Before answering this in depth, please think about the following question:
What part of the agent loop is your hardware supposed to accelerate?
(If you need a TL;DR, you can scroll to the bottom.)
A chat UI and an agentic system stress hardware differently.
An agentic coding system cares about repeated long-context reads, tool calls, cache churn, parallel background workers, retrieval, subprocesses, test runs, container work, and sometimes many independent agents trying to use the same model server at once.
Rather than comparing "Mac versus NVIDIA" or "unified memory versus VRAM", you should focus on the workload decomposition problem.
Before we start the hardware discussion, please do not buy hardware by comparing one headline tokens-per-second number.
Map your agent workflow to four bottlenecks:
- Model fit
- Prefill latency
- Decode throughput
- Concurrent serving behavior
Once you do that, the debate gets much less emotional and much more useful.
The Benchmark That Triggers The Debate
The most useful part of the recent M5 vs DGX Spark vs Strix Halo vs RTX PRO 6000 discussion is the benchmark design.
The MMBT fleet study did something many hardware comparisons skip: it tried to hold model bytes and engine source fixed.
The main fleet benchmark tested four host classes:

The study used two Q8 GGUF models:

The main grid was:
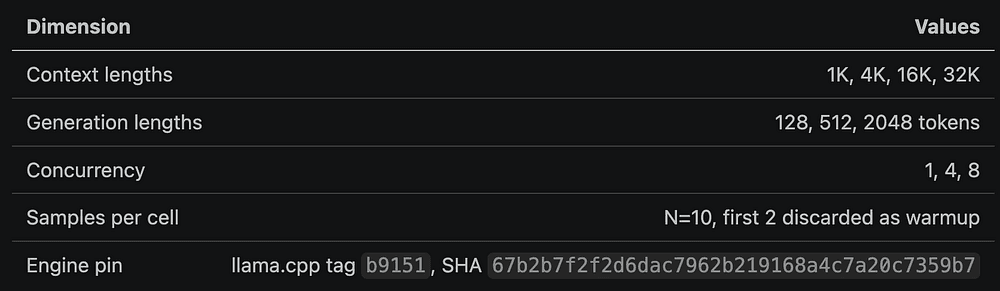
This is very important because local benchmarks become misleading fast when they mix quantization formats, runtime engines, and backend maturity.
- 4-bit AWQ model under vLLM is not the same experiment as a Q8 GGUF model under llama.cpp.
- MLX run on Apple Silicon is not the same experiment as a Metal llama.cpp run.
- Dual-card RTX workstation is not the same operating point as a single-card row.
MMBT explicitly separates these cases. Its aggregate/canonical-headline.csv table is the canonical same-source-SHA cross-host comparison, and appendix rows, including vLLM/FP8 and dual-card rows, live separately so readers do not accidentally mix apples and oranges.
Exactly the kind of discipline hardware discussions need.
The First Principle
A coding agent spends much of its time reading context, not writing final prose. It repeatedly ingests repository snippets, file trees, diffs, compiler output, test failures, linter messages, dependency manifests, issue descriptions, and prior tool-call state.
Every turn can look like this:
- Read repo context.
- Decide which files matter.
- Call tool.
- Receive tool output.
- Re-read expanded context.
- Make another tool call.
- Run tests.
- Parse failure.
- Patch code.
- Re-run tests.
That loop creates three different latency surfaces.
- Prefill is how fast the model reads the prompt. In an agent, the prompt is often the entire working memory of the agent loop. Long prompts turn prefill into a first-class bottleneck.
- Decode is how fast the model writes new tokens. This matters for long answers, code generation, and patches.
- TTFT, or time to first token, is the user-visible delay before anything starts streaming. At long context, TTFT is usually dominated by prefill.
A simple mental model is:
def estimate_latency(prompt_tokens, output_tokens, prefill_tps, decode_tps):
prefill_seconds = prompt_tokens / prefill_tps
decode_seconds = output_tokens / decode_tps
return prefill_seconds + decode_secondsThat function is obviously incomplete. It ignores scheduling, cache hits, tool execution, network overhead, runtime batching, speculative decoding, prefix reuse, and queueing delay, but it is useful because it forces you to stop treating "tok/s" as a single number.
For an agentic coding product:
- A machine that decodes fast but reads long prompts slowly can feel worse than expected.
