There's a moment in nearly every retrieval-augmented generation tutorial where the hard questions disappear.
You chunk the documents, embed the text, wire up the retriever—and then comes the handoff: store the vectors in a database.
It is usually presented as an implementation detail. Something you can tuck behind an API and forget about.
In practice, that assumption breaks quickly.
Because the instant retrieval leaves your application and becomes a separate service, you inherit a new class of costs: network latency, serialization overhead, connection management, extra infrastructure, and another system that needs to stay healthy under load.
None of that is free. In real production pipelines, I've seen the retrieval layer become the slowest part of the stack—not generation, not reranking, but the supposedly lightweight lookup step. GPUs sit idle while a vector query makes a round-trip across the network.
That is why Alibaba's newly open-sourced zvec is interesting.
At a high level, zvec takes aim at a category mistake the industry has quietly normalized: treating vector search as something that must live in a separate server.
Instead, zvec runs inside your application process. The idea is simple, but the implications are larger than they first appear.
On the public VectorDBBench leaderboard, zvec posts more than 8,000 QPS on the Cohere 10M workload, comfortably ahead of the previous top entry while also cutting index build time.
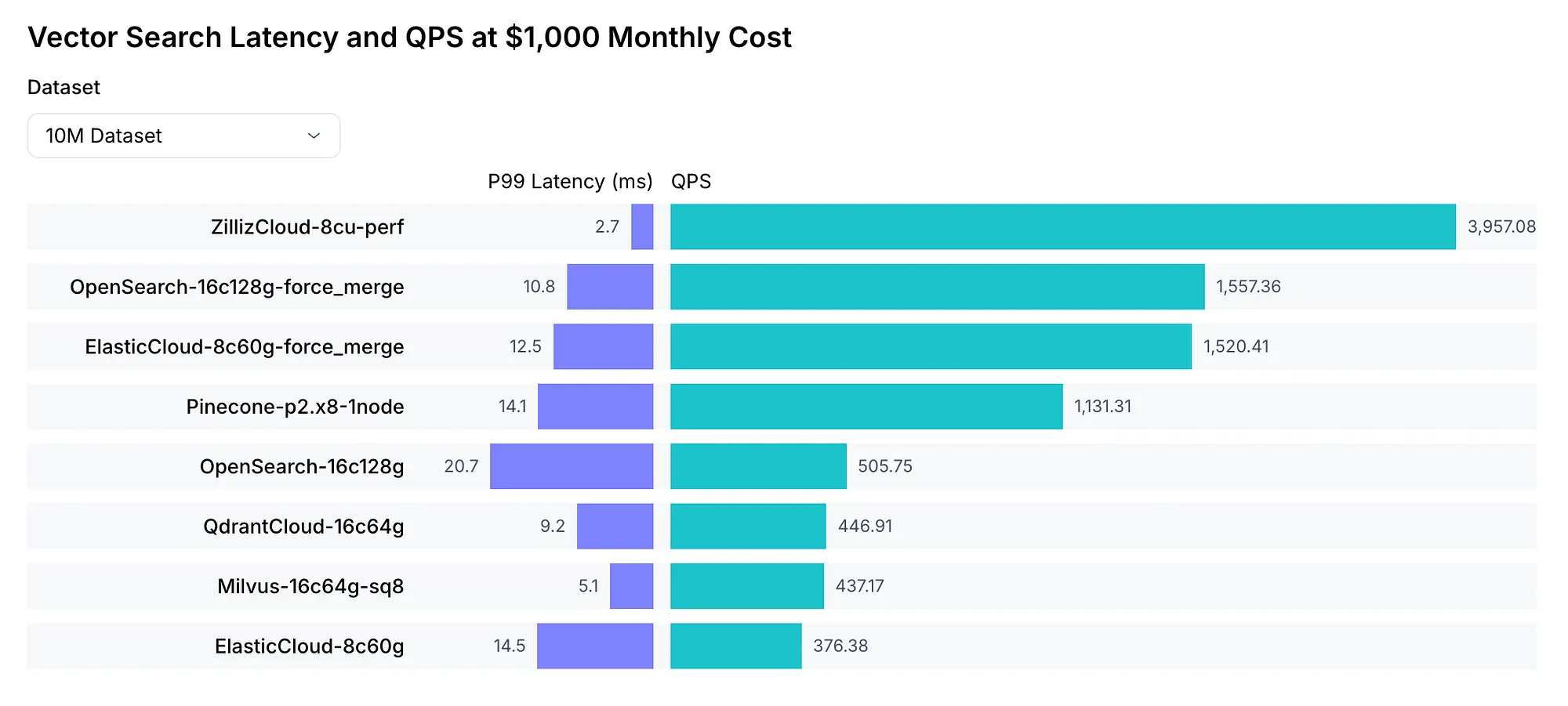
More interesting, though, is what happens when you stop comparing it to raw indexing libraries and compare it to the tools people actually use in application stacks. In an independent healthcare-oriented benchmark, the meaningful matchup was not “zvec versus FAISS,” because FAISS is not trying to be a database. It was “zvec versus ChromaDB,” and on filtered retrieval, zvec reportedly operated in the sub-millisecond range while ChromaDB sat an order of magnitude higher.
