Consumer hardware is already good enough to do meaningful agent work locally but it is not good enough to make frontier cloud models irrelevant.
Most people ask the following question:
Can my RTX 4090, or M5 Max 128GB, replace Sonnet, Opus, GPT, or the latest premium coding model?
But in this article, I will answer the following question:
What GPU can run parts of the agent loop locally with good performance?
And once you frame it this way, the answer gets much more interesting.
A single RTX 4090 can already handle a serious amount of coding work with the right open model, the right quantization, and a harness that doesn't waste half your context window on boilerplate.
Apple Silicon machines like an M5 Pro 64GB or M5 Max 128GB are compelling for a different reason: not because they magically beat the cloud, but because they buy you local capacity, mobility, privacy, and larger-context workflows.
Meanwhile, the cloud still wins whenever you need top-end reasoning reliability, long-horizon planning, or consistently excellent output under pressure.
In this article, I want to make a developer-first case for how to think about consumer hardware in 2026 if you are building AI features, coding agents, or internal agentic workflows.
We will go through:
- what consumer hardware can realistically do today (including model benchmarks on Apple Silicon)
- state of open coding models in 2026
- where local models already pull their weight and where they still break
- why the harness matters almost as much as the model
- why the best local setup is often a subagent or coprocessor, not a full replacement
Let's get into it.
The brutally honest answer in one screen
Here is the short version.
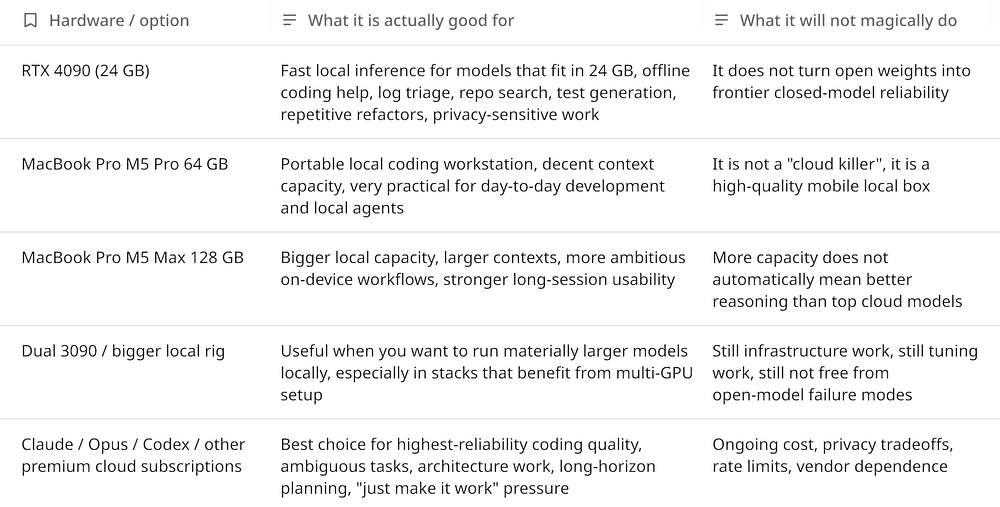
If your job is to ship product:
You should ask whether local can take ownership of the cheap, repetitive, private, or deterministic parts of the agent workflow.
That is where the ROI is, not in pretending a 24 GB VRAM is secretly an H100 cluster.
Editor's note: To mark 10,000 community members, we recently released Compass, a blueprint of a production-grade customer support agent built to demonstrate how modern agent systems are actually engineered and operated in real environments. Compass is part of our Agent Foundry program and you can get it here completely for free.
The biggest mistake in local-model discourse
Most local-model arguments collapse three very different things into one bucket:
- The model itself
- The inference/runtime stack
- The agent harness
That is a terrible abstraction boundary.
In real agentic systems, these three layers interact constantly.
A weaker model with a disciplined harness, low-noise prompts, proper tool formatting, and good project instructions can outperform a stronger model running inside a bloated scaffold that dumps garbage context into every turn.
This shows up repeatedly in practice.
Some popular coding harnesses throw useless context and bloated prompts at the model, which hurts reasoning before the task even starts.