- A machine that decodes slowly but has predictable first-token latency might be fine for batch summarization.
- A machine with great single-user numbers can collapse under multiple parallel agents if the serving engine does not batch well.
The right hardware depends on where your agent spends time.
The Hardware Reality In One Table
The MMBT canonical 27B Q8 single-user table gives a clean starting point.
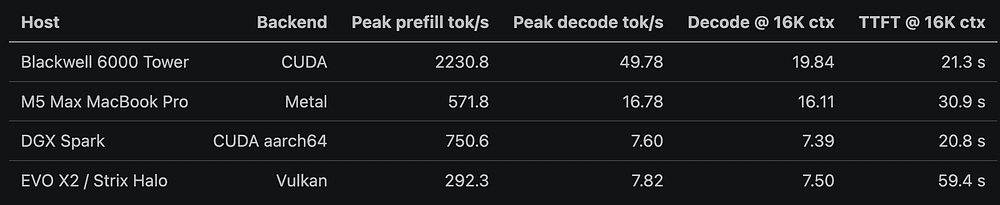
This table already tells a more useful story than "M5 beats Spark" or "CUDA wins."
The RTX PRO 6000 system wins peak single-user prefill and peak single-user decode, which should not surprise anyone.
The official NVIDIA RTX PRO 6000 Blackwell Workstation Edition spec lists 96 GB GDDR7 ECC memory, 1792 GB/s memory bandwidth, and 600 W max power consumption, which is a very different class of memory subsystem from laptop or mini-PC unified memory.
The M5 Max is strong for what it is.
Apple's M5 Max MacBook Pro technical specs list up to 128 GB unified memory and 614 GB/s memory bandwidth on the 40-core GPU configuration.
In the MMBT 27B Q8 row, it decodes much faster than Spark and Strix Halo at the short-context peak, and at 16K context it is surprisingly close to the RTX PRO 6000's measured llama.cpp CUDA decode rate.
The DGX Spark is not a raw single-node decode monster in this benchmark.
NVIDIA's DGX Spark hardware guide lists 128 GB LPDDR5x unified memory, a 256-bit interface, 273 GB/s memory bandwidth, a 20-core Arm CPU, ConnectX-7 networking, and FP4 support.
Spark is positioned as a desktop AI system for prototyping, fine-tuning, inference, and migration into NVIDIA infrastructure, which is also a different value proposition from "fastest local chat box."
Strix Halo is the budget-capacity story.
AMD's Ryzen AI Max+ 395 official specs list 128 GB max memory, a 256-bit LPDDR5x memory subsystem, and Radeon 8060S graphics with 40 graphics cores.
In MMBT, the tested EVO X2 gives you large unified memory at a lower price point, but the Vulkan row shows slow prefill and the small chassis shows thermal constraints.
So the top-level reading is:

There is no permanent winner here, only operating points.
Why Memory Bandwidth Shows Up Everywhere
Single-stream LLM decode is often memory-bandwidth-bound.
For each new token, the system repeatedly streams model weights and attends over KV state. Compute can sit idle if memory cannot feed it fast enough.
Official and benchmark-relevant bandwidth numbers look like this:

For dense Q8 single-user decode, this gives you the rough curve you would expect, but agentic systems complicate the picture.
At short context, the RTX PRO 6000 is far ahead. At 16K context, the MMBT llama.cpp CUDA row narrows: RTX PRO 6000 is around 19.84 tok/s while M5 Max is around 16.11 tok/s. At 32K context, the findings show the M5 row holding around 16 tok/s while the Tower row drops further under that specific llama.cpp CUDA setup.
That does not mean M5 magically has a faster GPU than the RTX PRO 6000. It means long-context behavior is runtime-sensitive.
The MMBT findings explicitly call out that multi-user and some long-context comparisons are engine-bound under llama.cpp and need separate vLLM, TensorRT-LLM, or MLX follow-up work.
Hardware specs explain a lot, but runtime implementation explains the rest.
Editor's note: Thank you for your support and for building alongside our articles. We recently released Compass: a blueprint of a production-grade customer support agent built to demonstrate how modern agent systems are actually engineered and operated in real environments. Compass is part of our Agent Foundry program and you can get it here completely for free.