That distinction matters.
A lot of developers still end up choosing between two unsatisfying extremes.
On one side, you have ANN libraries like FAISS: incredibly fast, but bare-metal tools rather than full databases. They give you retrieval, but not the database ergonomics most applications actually need—persistence, metadata filtering, recovery, storage semantics, and a clean operational story.
On the other side, you have service-based vector databases like Milvus or Pinecone: powerful and feature-rich, but heavier than many workloads require, especially when you are building desktop software, internal tools, edge deployments, mobile-side systems, or local AI applications.
What has been missing is the middle ground: something with real database behavior, but without the operational footprint of a separate distributed service.
That is the lane zvec is trying to own.
It presents itself almost like SQLite for vector search: embedded, local, persistent, and designed to disappear into the application rather than force the application to reorganize itself around infrastructure. Under the hood, it is built on Proxima, Alibaba's production vector engine, which already powers billion-scale systems internally. So this is not a toy wrapper around a research prototype. It is an attempt to package production-grade vector retrieval into a form factor developers can actually ship with.
There are other reasons it stands out beyond headline throughput. zvec supports dense and sparse vectors, hybrid scalar-plus-vector queries, multi-vector retrieval, and built-in reranking strategies like weighted fusion and RRF. Just as importantly, it takes resource control seriously, something most vector database discussions barely touch. It exposes explicit mechanisms for memory limits, streaming writes, mmap-based access, and thread budgeting, which makes it unusually relevant for constrained environments and edge deployments where “just give it more RAM” is not an answer.
That last point may end up being one of its most important differentiators.
Because a lot of teams are no longer building only cloud-native RAG systems. They are building local copilots, embedded assistants, on-device search, and agentic workflows that need retrieval to be fast, predictable, and self-contained. In those environments, resource governance is not a luxury feature. It is the difference between software that feels native and software that feels fragile.
In this piece, I want to unpack where zvec actually fits in the current vector database landscape, why its in-process design matters more than most benchmark charts can capture, where it appears to outperform existing options, and where the tradeoffs still deserve scrutiny before adoption.
TL;DR
Effort: 12 min read- zvec is an embedded, in-process vector database — think SQLite for vectors.
- Built on Proxima, Alibaba's production vector engine that runs their own billion-scale systems.
- 8,000+ QPS on VectorDBBench (Cohere 10M), more than 2x the previous leader.
- Supports dense + sparse vectors, hybrid scalar-vector search, multi-vector retrieval, built-in reranking (weighted fusion and RRF).
- Explicit resource governance: 64 MB streaming writes, mmap mode, hard memory limits, configurable thread budgets.
- Apache 2.0 licensed. pip install zvec. Python 3.10-3.12 on Linux x86_64, Linux ARM64, macOS ARM64.
- - Understand where zvec fits in the vector DB landscape
- - Know when to use it vs. FAISS, ChromaDB, Milvus, or pgvector
- - Be able to evaluate it for your own RAG or agent workloads
What Is zvec, Exactly?