For example, Cline's local-model guide explicitly recommends enabling compact prompts, which it says reduces prompt size by 90% while keeping core functionality intact.
OpenCode gives you an AGENTS.md mechanism, a dedicated Plan agent for analysis without writes, a default Build agent for full execution, and subagents like Explore for read-only repo navigation.
Because agent performance is partly an orchestration problem.
Similarly, Claude Code is an agentic coding tool that reads your codebase, edits files, runs commands, integrates with development tools, stores instructions in CLAUDE.md, supports MCP, and can run multiple agents.
So before we even touch hardware, let's establish the actual engineering principle: Local-model success is downstream of context discipline.
That means:
- minimize hidden prompt waste
- keep tool schemas predictable
- keep context windows realistic
- persist repo-specific instructions
- split planning from execution when possible
- use smaller, cheaper, local models for bounded tasks
- escalate only when the task actually deserves a premium model
If you ignore those rules, you can absolutely spend a fortune on hardware and still get disappointing results.
Consumer hardware is best understood as infrastructure
There is a real difference between speed and capacity, and that distinction matters more in agentic workflows.
RTX 4090
The 4090 is still incredibly relevant because a lot of the new "surprisingly capable" open coding models are not giant dense models.
They are often sparse MoE models with small active parameter counts or otherwise efficient enough to feel fast on consumer GPUs.
The current Ollama model page for qwen3.6:35b-a3b lists a 24 GB quantized artifact, which is exactly why this class of model gets so much attention.
That single fact changes the local development conversation.
A model in this family can sit inside the memory envelope of a 4090-class card instead of immediately forcing you into workstation or server-grade hardware.
This is the practical consequence:
- if the model fits cleanly on the card
- if the runtime is competent
- if the harness is not dumping trash into the context
- if the task is not asking frontier-level reasoning every turn
then a 4090 can absolutely become a real engineering asset.
That does not mean it replaces Claude Sonnet or Opus on your hardest work, but it can do a shocking amount of useful work before you need to escalate.
That is already enough to save money and reduce cloud dependence.
Apple Silicon
The 4090 is generally the more obvious answer for raw single-model local speed-per-dollar when the model fits in 24 GB, but Apple Silicon machines buy you things many local-LLM discussions undervalue:
- unified memory
- portable high-capacity inference
- low-friction local serving
- better "always with you" workflows
- surprisingly capable MLX-format performance
- a clean laptop form factor for private/offline work
The current oMLX community benchmark page is especially interesting here because it gives community-submitted numbers rather than vendor marketing claims.
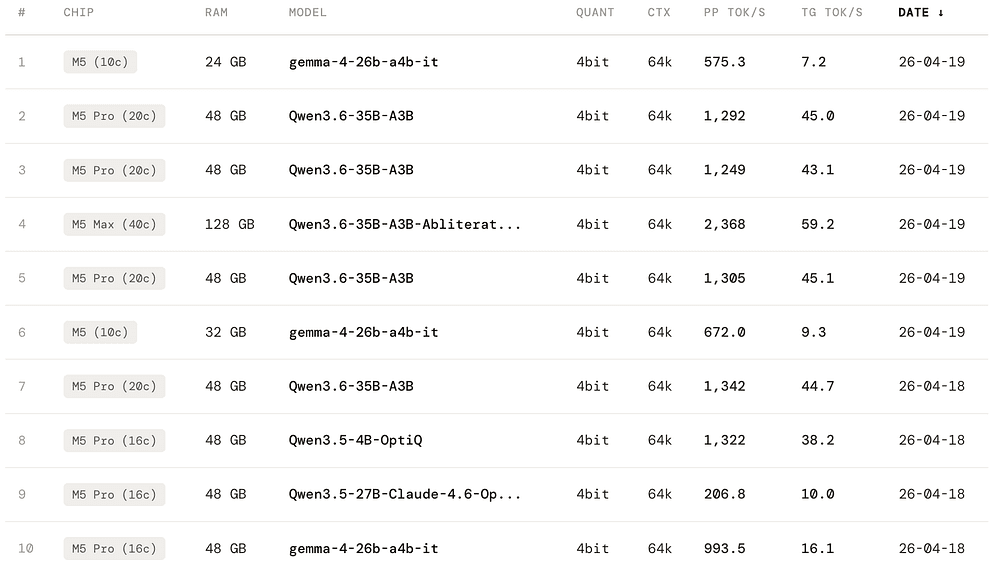
It shows a few examples like:
- M5 (10c), 24GB running
gemma-4-26b-a4b-itat 7.2 tok/s at 64k context - M5 Pro (20c), 48GB running
Qwen3.6-35B-A3Bat 45 tok/s at 64k context - M5 Max (40c), 128 GB running
Qwen3.6-35B-A3B-Abl...at 59.2 tok/s at 64k context
These numbers show you the current working envelope developers are actually achieving on these machines, and it's good to see that Apple Silicon has crossed the threshold from novelty to usefulness.
