The most useful mental model for agentic system is the event-driven microservice architecture.
If you are building a single deep agent or a spoke-to-spoke multi-agent application, the winning architecture is usually an async one.
The hard part is controlling retries, state, handoffs, isolation, observability, and failure recovery well enough that the system still behaves when traffic spikes, a tool lies, a worker slows down, or an agent gets stuck in a loop.
I will walk you through the patterns behind the most innovative start-ups in this article:
- The real architecture problem
- Async patterns for agents
- Queue: the right default for expensive or risky actions
- Topic: the right pattern for fan-out reactions
- Event bus: the right pattern for cross-domain routing
- A reference platform for agentic applications
- A concrete example: product research to implementation
- Hub-and-spoke or spoke-to-spoke?
Let’s dive in.
High-level view of what we will cover in this article
The real architecture problem
Workflows are systems where LLMs and tools are orchestrated through predefined code paths, while agents are systems where the model dynamically decides how to use tools and proceed.
That sounds academic until you build both, ship both, and realize they fail in different ways.
- A workflow usually fails like traditional software: a branch was missing, a parser broke, a timeout hit, or a dependency drifted.
- An agent fails more like a distributed adaptive process: it over-explores, chooses the wrong tool, compounds small mistakes, or drifts because the environment keeps changing while it is still reasoning.
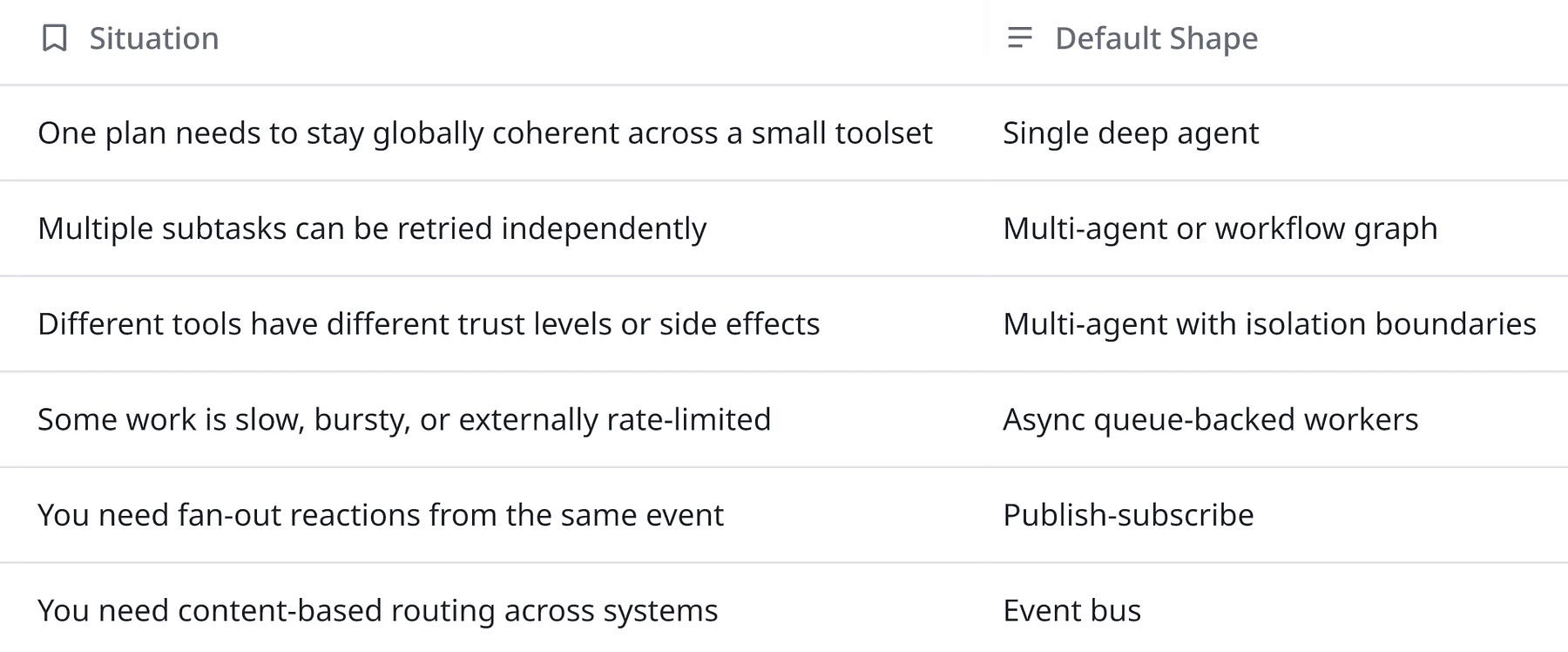
The question is “Where does uncertainty belong in this system?”
