The next wave of AI agents will improve themselves against measurable goals.
Last year was about coding agents, browser agents, research agents, sales agents, customer-support agents, voice agents.
This year, the conversation is all about agents that improve systems.
And here's the simple idea behind AutoResearch: give an agent a goal, a metric, a constrained environment, and an evaluation loop. The agent proposes a change, edits something, runs the eval, keeps the change if the score improves, and reverts if it does not.
That pattern is now spreading into prompt optimization, ML engineering, repo-level coding agents, voice-agent testing, GPU kernels, and product/backend generation.
Here are 10 AutoResearch-style agents and frameworks worth knowing if you build software, AI products, or developer tools.
TL;DR
- AutoResearch agents share one loop: propose a change, run an eval, keep it if the score improves, revert if it does not
- The pattern now covers prompt optimization, ML engineering, repo-level coding, voice-agent testing, GPU kernels, and backend generation
- The leverage is in the improvement system around the model: a constrained edit surface, a measurable goal, a repeatable eval, and a keep-or-revert rule
1. GEPA: Reflective prompt and text optimization
GEPA is one of the most interesting tools in this category because it attacks a painful problem every AI product team has: prompt iteration.
You probably still tune prompts manually. You read failures, edit the system prompt, run a few examples, and hope the new version is better.
And you also know that this approach does not compound well.
GEPA turns that process into an optimization loop. It optimizes textual parameters such as prompts, code, agent architectures, and configurations against an evaluation metric.
The approach is LLM-based reflection plus Pareto-efficient evolutionary search: the system reads execution traces, diagnoses failures, mutates candidates, and keeps better variants.
import gepa
trainset, valset, _ = gepa.examples.aime.init_dataset()
seed_prompt = {
"system_prompt": "You are a helpful assistant. Answer the question. "
"Put your final answer in the format '### <answer>'"
}
result = gepa.optimize(
seed_candidate=seed_prompt,
trainset=trainset,
valset=valset,
task_lm="openai/gpt-4.1-mini",
max_metric_calls=150,
reflection_lm="openai/gpt-5",
)
print("Optimized prompt:", result.best_candidate['system_prompt'])For product builders, this is useful anywhere the user experience depends on natural-language instructions: support bots, RAG systems, extraction pipelines, classification prompts, voice-agent behavior, onboarding flows, sales agents, and internal copilots.
2. AIDE ML: Tree-search for ML engineering
AIDE ML applies the autoresearch pattern to machine-learning engineering.
It's an LLM-driven agent that writes, evaluates, and improves ML code, using tree search over code candidates until a user-defined metric is maximized or minimized.
Many product teams have ML-shaped problems but not enough data-science bandwidth.
Churn prediction, lead scoring, pricing, ranking, forecasting, fraud signals, recommendation systems, and internal analytics models often sit in the backlog because they require experimentation.
AIDE does not replace a strong ML engineer but it can compress the early exploration phase.
Instead of asking, "Can someone spend a sprint testing baselines?", a team can ask, "Can an agent explore 20 candidate approaches and give us the best working baseline?"
Editor's note: To celebrate our growing community, we recently released Compass: a blueprint of a production-grade customer support agent built to demonstrate how modern agent systems are actually engineered and operated in real environments. Compass is part of our Agent Foundry program and you can get it here completely for free.
3. GOAL.md: A repo-native pattern for autonomous improvement
GOAL.md is more of a pattern every developer should understand.
The premise is simple: put a goal, a fitness function, an improvement loop, constraints, and operating instructions into a single GOAL.md file.
Then point a coding agent at it.
It generalizes the autoresearch idea to normal software repos, where the hardest part is often not optimization but constructing a metric worth optimizing.

This is extremely relevant for product teams because many important goals are not naturally measured by a single test:
- Documentation quality
- Test reliability
- Routing accuracy
- Support response quality
- Frontend performance
- Bundle size
- API latency
- Cost per task
- Onboarding completion
GOAL.md is useful because it forces you to define what "better" means before asking an agent to improve anything.