Do Not Ignore Prefill
Agentic developers should care about prefill more than casual chat users do.
A coding agent can issue dozens of turns. Each turn may include thousands or tens of thousands of tokens of accumulated context. If the system has poor prefix caching or frequent cache eviction, the same repository context can be reread over and over.
This is where "it streams fine once it starts" is not enough.
In the 27B Q8 single-user row:
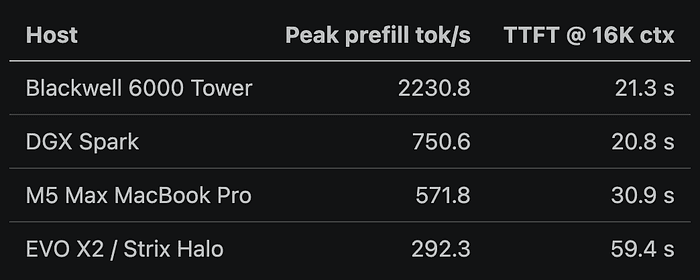
The Spark is interesting here. It loses to the M5 on decode in this dense Q8 row, but it has better 16K TTFT in the benchmark.
For tool-heavy agents, that can matter more than the raw streaming speed after the first token.
- If your workflow is "give the model a long prompt, ask for a short decision, call a tool, repeat," then prefill and TTFT dominate. Think PR triage, RAG over policy docs, structured extraction, routing, or codebase reconnaissance.
- If your workflow is "give the model a moderate prompt and ask it to generate a long file," decode matters more. Think long code generation, migration scripts, documentation, or test scaffolds.
- If your workflow is "run ten agents in parallel," neither single-user prefill nor single-user decode is enough. You need a real serving benchmark with batching, queueing, and cache behavior.
Concurrency Is The Trap
The most dangerous mistake is to extrapolate single-user numbers into multi-user agent serving.
The MMBT is also careful here. It ran concurrency cells, but it explicitly holds cross-host multi-user conclusions because llama.cpp's --parallel N behavior becomes an engine-level binding constraint at long context.
That is the right call.
Concurrent agent workloads are not just "single-user tok/s multiplied by N." They depend on:
- Continuous batching
- KV cache allocation
- Prefix caching
- Tool-call parser correctness
- Queue discipline
- Per-request context lengths
- Whether the model is dense or MoE
- Whether tensor parallelism or pipeline parallelism is efficient for the model
- Whether the runtime can keep the hardware saturated without pathological cache eviction
This is where vLLM enters the discussion.
vLLM highlights continuous batching, prefix caching, chunked prefill, PagedAttention for KV memory management, optimized attention kernels, tensor/pipeline/data/expert/context parallelism, tool calling, reasoning parsers, and an OpenAI-compatible API server.
That feature set is built for serving.
llama.cpp is extremely useful because it runs almost everywhere. It supports local inference across a wide range of hardware, including Apple Silicon via Metal, x86 acceleration, CUDA, Vulkan, SYCL, and CPU+GPU hybrid inference.
That makes it a great cross-platform comparison tool, but a cross-platform comparison tool is not automatically the best production serving engine for high-concurrency agents.
For a developer team, the practical rule is:
Use llama.cpp to understand portability and baseline hardware behavior. Use vLLM, TensorRT-LLM, SGLang, MLX, or another optimized serving stack to evaluate production concurrency.
A local coding assistant for one developer can run happily on a single-user runtime. A team-wide agent service needs a serving engine.
Why DGX Spark Is Misunderstood
DGX Spark looks weak if you reduce it to one Q8 decode row, but that is the wrong lens.
NVIDIA emphasizes the NVIDIA software stack, 128 GB unified system memory, FP4 support, fine-tuning up to 70B parameter models, inference with large models, and ConnectX networking that can connect two Spark systems for larger models.
The hardware guide lists two QSFP network connectors and ConnectX-7, which enables connecting two DGX Spark systems to work with AI models up to 405B parameters.
That does not make Spark faster than an RTX PRO 6000 in this single-node Q8 benchmark, but it does make Spark a developer appliance for teams that want to stay inside NVIDIA's stack, test local fine-tuning, validate deployment workflows, and potentially cluster two units.
For agentic AI product teams, Spark makes sense when the following are true:
- You need CUDA compatibility more than peak local chat speed.
