Everybody is super excited about the upcoming Qwen3.7 release. I will share some experiments with the model in a second, but more importantly, Qwen3.7 Max Preview landed near the top of the hottest intelligence conversations across socials.
It's sitting around the very top tier on Artificial Analysis, roughly in the same neighborhood as GPT-5.5, Opus 4.7, and Gemini 3.1 Pro, the best frontier reasoning models available today.
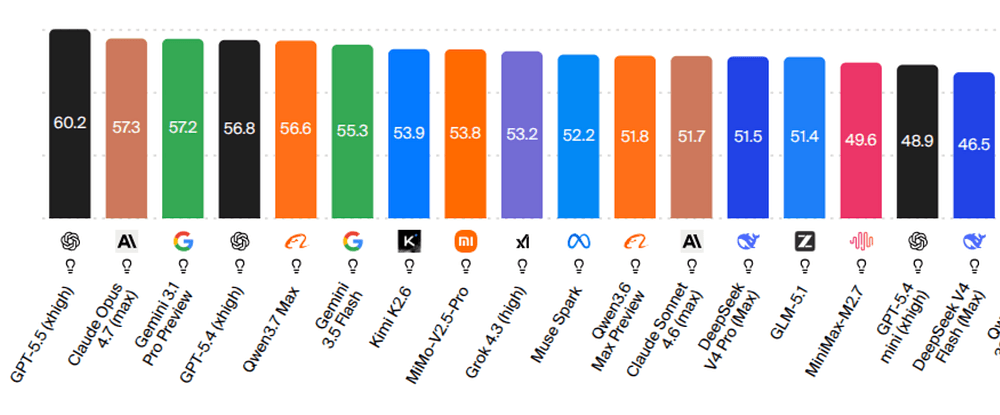
Arena also reported Qwen3.7 Max Preview at #13 overall in Text Arena, with category strength in Math, Expert, Software & IT, and Coding. Qwen3.7 Plus Preview showed up in Vision Arena, where Alibaba reached the #5 lab position by Arena's count.
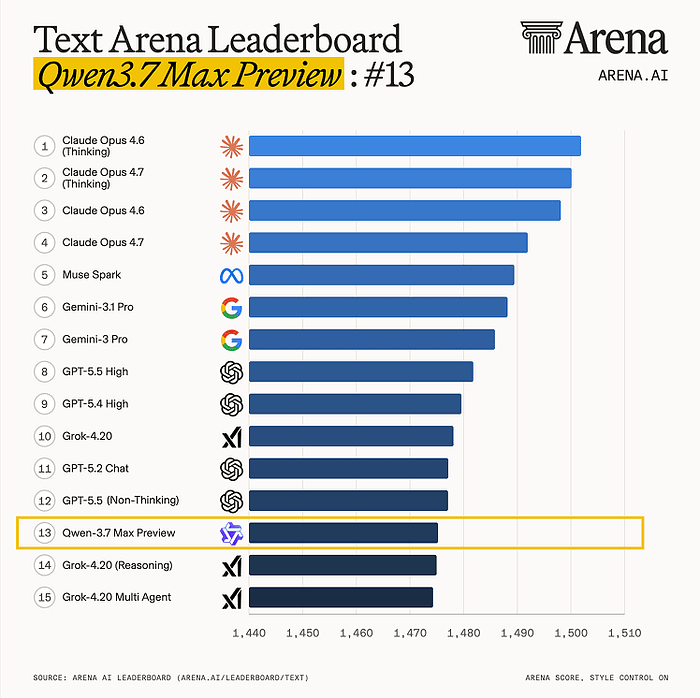
If you are building agentic SaaS, internal developer tools, code agents, AI support engineers, workflow automation, research assistants, or platform copilots, Qwen3.7 should push you to ask a harder question:
Can your stack absorb a new frontier model in one day without rewriting the parts of the product?