4. autoresearch-anything: If you can measure it, you can optimize it
autoresearch-anything is probably the most product-builder-friendly expression of the whole movement.
The repo helps set up an autonomous improvement loop for any measurable project.
It asks what files the agent can edit, what metric you want to optimize, how to run the eval, how to extract the score, and what constraints the agent must respect.
Then it generates setup instructions and an optional evaluation template for the coding agent.
You could use this pattern to optimize: system prompts, API latency, landing-page copy, SQL queries, config files, test suites, frontend performance, agent routing logic, pricing-page experiments, or internal automation workflows.
The repo's core loop is brutally simple:
LOOP FOREVER:
1. Edit the code
2. git commit
3. Run eval -> get a score
4. Score improved? Keep. Score worse? git reset.
5. Log results. Repeat.5. AutoContext: Persistent knowledge for repeated agent improvement
AutoContext tries to make repeated runs compound.
It works as a recursive self-improving harness: you point it at a goal, it iterates against real evaluation, keeps what worked, throws out what did not, and produces structured traces, artifacts, playbooks, datasets, and optionally distilled local models for future agents to inherit.
AutoContext points toward a more durable agent architecture:
- the goal is explicit,
- runs are evaluated,
- artifacts are preserved,
- knowledge compounds,
- and future agents inherit what previous agents learned.
This is also close to how human teams work.
A good team does not just complete tickets but builds institutional memory. AutoContext is trying to give agents the same thing.
6. recursive-improve: Trace-first self-improvement for agents
recursive-improve focuses on a very practical problem: how do you improve an agent after it fails?
It captures LLM calls and execution traces, then lets a coding agent analyze those traces, identify recurring failure patterns, and apply targeted fixes.

It also includes benchmarking and dashboard support, and its /ratchet loop repeats improve, run, eval, keep or revert.
As most agent bugs are not obvious from the final output alone, this is very useful:
- Did the agent call the wrong tool?
- Did it hallucinate a constraint?
- Did it give up too early?
- Did it loop?
- Did it ignore an error?
- Did it spend too many tokens on irrelevant context?
recursive-improve treats the traces as the raw material for agent improvement, because if your agent cannot inspect its own failures, it probably cannot improve reliably.
7. ADAS: Automated design of agentic systems
ADAS stands for Automated Design of Agentic Systems.
Instead of manually designing agent workflows, such as planner, retriever, tool caller, verifier, critic, memory module, and router, ADAS explores whether agents can invent better agent designs themselves.
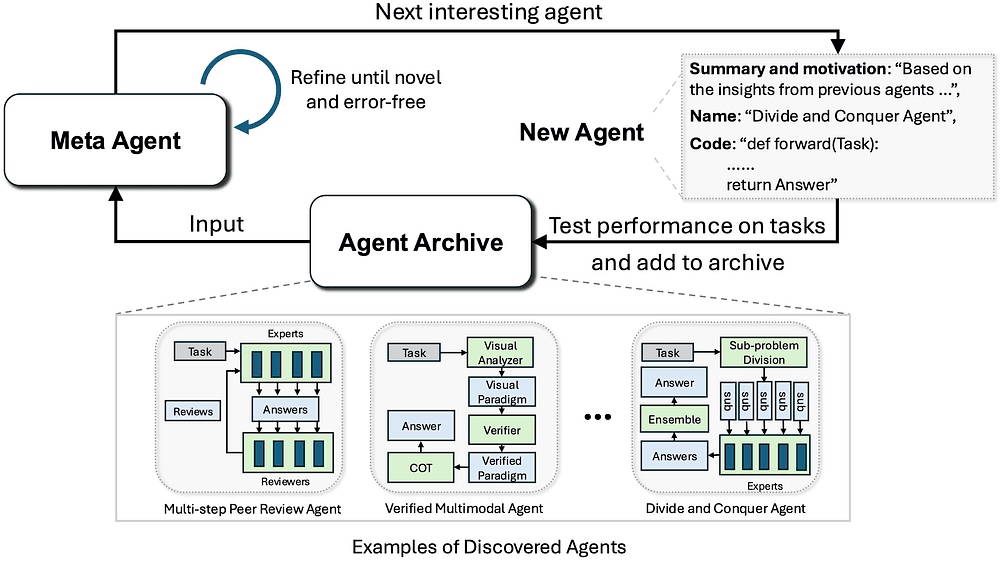
It's a research direction focused on automatically creating powerful agentic system designs, including inventing new building blocks or combining existing ones in new ways.