- You care about FP8/FP4 model paths.
- You want a compact Linux appliance, not a laptop.
- You may connect multiple units.
- You are prototyping workflows that later migrate to NVIDIA cloud or datacenter GPUs.
- You want to fine-tune or experiment locally without building a full workstation.
Why The M5 Max Is Also Misunderstood
In the MMBT benchmark, the 128 GB M5 Max MacBook Pro is genuinely strong for single-user local inference. It has enough unified memory to run large GGUF models, its decode numbers are healthy, and it held up thermally better than many people expected.
For small teams, the Mac has obvious advantages:
- It is a normal developer laptop.
- It is portable.
- It does not require a server room.
- It can run large local models that do not fit on common 24 GB cards.
- It avoids the complexity of a discrete GPU workstation.
- It can be a good single-developer local assistant box.
MLX is improving. llama.cpp Metal works, and there are local serving options.
But if your agentic product depends on CUDA-specific kernels, vLLM production behavior, TensorRT-LLM, NVIDIA quantization paths, or training/fine-tuning workflows that assume NVIDIA GPUs, the Mac is not a drop-in replacement.
The M5 Max is a great local inference machine when you value memory capacity, portability, and single-user convenience. It is a weaker choice when you are building a shared multi-agent serving platform.
Why The RTX PRO 6000 Is Still Important
It is fashionable to say the RTX PRO 6000 is overpriced, but it is also incomplete.
It has 96 GB GDDR7 ECC memory and 1792 GB/s memory bandwidth. In the MMBT single-user 27B Q8 row, the Blackwell 6000 Tower wins peak prefill and peak decode.
But the real reason RTX-class hardware matters for agentic AI is the combination of:
- CUDA
- vLLM maturity
- Tensor parallel serving options
- Better high-batch throughput
- Fine-tuning and training support
- Diffusion and multimodal workloads
- Multi-GPU workstation scaling
- Tooling that lands first in the NVIDIA ecosystem
If your agentic product is a shared local service for a team, an RTX PRO 6000 is closer to "infrastructure" than "a fast local toy."
A platform team running many background agents, eval jobs, synthetic data generation, PR reviewers, embedding rerankers, and tool-using model workers can actually use the GPU.
This is the same distinction cloud teams already understand: GPU is expensive when idle but cheap when it is saturated by useful work.
So here is the practical buying logic.

A second decision table is more useful for agentic systems:

That table is the one you should take into procurement discussions.
The Bottom Line
For developer-focused agentic AI, the hardware ranking is a mapping:
- RTX PRO 6000 class hardware is the serious local AI infrastructure choice when you need CUDA, high prefill, high decode, high-batch serving, fine-tuning, and future workload flexibility.
- M5 Max is a very strong single-user large-memory inference machine, especially for developers who want local models in a portable machine and do not need CUDA-first workflows.
- DGX Spark is best understood as a compact NVIDIA development appliance with unified memory, FP4/FP8 direction, fine-tuning positioning, and clustering support, not as the fastest Q8 llama.cpp decode box.
- Strix Halo is the budget large-memory experiment box. It is useful, but in this benchmark its prefill and chassis behavior make it a poor default for low-latency agentic serving.
Agentic AI turns model inference into systems engineering.
You need to think about model fit, prefill, decode, TTFT, batching, tool-call parsers, KV cache behavior, thermal stability, power, and reproducibility.
That is why the best local AI hardware discussion is:
Which bottleneck am I buying my way out of?
Answer that, and the hardware decision becomes much easier.
- 1Map your agent workflow to four bottlenecks first: model fit, prefill latency, decode throughput, and concurrent serving behavior, instead of chasing one tokens-per-second number.
- 2The RTX PRO 6000 wins peak single-user prefill and decode and is the infrastructure choice when you need CUDA, high-batch serving, and fine-tuning.
- 3The M5 Max is a strong portable single-user large-memory machine, but not a drop-in replacement for CUDA-first or shared multi-agent serving.
- 4DGX Spark is a compact NVIDIA development appliance with unified memory, FP4/FP8 paths, and clustering, not the fastest Q8 decode box.
- 5Single-user numbers do not predict multi-user serving; use llama.cpp for portability baselines and vLLM, TensorRT-LLM, SGLang, or MLX for production concurrency.