You want to be able to immediately migrate your existing model for releases like this. Have a closer look at the numbers.
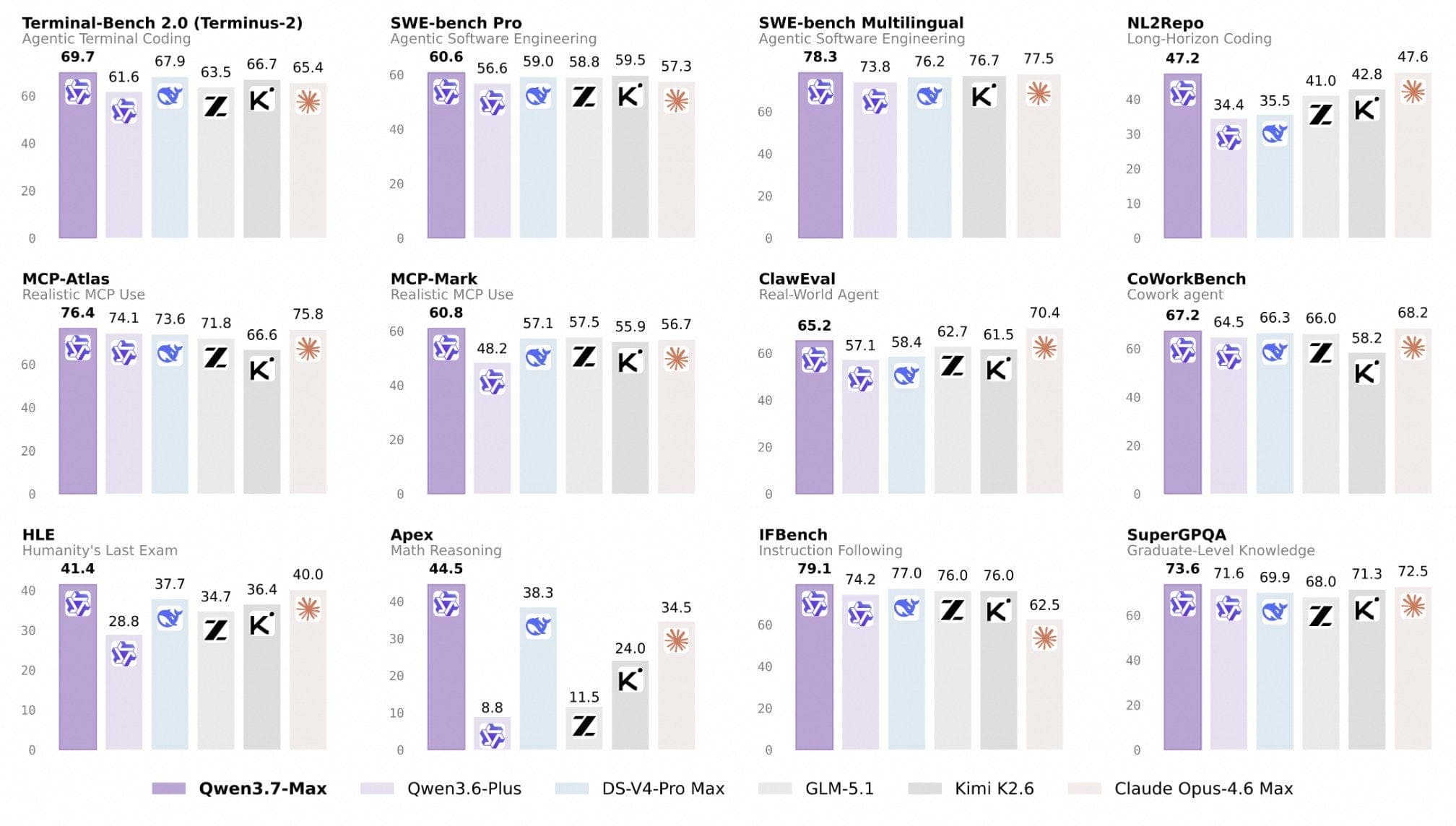
To me, outperforming GLM 5.1 is really huge.