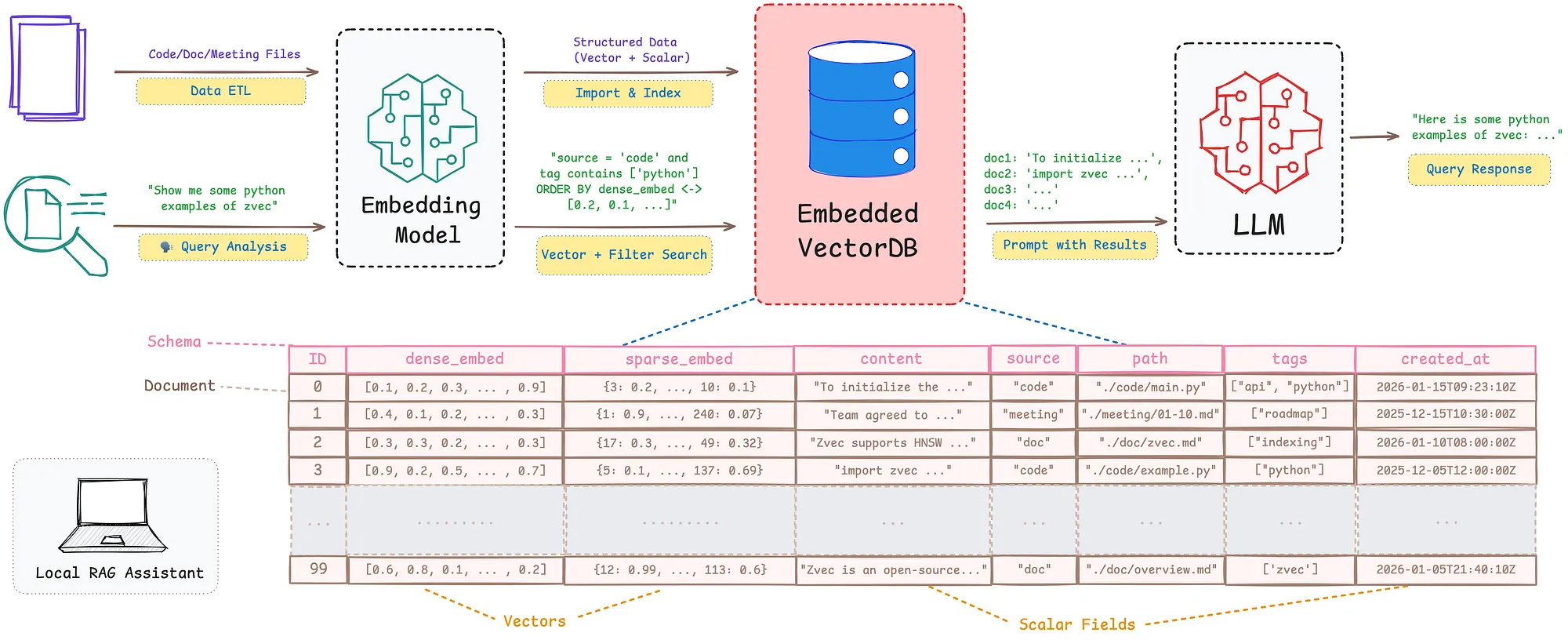
zvec is an open-source, embedded, in-process vector database released by Alibaba's Tongyi Lab under the Apache 2.0 license. The mental model is: SQLite, but for vectors.
It is built on Proxima, Alibaba Group's production-grade vector search engine — the same engine that powers their own billion-scale internal systems for search, recommendation, and advertising. zvec wraps Proxima with a simpler Python API and an embedded runtime. You pip install zvec, define a schema, and you are running vector search inside your application process.
zvec at a Glance
In-process library
Proxima — Alibaba's battle-tested production vector engine.
C++ core (81.3%), Python SDK. SWIG bindings.
Linux x86_64, Linux ARM64, macOS ARM64. Python 3.10–3.12.
HNSW for vectors, inverted indexes for scalar filtering.
Apache 2.0. 8.1k GitHub stars, 453 forks as of March 2026.
The "SQLite of vector databases" framing is an architectural statement. SQLite runs in your process, persists to a file, needs no configuration, and is the most deployed database engine in the world precisely because of that simplicity. zvec makes the same bet for vector workloads: that most applications need vector search plus metadata filtering, not a distributed cluster.
Honest Benchmarks: Where zvec Wins (and Where It Doesn't)
Let me start with the official numbers before getting to the independent ones, because together they tell a more complete story.
Official VectorDBBench results
zvec was benchmarked using VectorDBBench, an open-source framework widely adopted in the vector database community, on standardized datasets:
- Cohere 10M (10 million 768-dimensional vectors): zvec achieved 8,500+ QPS with sub-millisecond latency — more than 2x the previous leaderboard leader (ZillizCloud) on comparable hardware and matched recall.
- Index build time: Approximately 1 hour for 10 million vectors on a g9i.4xlarge instance (16 vCPU, 64 GiB RAM), which also represents a substantial improvement over competitors.
These are systems-engineering numbers: SIMD-optimized distance computation, cache-friendly memory layouts, multi-threaded execution, and CPU prefetching. The performance comes from the Proxima engine, not merely from being in-process.