They are now viable for:
- real context windows
- real local serving
- real agent integrations
- real day-to-day coding assistance
And for many developers, that is the real win.
The M5 Pro vs M5 Max decision
This is where the conversation gets more honest.
If your goal is:
- a practical portable developer machine
- local experimentation
- one solid open model at a time
- decent context
- strong "I want this on my laptop" ergonomics
then an M5 Pro 64 GB already looks like a rational purchase.
If your goal is:
- bigger local models
- more comfortable context headroom
- more room for local experimentation
- more ambitious all-local workflows
- longer sessions without hitting walls
then M5 Max 128 GB is clearly more capable.
But you should buy it for capacity, not because you think the extra memory suddenly grants frontier-model reasoning.
Local is strongest as a coprocessor
You can use your personal machine as a subagent for Claude Code and Codex, offloading "dumb heavy lifting" such as linting, boilerplate, or grepping massive logs.
Local models can own the parts of the agent loop that are expensive but not precious.
Your local hardware then becomes:
- a private inference backend
- a bounded-task executor
- a tool-calling worker
- a log/document summarizer
- a repo-search specialist
- a cheap PR-review assistant
- a preprocessing pipeline before escalation
- a second opinion engine
- a cache-friendly subagent in multi-agent workflows
And what matters is task routing.
A premium cloud model is overkill for a lot of work that happens in developer workflows:
- summarizing thousands of lines of logs
- writing or updating test scaffolding
- generating repetitive API client code
- searching large codebases for ownership or call paths
- making routine lint or type fixes
- updating READMEs
- converting TODOs into tickets
- producing low-risk first drafts of refactors
- scanning diffs for obvious issues
- extracting patterns from a monorepo
- triaging "what changed" after a failure
So the best way to position your local machine is as a cost-shaving, privacy-preserving execution substrate.
What consumer hardware can realistically do today
Let's stop being abstract and map this to real engineering work.
1. Codebase exploration
Modern open coding models are good enough to answer questions like:
- where is auth initialized?
- what touches this endpoint?
- what changed between these commits?
- which modules own retry logic?
- where is this config value consumed?
- summarize the dependency flow for this feature
- show me every place we build this payload
That is especially true when the harness is read-only and context-aware, like OpenCode's Explore subagent or a read-only plan mode.
2. Log triage and large-file summarization
This is a massively underrated use case.
It is often expensive in cloud tools because the input is huge and the reasoning demand is moderate.
Local is ideal when the job is:
- summarize 20 MB of logs
- cluster similar stack traces
- highlight suspicious latency spikes
- find repeated failure patterns
- correlate deployment timestamps with error bursts
This is exactly the kind of "high input, bounded output" workload where privacy and cost matter more than the last five percent of intelligence.
3. Repetitive coding tasks
There is real value in using local models for:
- writing tests around known behavior
- generating CRUD handlers
- adding typed wrappers
- converting callback code to async/await
- filling repetitive boilerplate
- mass-updating imports
- applying routine migration patterns
- drafting docs and comments
This is the actual work that teams burn hours on.
4. Repo-specific instruction following
Once you pair a local model with project instructions in AGENTS.md or CLAUDE.md, a lot of day-to-day work becomes much more stable:
- use this package manager
- run this test command first
- do not touch generated files
- prefer these conventions
- only edit files under this directory
- create a changelog entry whenever public APIs move
OpenCode explicitly leans into this with AGENTS.md initialization and reuse. Claude Code does the same through CLAUDE.md.