What actually changed
We have had benchmark churn for years, but what's important here is that Alibaba's Qwen line is converging on the exact capability profile that agentic systems need:

However, the evaluation is mostly broken for agentic AI for most teams, because an agentic model should survive the following loop:
- User goal
- Clarify intent
- Inspect context
- Make a plan
- Call tools
- Read tool output
- Update plan
- Edit files
- Run tests
- Recover from failures
- Produce a useful final state
The reason Qwen3.7 is interesting is because it concentrates around the parts of the loop that used to break first: hard reasoning, coding, expert prompts, vision, and tool-ready workflows.
Qwen3.7 is a forcing function. It exposes whether your product architecture is model-portable, tool-portable, and evaluation-driven.
The product should care about capabilities:
- Can this model plan?
- Can it call tools reliably?
- Can it read long context without losing the thread?
- Can it use vision when the task needs vision?
- Can it recover when a tool call fails?
- Can it produce patches that pass tests?
- Can it explain uncertainty without hallucinating authority?
- Can it run inside the permission model we require?
That is clearly the right abstraction that many teams miss.
Why Qwen3.7 is different from another model launch
Qwen3 is a family with dense and Mixture-of-Expert models ranging from 0.6B to 235B parameters, with a unified framework for thinking and non-thinking behavior.
There are hybrid thinking modes, multilingual support, and improved agentic capabilities, including MCP support.
For example, Qwen3-Coder-480B-A35B-Instruct is a 480B-parameter MoE model with 35B active parameters, native 256K context, and extension to 1M context with extrapolation methods.
It was explicitly framed around agentic coding, browser use, tool use, and long-horizon reinforcement learning.
The same post introduced Qwen Code, an open-source terminal coding agent adapted for Qwen-Coder models.
Then Qwen3.6-27B made the local path more interesting, which is a 27B model with a vision encoder, native 262,144-token context, extension up to roughly 1,010,000 tokens, and support for vLLM, SGLang, KTransformers, Transformers, and Qwen-Agent workflows.
Now Qwen3.7 appears in the same family arc:
- Qwen3: hybrid reasoning and agentic foundation
- Qwen3-Coder: code-agent specialization and Qwen Code
- Qwen3.6-27B: strong open-weight local agent/coding option
- Qwen3.7 Max/Plus Preview: frontier-style reasoning, coding, expert, and vision signals
It means Qwen3.7 is a new candidate foundation for agentic workflows.
Editor's note: To celebrate our growing community, we recently released Compass: a blueprint of a production-grade customer support agent built to demonstrate how modern agent systems are actually engineered and operated in real environments. Compass is part of our Agent Foundry program, and you can get it here completely for free.
The early experiments are more useful than the leaderboard
The first experiment gave Qwen3.7 Plus Preview an image with a home on the left and a car wash on the right, asking whether to walk or drive.
The model read visual and textual cues, initially leaned one way, then corrected to the right answer.

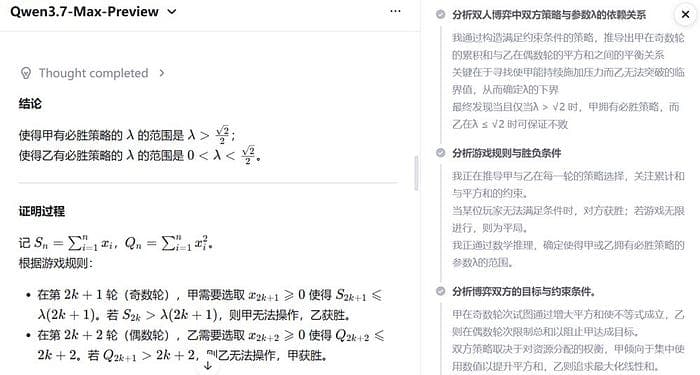
The second experiment fed Qwen3.7 Max Preview a 2025 IMO math problem.