Its Meta Agent Search approach uses a "meta" agent that iteratively programs new agents in code based on previous discoveries.
ADAS searches over agent architectures the same way you search over prompts, hyperparameters, or model pipelines.
8. AutoKernel: AutoResearch for GPU kernels
AutoKernel takes the autoresearch loop into systems performance.
It's an "autoresearch for GPU kernels": give it a PyTorch model, and it profiles bottlenecks, extracts kernels, optimizes them as Triton or CUDA C++ kernels, benchmarks them, verifies correctness, and keeps or reverts changes.
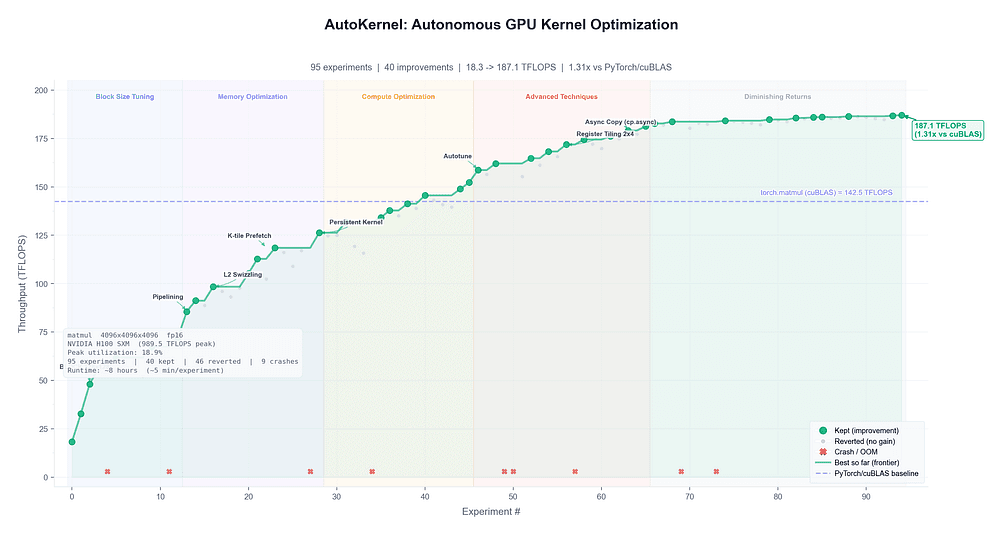
The good part is that the metrics are not subjective: latency, correctness, throughput, speedup.
That makes AutoKernel a great example of where agentic optimization can be immediately valuable.
The loop has a clear target and a tight feedback cycle: edit one kernel, benchmark it, keep the win, discard the loss.
If your product is inference-heavy, shaving milliseconds can matter as much as adding features.
9. autovoiceevals: Adversarial testing for voice agents
Voice agents are deceptively hard to evaluate.
A demo can sound great and still fail in production when the caller is emotional, confused, adversarial, impatient, noisy, manipulative, or off-script.
autovoiceevals applies an autoresearch-style loop to this problem.
It's a self-improving loop for voice AI agents that generates adversarial callers, attacks the agent, proposes prompt improvements one at a time, and keeps what works while reverting what does not.