Independent benchmarks: the nuanced picture
This is where it gets more interesting. A developer building semantic patient search for healthcare (ABC on X) ran a 4-way benchmark — FAISS, zvec, ChromaDB, NumPy — on 10,000 patient records with clinical embeddings. The results are honest and worth internalizing:
Independent 4-Way Benchmark (10K clinical vectors)
- + Faster than zvec at raw search (expected — FAISS does less)
- + Minimal overhead for pure ANN
- - No persistence — kill the process, lose the index
- - No metadata filtering, crash recovery
- + Beats zvec at 10K vectors (HNSW overhead is not worth it at this scale)
- - Projects to 38x slower than zvec at 1M vectors
- - No persistence, filtering, database semantics
- + Data persists automatically
- + Metadata filtering (age, severity, department) fused natively into search
- + 0.5ms filtered queries
- + Patient data never leaves the machine
- - ~7x slower than FAISS at raw unfiltered search (this is the cost of being a database, not just an index)
- + Same feature tier as zvec (persistence, filtering, database semantics)
- - 10ms+ on filtered queries vs. zvec's 0.5ms
- - Clearly slower at the same feature level
The key insight from this independent benchmark: the comparison that actually matters is zvec vs. ChromaDB — same feature tier. zvec wins clearly, especially on filtered queries (0.5ms vs 10ms+). Comparing zvec to FAISS is apples-to-oranges because FAISS is an index library.
And the NumPy result is a useful calibration: HNSW overhead only pays off at scale. At 10K vectors, brute force wins. At 1M records, the HNSW-based engine is projected to be 38x faster.
All independent benchmark numbers cited above are from a specific 10K vector healthcare use case using fastembed (ONNX) + Polars, run fully offline. Your mileage will vary depending on dimensionality, dataset size, hardware, and query patterns. The official VectorDBBench results on Cohere 10M are more representative of large-scale production workloads.
Architecture: Why In-Process Matters More Than You Think
The architectural shift zvec represents is data locality. When your vector engine runs inside your application process, several things become true simultaneously:
- No RPC layer: Saves you serialization/deserialization overhead.
- No network round-trip: Latency is deterministic and bounded by CPU, not by network jitter.
- Direct memory access: The application reads vectors from the same address space.
- Simpler failure domain: Your application process is the only thing that can fail.
As Maxime Grenu noted on LinkedIn (he is a contributor to the project): "When your GPU pipeline is fast, the CPU-side retrieval path becomes the bottleneck. An embedded vector engine is one of the most effective ways to eliminate that bottleneck."
This is the same insight that made SQLite the most deployed database in the world. Most applications do not need a client-server database. They need a reliable, fast, local data store. The vector world is arriving at the same conclusion.
zvec In-Process Architecture
zvec runs as a library inside your application process, accessing disk-persisted collections directly.
- Application calls zvec SDK in-process
- SDK delegates to Proxima engine via direct function calls
- Proxima reads/writes to disk-persisted storage with crash safety
- Results returned via direct memory
RAG-Ready, Not Just ANN Search
Here is where zvec differentiates from pure index libraries. A production RAG pipeline needs more than "find me the k nearest neighbors." It needs:
Dynamic knowledge management. Your knowledge base is not static. Documents are added, updated, deleted. Meeting notes from today replace yesterday's draft. Full CRUD is the minimum. zvec supports full create, read, update, and delete operations with schema evolution, so you can adjust index strategies as your metadata and query patterns change.
Multi-vector retrieval and fusion. Modern RAG often combines multiple embedding channels — a dense semantic embedding plus a sparse keyword embedding, for example. zvec supports multi-vector joint queries natively. It also ships a built-in reranker that supports both weighted fusion and Reciprocal Rank Fusion (RRF), so you do not have to manually merge and re-score results at the application layer.
Scalar-vector hybrid search. This is where many vector databases fall down in practice. You do not just want "find me similar documents" — you want "find me similar documents written after January 2026 in the engineering department." zvec pushes scalar filters down into the vector index execution layer, avoiding full scans in high-dimensional space. Scalar fields can optionally build inverted indexes to further accelerate equality and range filtering.
- Full CRUD: insert, update, delete documents in real time
- Schema evolution: adjust fields and index strategies over time
- Dense + sparse vectors: native multi-vector queries in a single call
- Built-in reranker: weighted fusion and RRF out of the box
- Hybrid search: scalar filters pushed into the vector index execution path
- Inverted indexes on scalar fields: accelerate equality/range filtering
- Built-in embedding and reranking extensions via the ecosystem
Resource Governance: The Feature Nobody Mentions
This is, to me, the most underappreciated aspect of zvec. And it is the one that matters most for edge and on-device deployments.