If the uncertainty belongs inside a bounded decision loop, a single deep agent can be the right answer but when the uncertainty belongs in routing, specialization, or independently retryable units of work, you are usually better off with a set of smaller components connected by async boundaries.
Here is the decision rule I use:
What goes wrong in practice is that teams often jump from **one prompt** straight to **many agents**, without designing the message topology between them.
That is the same mistake people made when they split a monolith into microservices before deciding how requests, events, retries, schemas, tracing, and compensations would work.
In agent systems, I now look at four axes before choosing the shape:
- Uncertainty: Does the model need freedom to decide the next step, or do I already know the path?
- Reversibility: If the agent is wrong, can I safely retry or compensate?
- Coordination scope: Does one component need the whole picture, or can subtasks run in isolation?
- Latency tolerance: Is this interactive, near-real-time, or eventually consistent?
That framing often kills the false binary of “single agent versus multi-agent.”
Many good systems are actually mixed systems: one strong planner in front, a handful of specialized workers behind it, and an async event spine connecting everything.
Async patterns for agents
When I repurpose distributed systems ideas for agentic applications, I map three familiar async patterns almost directly:

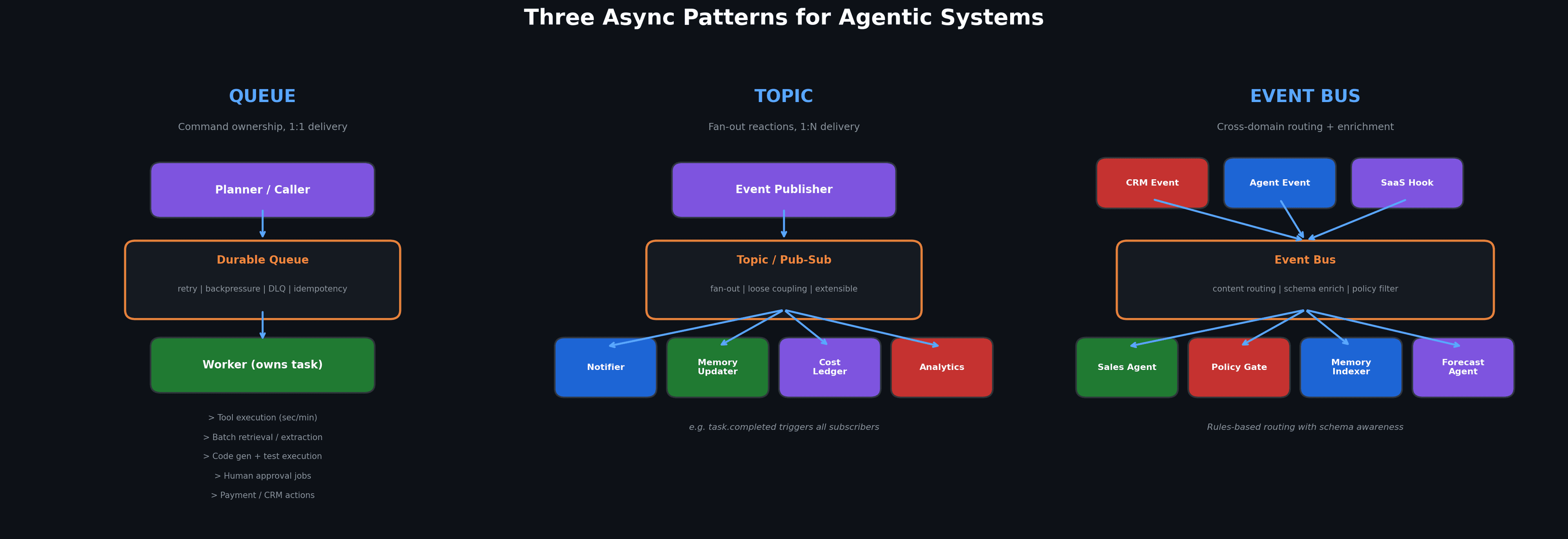
Because once the work exists, you need semantics.