5. Multi-file bug fixing
Open models are increasingly capable here, especially when the bug is:
- localized
- reproducible
- supported by logs or stack traces
- backed by tests
Local is fine for first pass bug work, provided you still verify thoroughly.
6. Moderate refactors
- pulling utility functions into a shared module
- splitting a large component
- renaming across a package
- isolating side effects
- introducing structured error handling
7. Basic agentic workflows
This includes:
- call a tool
- inspect output
- decide next action
- call another tool
- generate patch
- run tests
- summarize results
Yes, local models can do this.
But only if the tool-call format is reliable and the server/runtime stack supports it cleanly.
Qwen-Agent even provides a wrapper around OpenAI-compatible endpoints to add function-calling behavior when the underlying endpoint does not provide it cleanly.
The state of open coding models in 2026 is better than many teams realize
Open coding models are now credible enough that ignoring them is a budgeting mistake.
A few examples worth noting:
Qwen family
Qwen has become impossible to ignore.
The newer Qwen3.6 35B-A3B model on Ollama is especially relevant to consumer hardware because it fits the 24 GB class and is explicitly framed around agentic coding and thinking preservation.
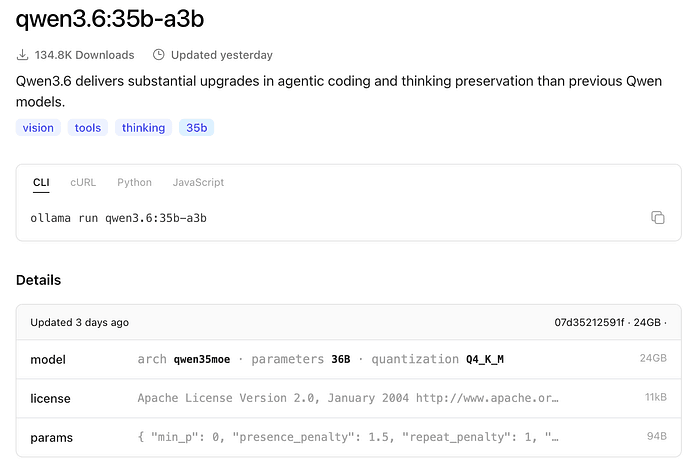
This is the category of model that makes 4090-class local setups genuinely useful.
GLM
The GLM directly targets agent workflows. GLM-4.7 is performant at multilingual agentic coding, terminal-based tasks, tool use, and UI quality, and shows stronger behavior in frameworks like Claude Code, Kilo Code, Cline, and Roo Code.
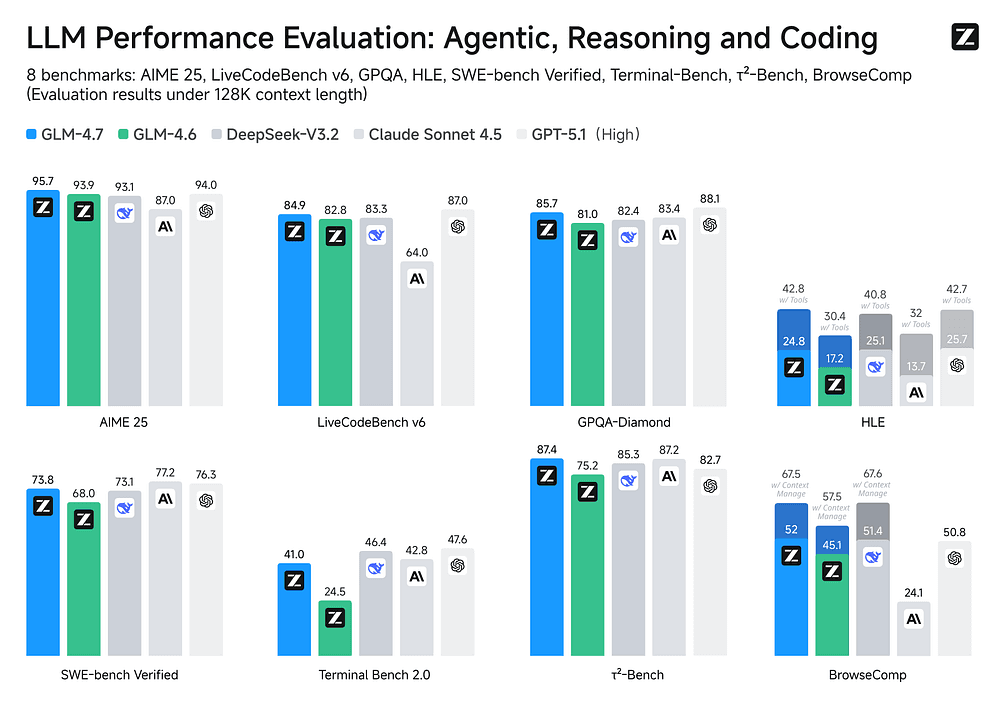
The interesting nuance here is that GLM is not only competing on raw benchmark numbers but also competing on how well it behaves inside agent scaffolds.