HNSW indexes are memory-hungry. During build or query, they can temporarily consume several times the raw data size. On a cloud VM with 64 GB of RAM, who cares. On a mobile device, a desktop app, or a CLI tool — your application gets killed by the OOM Killer or triggers an Android ANR (Application Not Responding) dialog.
zvec provides three layers of memory management:
1. Streaming, chunked writes. Writes are processed in 64 MB chunks by default. You never hold the entire dataset in memory during ingestion. This is the difference between "it works on my laptop" and "it works on a phone."
2. On-demand loading via mmap. Enable enable_mmap=true and vector/index data is paged into physical memory on demand by the OS. Your collection can be larger than available RAM. This is critical for edge devices where you might have a 2 GB vector collection but only 4 GB of total RAM.
3. Hard memory limiting (experimental). When mmap is not enabled, zvec maintains an isolated, process-level memory pool. You can explicitly cap its budget via memory_limit_mb. This is the "I absolutely cannot use more than X MB" guarantee that platform teams need.
On the concurrency side:
- Index build threads are configurable per-operation via a
concurrencyparameter, plus a globaloptimize_threadscap. - Query threads are capped via a global
query_threadssetting.
This prevents the classic problem in GUI applications where background vector computation spawns too many threads, saturates the CPU, and causes UI stutter.
Edge Deployment Failure Modes zvec Addresses
OOM kill on mobile/embedded device
highTrigger: HNSW index build consuming multiple times raw data size in memory
Detection: Process killed by OS OOM Killer or Android ANR
Mitigation: 64 MB streaming writes, mmap mode, hard memory_limit_mb cap
UI stutter in desktop/mobile apps
mediumTrigger: Unconstrained thread spawning during vector index build or query
Detection: Main thread starvation, frame drops, ANR dialogs
Mitigation: Configurable optimize_threads and query_threads caps
Data loss after crash or forced exit
highTrigger: Application killed mid-write (phone locked, CLI interrupted, power loss)
Detection: Corrupted or missing index on restart
Mitigation: Persistent storage with automatic crash recovery, thread-safe access
Real-World Patterns Emerging in the Wild
zvec is still early (v0.2.0 as of February 2026), but interesting usage patterns are already emerging from the developer community.
Pattern 1: Agent memory and audit trail
zacharyr0th on X described a setup where zvec serves as the "shared execution fabric and audit trail across agents." Every message and tool call is traced, stored locally in zvec, and then recursively reviewed to improve future agent capabilities. The architecture pairs QMD for per-agent knowledge retrieval with zvec for tracking what actually works. Combined with Qwen 3.5, the whole stack runs locally on approximately 32 GB of RAM.
This is a pattern worth paying attention to: using an embedded vector database not just for retrieval but as an execution log that agents can search semantically. "What tool calls worked well in similar situations?" is a vector query, not a SQL query.
Pattern 2: Privacy-preserving healthcare search
The healthcare benchmark from ABC is a deployment pattern. Semantic patient search where patient data never leaves the machine. Describe a clinical presentation in natural language, find the most similar cases from 10,000 patient records. The stack: zvec + fastembed (ONNX) + Polars, fully offline, uv run.
For regulated industries (healthcare, finance, legal), the "data never leaves the machine" property is a compliance requirement. An in-process vector database that persists locally is architecturally incapable of leaking data over the network, because there is no network.
Pattern 3: The "zero-infrastructure RAG" for developer tools
The original positioning from Alibaba's blog post describes the target scenario: a local RAG assistant on PC or mobile where users query local codebases, technical documents, or meeting notes via natural language — even without a network connection. This is the IDE plugin use case, the local documentation search use case, the "I have 50 PDF papers and I want semantic search over them" use case.
The Tradeoffs You Need to Understand
I would not be doing my job if I only talked about what zvec does well. Here are the constraints and limitations you should factor into your decision:
Single-node only. zvec is an embedded library. It runs on one machine. If you need distributed vector search across a cluster, this is not your tool. Milvus, Qdrant, or Weaviate are designed for that. zvec is for the (very large) class of applications where single-node is sufficient.
No GPU acceleration. Unlike FAISS, which has GPU implementations for certain index types, zvec is CPU-only. Its performance comes from SIMD, cache-friendly layouts, and multi-threading — but if you have spare GPU cycles and need to burn them on vector search, FAISS still owns that niche.