Queue: the right default for expensive or risky actions
A queue is my default boundary when one downstream capability should own a task, process it at its own pace, retry safely, and not block the caller. In agentic systems, that usually means:
- Tool executions that can take seconds or minutes.
- Batch retrieval or document extraction.
- Code generation plus test execution.
- Long-running browser or computer-use tasks.
- Human approval jobs.
- External actions against payment, CRM, ticketing, or deployment systems.
The benefit is also psychological clarity.
A queue forces me to say: this is not “reasoning” anymore; this is a command with delivery, retry, timeout, and ownership semantics.
That separation keeps the planner from being overloaded with operational concerns, and it gives workers freedom to scale horizontally or degrade independently.
It also gives me the engineering tools I actually need: backpressure, dead-letter queues, retry budgets, per-capability concurrency limits, and idempotency keys.
The biggest mistake I see is people sending natural-language requests across agent boundaries with no contract.
That is the equivalent of replacing a typed interface with **hope**.
A queue payload for agent work should be closer to a command envelope than a chat message:
{
"task_id": "tsk_01JX...",
"correlation_id": "corr_8f0c...",
"causal_parent_id": "step_42",
"intent": "run_code_fix",
"capability": "python_codegen",
"input_ref": "artifact://problem-statement/9831",
"constraints": {
"deadline_ms": 120000,
"max_cost_usd": 0.75,
"side_effects_allowed": false
},
"idempotency_key": "repoA-issue143-try2",
"policy_tags": ["sandbox_only", "customer_data_restricted"],
"reply_to": "topic://task-status"
}A well-structured envelope turns agent orchestration into something you can debug, and it also makes replay possible.
Topic: the right pattern for fan-out reactions
A topic is different.
I use it when one event should trigger multiple subscribers that do different things with the same fact.
Typical examples:
task.completedtriggers a notifier, a memory updater, a cost ledger, and an analytics sink.artifact.createdtriggers indexing, evaluation, and downstream routing.safety.escalatedtriggers a reviewer queue, an audit trail, and a product alert.customer_intent.detectedtriggers recommendation logic, personalization, and A/B instrumentation.
In other words, topics are for system reaction, not command ownership.
And multi-agent systems often fail by overusing direct calls, if every agent explicitly invokes every other agent, the topology becomes fragile and tightly coupled.
A publish-subscribe layer restores looseness and it lets me add a new reviewer, a new evaluator, or a new analytics consumer without changing the core planner.
That is especially important in product teams, where platform needs change faster than application flows.
The first version may only need research then answer but the second version suddenly needs memory indexing, red-team evaluation, billing attribution, cost anomaly detection, and audit logging.
A topic-based state stream makes those additions possible without rewriting the original orchestration path.
Event bus: the right pattern for cross-domain routing
The event bus pattern is where things get interesting for agentic platforms.
I use an event bus when I need content-based routing, schema-aware enrichment, external integration, or organization-wide extensibility.
In classic cloud systems, this is where people think about buses, rules, and transformations.
In agentic systems, it is where I decide how internal agents, external SaaS events, governance policies, and product workflows meet.