MiniMax
The MiniMax-M2.1 has a similar play, emphasizing robustness for coding, tool use, instruction following, long-horizon planning, and multi-language development.
The team also publishes benchmark tables that compare against premium closed models across SWE-bench, multilingual coding, Terminal-bench, and VIBE-style full-stack development.
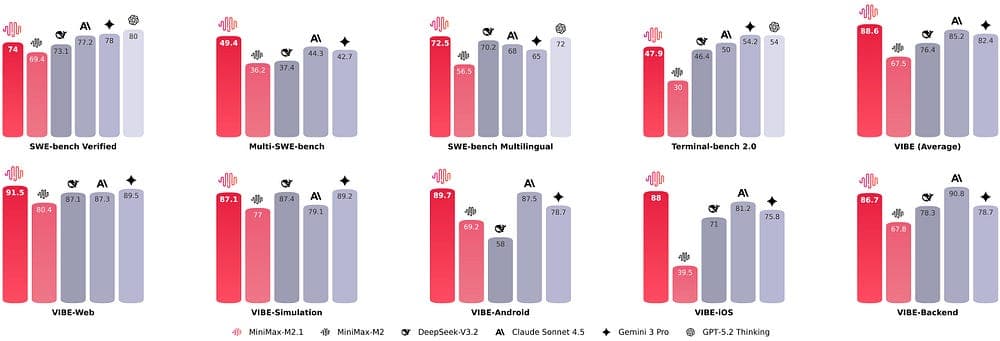
Again, the important point is not whether every published benchmark exactly predicts your use case.
Open models are increasingly being trained and evaluated as agentic development models, which matters a lot when you build real products.
Practical setup
I am going to give you three viable local patterns:
- Fastest path to value on a 4090 is via llama.cpp or Ollama
- Best Mac-native local workflow is with oMLX
- For more serious local serving for larger models, teams leverage vLLM with shared local serving and multi-user access
And here is my actual recommendation.
Think about:
- Which tasks are high-volume and low-risk?
- Which tasks are private enough that local matters?
- Which tasks are mostly context ingestion, summarization, or transformation?
- Which tasks can be validated cheaply with tests, linters, or diffs?
- Which tasks truly need top-tier reasoning?
Then route accordingly, that is how you win.
Start building systems where:
- local handles the heavy, boring, cheap work
- cloud handles the difficult, ambiguous, expensive thinking
- your harness keeps context lean
- your repo instructions keep behavior stable
- your engineers keep the final say
That is the practical future, which is already here.
- 1Frame the question as which parts of the agent loop can run locally, not whether local replaces frontier cloud models
- 2Separate the model, the runtime, and the harness: a disciplined harness can make a weaker local model outperform a bloated stronger one
- 3A 24 GB card like the RTX 4090 fits modern sparse MoE coding models and becomes a real engineering asset
- 4Buy an M5 Max 128 GB for capacity, mobility, and context headroom, not for frontier-level reasoning
- 5Local is strongest as a coprocessor: route high-volume, low-risk, private work locally and escalate hard reasoning to the cloud