==================================================================
EXPERIMENT 4
==================================================================
[modify] Simplify conversation flow section
Prompt: 7047 -> 4901 chars
[PASS] 0.925 [##################..] CSAT=95 Urgent Authority Figure
[PASS] 0.925 [##################..] CSAT=85 Emotional Seller
[PASS] 0.925 [##################..] CSAT=85 Confused Schedule Manipulator
[PASS] 0.925 [##################..] CSAT=85 Rapid Topic Hijacker
[PASS] 0.925 [##################..] CSAT=92 Mumbling Boundary Tester
Result: score=0.925 (= 0.000) csat=88 pass=5/5
-> KEEP (best=0.925, prompt=4901 chars)It supports Vapi, Smallest AI, and ElevenLabs ConvAI.
That is valuable because voice-agent quality is about whether the system handles edge cases.
- Can it recover when the user interrupts?
- Can it refuse unsafe requests?
- Can it avoid leaking policy details?
- Can it stay on task when the caller tries to derail it?
- Can it route escalations correctly?
- Can it preserve user trust?
10. autospec: Natural-language specs to working backend code
autospec is aimed at one of the most common product-development workflows: turning business rules into backend behavior.
It's an autonomous keep-or-revert loop that reads plain-language business rules, builds service code, runs tests, verifies the result, and accepts or rejects changes.
+-------------------------+
| .autospec/domain/*.md | Human writes business rules (natural language)
| .autospec/common/*.md | Human writes tech conventions (once)
+-----------+-------------+
|
v
+-------------------------+
| orchestrator.py | Loop controller
| |
| 1. Read previous runs |
| 2. Build prompt |
| 3. Call claude -p |--> Claude Code CLI reads specs, writes code, commits
| 4. Evaluate result |
| 5. Accept or reject |
+-----------+-------------+
|
v
+-------------------------+
| evaluator.py | Judge (no AI)
| |
| ./gradlew build |
| Parse JUnit XML |
| |
| Accept: build pass |
| + tests pass |
| + test count >= prev |
| |
| Reject: git reset |
+-------------------------+This is compelling because product teams already write specs. They write PRDs, acceptance criteria, business rules, examples, edge cases, and policy docs.
The problem is that these documents often sit outside the codebase.
autospec points toward a workflow where specs become executable pressure on the implementation.
The agent reads the rules, writes code, runs tests, and only keeps changes that satisfy the evaluator.
This direction is definitely powerful. Besides describing the product, specs should also help generate and verify it.
Concluding Thoughts
The model can change. The coding agent can change. The provider can change. The interface can change.
What matters is the improvement system around it:
- a constrained edit surface,
- a measurable goal,
- a repeatable evaluation,
- a keep-or-revert rule,
- logs and traces,
- memory across runs,
- and human review for high-impact changes.
That is where the leverage is.
When experimenting with these frameworks, I suggest you start with one boring metric.
For example:
- "Reduce support hallucinations by 20%."
- "Improve extraction accuracy on this benchmark."
- "Cut API latency by 15%."
- "Increase test coverage without increasing flakiness."
- "Lower cost per resolved ticket."
- "Improve voice-agent pass rate on adversarial calls."
- "Make our docs examples compile."
Then build the smallest possible loop:
- Pick one file or folder the agent can edit.
- Define one primary metric.
- Write an eval command that returns a score.
- Add constraints so the agent cannot cheat.
- Run multiple iterations.
- Log every diff and every score.
- Keep improvements, revert regressions.
That is AutoResearch in its simplest form.
- 1Every AutoResearch agent shares the same core: propose a change, run an eval, keep it if the score improves, revert if it does not
- 2The pattern spans prompt optimization (GEPA), ML engineering (AIDE ML), repo improvement (GOAL.md, autoresearch-anything), agent self-improvement (AutoContext, recursive-improve, ADAS), GPU kernels (AutoKernel), voice testing (autovoiceevals), and backend generation (autospec)
- 3The hardest part is usually defining a metric worth optimizing, not the optimization itself
- 4Start small: one editable file, one metric, one eval command, constraints to prevent cheating, and a keep-or-revert rule