For example:
- A CRM update can emit
account.changed. - That event can route to a sales-research agent, but only for enterprise accounts above a threshold.
- A policy transformer can strip fields before the event reaches lower-trust consumers.
- A memory indexer can persist a normalized artifact.
- A forecasting agent can subscribe only to specific product lines.
- A human-review workflow can be triggered if the event crosses a risk threshold.
That is routing discipline.
A reference platform for agentic applications
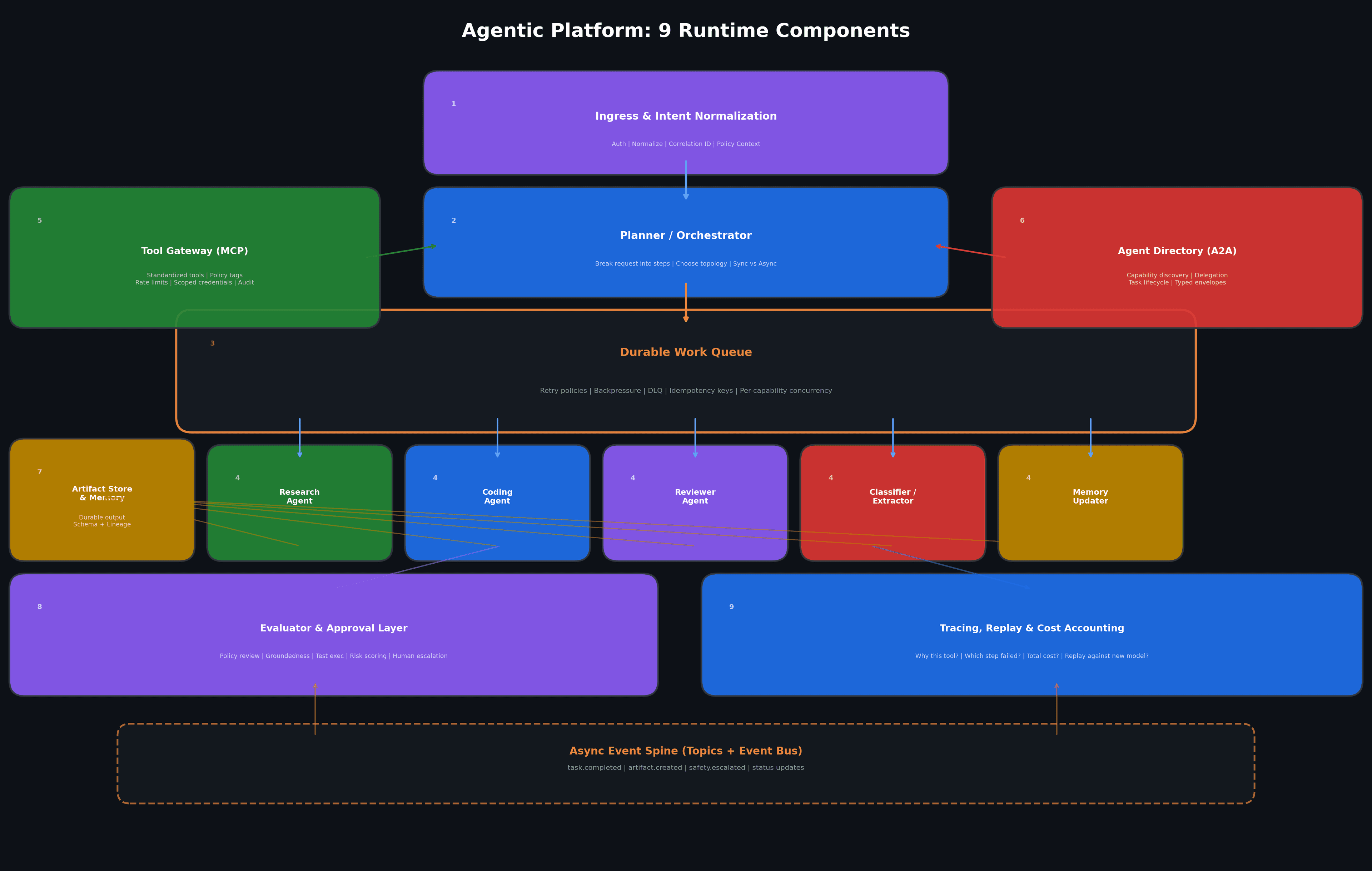
When I design an agentic platform today, I usually start with nine runtime components.
