ---
stalls = stalls + 1 if signal == last_signal else 0
last_signal = signal
if stalls >= limiter.stall_after:
return "halt: stalled (signal not changing)", historysense()is your sensor and it’s the line that decides whether the whole thing helps or just spends.actuate()is the stochastic plant.compose()is the controller logic, and notice it feeds the actual failure text back in, that’s the rich error signal that keeps step count low.
The top of the loop is saturation; the stall check is the derivative term. There is no clever trick here. The cleverness, all of it, lives inside sense(), in whether your tests actually exercise the thing you care about.
For comparison, here is the degenerate case, the canonical minimal loop in its rawest form:
# The open-loop trap. Fine for throwaway greenfield; reckless otherwise.
while :; do cat PROMPT.md | claude -p ; doneThis converges to something and you review it in the morning. But if PROMPT.md describes a goal no automated check can measure, this is open-loop control on a stochastic plant.
It will drift, and it will not stop.
The whole discipline is the distance between that one-liner and the controller above, and almost all of that distance is the sensor and the limiter.
You don’t have to hand-roll the controller to start.
Modern coding agents ship the pieces.
/loopprimitive gives you the heartbeat, re-run on a cadence regardless of state, which is your scheduler./goalprimitive gives you closed-loop termination, keep going until a stated condition is verified, with a separate model checking the condition so the maker doesn’t grade itself.
Scaling up is cascade control
When one controller isn’t enough the task is genuinely too big for a single loop, and the popular instinct is to spawn a fleet: an orchestrator that hands pieces to specialist agents that hand sub-pieces to their own subagents.
Yegge’s orchestrator and the general fleet pattern are exactly this shape.
But more agents is the wrong mental model, and it’s precisely how fleets degenerate into expensive chaos.
The right model is cascade control: nested controllers where the outer loop does no work itself, it sets the setpoint for inner loops and reads their aggregate state.
In a cascaded system, the outer controller is slow and strategic. It decomposes the goal into sub-targets and assigns each to an inner controller. Each inner controller is fast and local: its own plant (an agent in its own isolated checkout, so concurrent inner loops can’t corrupt each other), its own sensor (the check for that sub-task), its own brakes.
Two properties make cascade control stable, and both have direct loop analogs.
- First, the inner loops must be faster and more reliable than the outer loop. If a specialist loop is itself unstable, the orchestrator is building on sand, so get a single controller converging reliably before you ever nest it.
- Second, every layer needs its own limiter. Each inner loop gets its own step and token ceiling, and the outer loop gets one on top. The reason fleets produce the truly eye-watering bills is an unbounded variable cost multiplied across unbounded layers, a runaway specialist with no cap can drain the entire run by itself.
You scale this by composing controllers you already trust, each with its own sensor and its own brakes, under an outer controller whose only jobs are decomposition, setpoint assignment, and an independent check that the assembled result holds.
When a loop is the wrong tool
Most of the value here is knowing when not to build one.
The orchestration-first framing makes loops sound universally applicable, the control framing makes the boundary obvious.
A loop is the right tool when you can build a sensor, and the wrong tool when you can’t.
So the test is one question with a few corollaries: Can you write a check that fails bad output without you in the room?
If the answer is no, if done is a judgment call, if correctness is a matter of taste, if there’s no test or build or type check that can reject a bad result, then you cannot close the loop.
You’d be running open-loop control on a stochastic plant, which is the slop machine.
If the answer is yes, a few more corollaries decide whether it’s worth it.
The task has to recur, a controller you build once and run once is just an expensive script but the setup amortizes over many runs or not at all.
The agent needs real actuators and observability such as logs, a reproduction environment, the ability to run what it writes and see what breaks, or it’s correcting blind. And a human has to sit in front of anything irreversible like merge, deploy, dependency change because a sensor that’s wrong (convergence-to-incorrect) is the one failure your brakes can’t catch.
Concluding thoughts
Two engineers can build the identical loop and get opposite results.
One designs a sharp sensor because they understand the system deeply enough to say precisely what correct looks like, and the loop becomes leverage.
The other builds a loop to avoid having to understand the system, ships a sensor that can’t tell good from bad, and the loop becomes a confident conveyor belt for work nobody vetted.
The controller doesn’t know which one you are and the sensor is where the difference lives, and the sensor is the part that was always going to be yours.
So if you build one: build the brakes first, build the sensor like it’s the only thing that matters, because it nearly is, and stay close enough to the system that you could still write the check by hand.
- 1An agent loop is a feedback controller with five parts: setpoint, plant, actuator, sensor, and controller logic.
- 2The sensor (your verifier) sets the cost, stability, and trustworthiness of the whole loop, and it's the one part the model can't design for you.
- 3A loop can converge-correct, converge-wrong, or diverge; convergence to a wrong state is the dangerous outcome because it terminates confidently.
- 4You need three brakes: a step ceiling, a budget ceiling, and a no-progress detector, and the no-progress detector is the one most people skip.
- 5Only build a loop when you can write a check that fails bad output without you in the room, otherwise you're running open-loop control on a stochastic plant.