It reportedly analyzed, verified, and reached the correct answer in four minutes. Hard math is a proxy for long, brittle reasoning chains.
The third experiment asked Qwen3.7 Max Preview to build a Pomodoro app and export it as an EXE.
It could not export the EXE, gave manual packaging guidance, hit an initial launch failure, identified a Tkinter color transparency bug, fixed the app, and ended with a functional but plain-looking result.
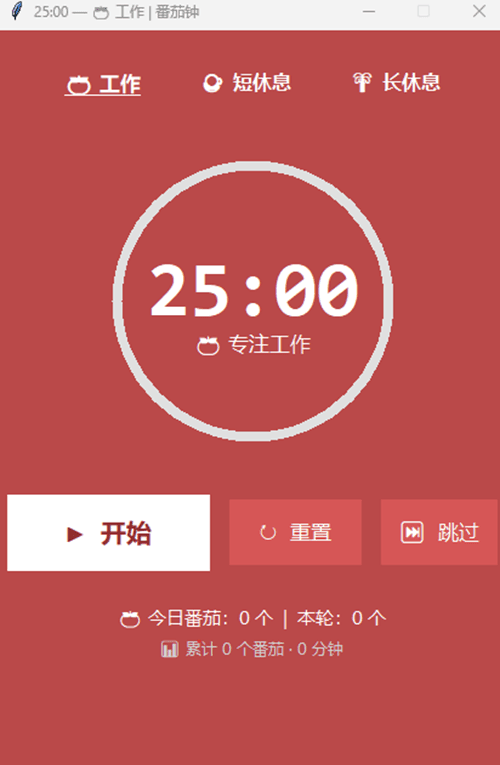
This is probably the most realistic one, because real coding agents often fail at the edges:
- Dependency mismatch
- Packaging issue
- Runtime error
- Bad UI polish
- OS-specific behavior
Qwen3.7's behavior in this case is exactly the kind of loop a production harness needs to amplify.
The Qwen3.7 adoption plan
I'm wondering if I can use Qwen3.7 as my daily driver. Here's my one-week evaluation plan.
- Set up the OpenAI-compatible client, run simple text prompts, run streaming, then log latency, output length, and cost metadata if available.
- Run read-only exploration on 2-3 repositories and measure whether the model correctly identifies architecture, tests, and risky areas.
- Pick three real bugs that are already fixed in my history, reset the repo to before each fix, and ask the agent to diagnose and patch, then score diff quality and test behavior.
- Use screenshots from real support tickets, UI bugs, or design specs, and evaluate whether the vision model can connect visual symptoms to code areas.
- Expose one safe internal MCP server and use read-only tools first, then test whether the model can answer questions that require tool use.
These tests will give me a pretty good idea of its capabilities.
Concluding thoughts
Models are becoming more agent-native, and their releases now affect:
- Prompt design
- Tool schemas
- Context strategy
- Permission modes
- Eval suites
- Local/cloud routing
- Cost models
- Security policies
- Developer workflows
This is pretty comprehensive, and Qwen3.7 is pushing on the full combination.
I will post more when I'm able to run exhaustive tests on my use cases.
- 1Qwen3.7 Max Preview sits in the frontier tier on Artificial Analysis, near GPT-5.5, Opus 4.7, and Gemini 3.1 Pro
- 2Arena placed it at #13 overall in Text Arena with strength in Math, Expert, Software & IT, and Coding
- 3The Qwen3 family converges on the agentic capability profile: reasoning, coding, vision, long context, and MCP-ready tool use
- 4Early experiments show realistic agent behavior, including recovering from a packaging failure and a Tkinter bug
- 5The real question for teams is whether their stack can absorb a new frontier model in a day without rewriting the product