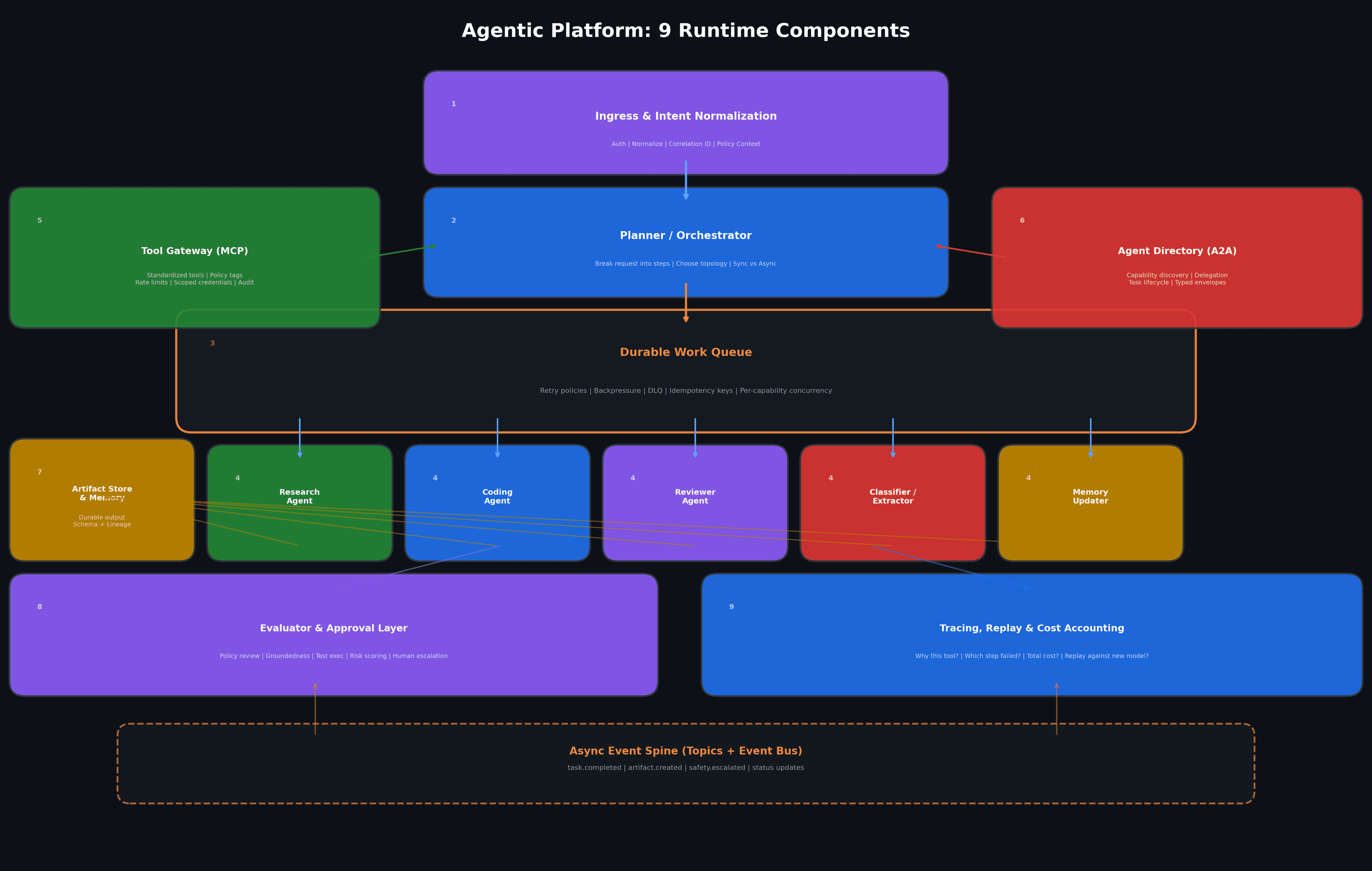
Not every product needs all nine on day one, but if I cannot point to where each concern will live, I know the system will get messy fast.