Platform support is still limited. Linux x86_64, Linux ARM64, and macOS ARM64 only.
Python-only SDK. The core is C++ (81.3% of the codebase), but the only user-facing SDK today is Python. Rust and other language bindings are on the roadmap but not shipped. If you are building a mobile app in Swift or Kotlin, you cannot use zvec directly yet — though the C++ core theoretically supports it.
Young project. v0.2.0, 15 contributors, 3 releases. The roadmap mentions LangChain/LlamaIndex integrations, DuckDB/PostgreSQL extensions, and real device deployments — but these are plans, not shipped features. Evaluate accordingly.
HNSW overhead at small scale. As the independent benchmark showed, at 10K vectors NumPy brute-force is faster. HNSW's graph-based approach has overhead that only pays off at larger scales. If your dataset is under 50K vectors and you do not need persistence or filtering, a simpler approach may suffice.
Key Assumptions to Validate for Your Use Case
| Assumption | Confidence | Validation | Owner | Status |
|---|---|---|---|---|
| Your workload fits on a single machine | /5 | - | open | |
| You need persistence, CRUD, and crash recovery (not just raw ANN) | /5 | - | open | |
| Your dataset is large enough for HNSW to pay off (50K+ vectors) | /5 | - | open | |
| Your deployment target is Linux or macOS ARM64 | /5 | - | open | |
| Python SDK is acceptable (Rust/Go/JS bindings not available yet) | /5 | - | open | |
| CPU-only performance is sufficient | /5 | - | open |
Getting Started in 60 Seconds
The quickstart path is genuinely minimal. Here is the full flow from install to semantic search:
Installation
pip install zvec- - Requires Python 3.10–3.12
- - Linux x86_64
- - Linux ARM64
- - macOS ARM64.
import zvec
# Define schema with a vector field and an optional scalar field
schema = zvec.CollectionSchema(
name="my_docs",
fields=[
zvec.FieldSchema(
name="publish_year",
data_type=zvec.DataType.INT32,
index_param=zvec.InvertIndexParam(
enable_range_optimization=True
),
),
],
vectors=[
zvec.VectorSchema(
name="embedding",
data_type=zvec.DataType.VECTOR_FP32,
dimension=768,
index_param=zvec.HnswIndexParam(
metric_type=zvec.MetricType.COSINE
),
),
],
)
# Create and open the collection (persists to disk)
collection = zvec.create_and_open(
path="./my_collection",
schema=schema,
)
# Insert a document
collection.insert(
zvec.Doc(
id="doc_1",
vectors={"embedding": [0.1] * 768},
fields={"publish_year": 2026},
)
)
# Build the index
collection.optimize()
# Search by vector similarity
results = collection.query(
zvec.VectorQuery(
field_name="embedding",
vector=[0.3] * 768
),
topk=10,
)
print(results)Three API calls: create_and_open, insert, query. That is the entire critical path. The data persists to disk. Crash recovery is automatic. If you have used SQLite, this model is immediately familiar.
Closing Thoughts
The vector database landscape has been dominated by two poles: lightweight index libraries that are fast but incomplete (FAISS), and full-featured server-based systems that are complete but operationally heavy (Milvus, Pinecone, Weaviate). zvec occupies the middle ground that a huge number of real applications actually need: database semantics, production-grade performance, and zero operational overhead.
The "SQLite of vector databases" framing is earned, not aspirational. SQLite succeeded because it recognized that most applications need a reliable embedded one. The same is true for vector search. Most RAG pipelines, most agent memory systems, most semantic search features in desktop and mobile apps do not need a distributed vector cluster. They need a fast, persistent, filterable vector store that runs wherever the code runs.
Whether zvec specifically becomes the standard here depends on execution: shipping more language bindings, landing the LangChain/LlamaIndex integrations, proving stability across more platforms and use cases. The project is young. But the architectural thesis — that in-process vector search is the right default for most AI applications — feels correct. And the Proxima engine underneath is not a research prototype; it has been running Alibaba's production systems for years.
If you are building RAG, agent memory, semantic search, or recommendation features and your deployment target is anything other than "managed cloud cluster with unlimited budget," zvec deserves a spot on your evaluation shortlist.
What patterns are you seeing with embedded vector databases? Have you hit the retrieval-latency bottleneck in your own RAG pipelines? I am curious whether others are using in-process vector stores for agent audit trails like the pattern described above.