1. Ingress and intent normalization
This is the API or app boundary: chat UI, workflow trigger, webhook, IDE command, or product action.
Its job is not to do heavy reasoning but to authenticate, normalize input, attach policy context, and emit a first-class request envelope.
I want this layer to assign a correlation ID before the first LLM call.
That single decision saves days of debugging later.
2. Planner or orchestrator
This can be a single strong model or a deterministic workflow engine plus model calls.
Its job is to break the request into steps, choose a topology, and decide which work is synchronous versus async.
This is where many teams overfit.
They put every capability into the planner and then wonder why it becomes brittle.
I prefer a planner that produces intent, priorities, and task boundaries, not one that tries to directly do all the work.
3. Durable work queue
Any step that is slow, costly, bursty, or externally rate-limited goes here.
This includes retrieval pipelines, code execution, browser automation, batch transformation, or human approval.
The queue is also where I attach retry semantics.
Not all tasks deserve the same retry policy where aread-only search job can retry aggressively and payment or email action should retry conservatively and with stronger idempotency guarantees.
4. Specialist workers
These are the actual execution units: research agent, coding agent, reviewer agent, classifier, extractor, planner assistant, memory updater, evaluation worker, or integration worker.
I do not care whether these are all “agents” in the marketing sense. I only care that each one has a narrow responsibility, a clear side-effect profile, and a measurable contract.
5. Tool gateway
This is where MCP fits naturally.
Instead of every agent carrying its own spaghetti integration layer, I want tools exposed in a standardized way so capabilities are reusable, documented, and governable.
MCP’s core value is exactly that standardization of connections to tools, data sources, and workflows.
This is also where I enforce policy tags, rate limits, scoped credentials, and audit logging.
A tool call is a security and reliability event.
6. Agent directory and delegation layer
This is where A2A becomes useful.
If agents need to discover each other’s capabilities, negotiate work, and exchange artifacts or progress updates, A2A gives a common protocol shape for that collaboration.
I think of this as the service registry plus delegation mesh for the agent era.
The important design choice is that direct agent-to-agent collaboration should still ride over explicit contracts instead of informal shared context blobs.
7. Artifact store and memory system
One subtle but critical shift in agent architecture is separating messages from artifacts.
A message is transient coordination and an artifact is durable output: a plan, summary, patch, retrieval bundle, evaluation score, or customer-facing answer draft.
Google’s A2A model explicitly frames task completion around artifacts, which I think is the right abstraction for multi-agent systems.
When outputs are turned into addressable artifacts with schemas and lineage, replay and review become much easier.
8. Evaluator and approval layer
Evaluator-optimizer loops are practical workflow patterns, where one model generates and another critiques and iteratively improves.
I treat that as a reusable platform primitive.
This layer can do:
- Policy review
- Groundedness checks
- Test execution
- Risk scoring
- Style or brand review
- Schema validation
- Human escalation
Do not use the same exact perspective for generation and approval if the cost of error matters.
9. Tracing, replay, and cost accounting
No agent platform is production-ready until you can answer these questions quickly:
- Why did the system choose this tool?
- What artifacts did it read before acting?
- Which step introduced the bad assumption?
- Was the failure caused by the model, the tool, the queue, or the policy layer?
- How much did this request cost?
- Can I replay it against a new prompt, model, or tool version?
If you cannot answer those questions, you are still in prototype land.
A concrete example: product research to implementation
To make this less abstract, imagine I am building an internal agentic product assistant for a software team.
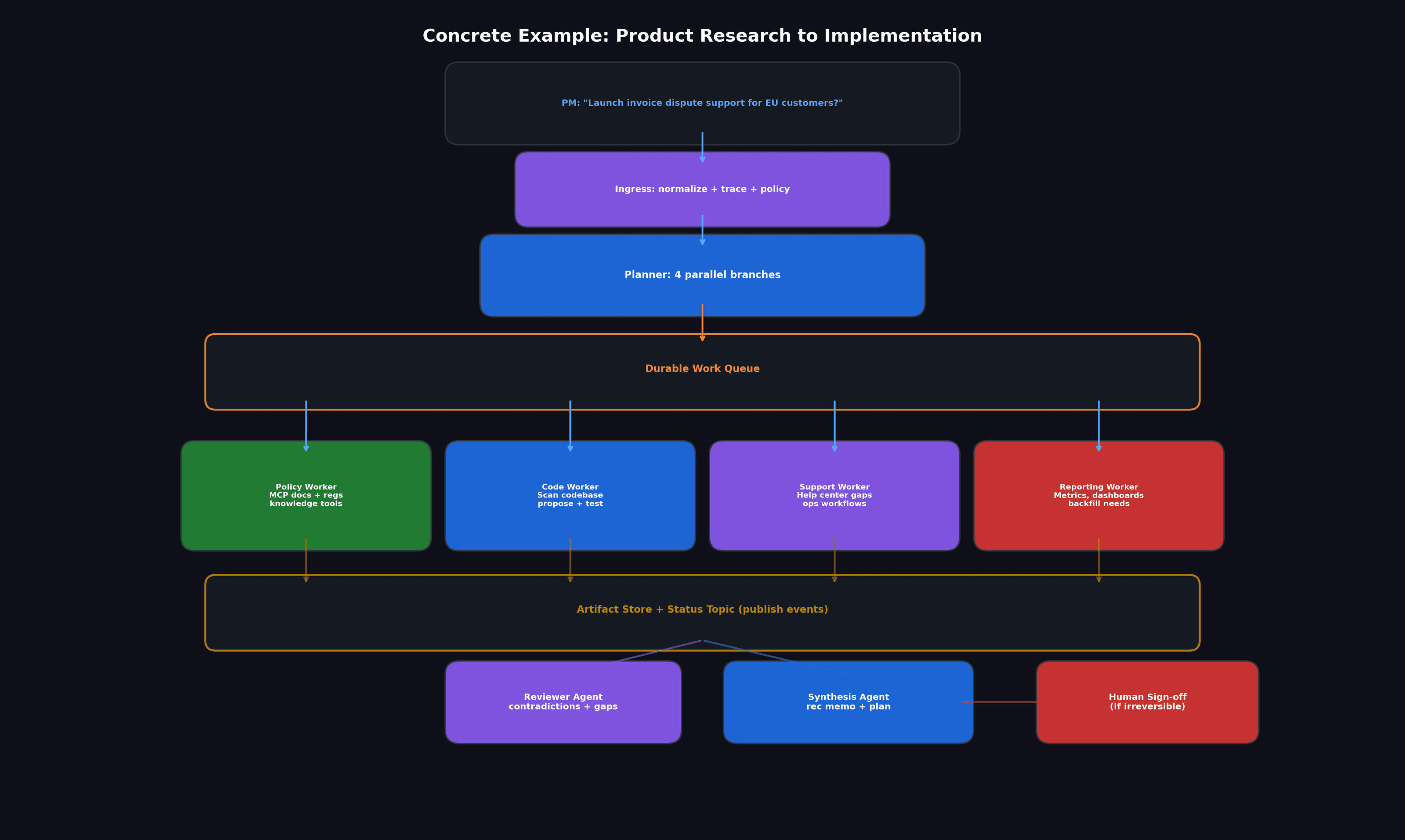
Product research pipeline
A product manager asks:
“What would it take to launch invoice dispute support for EU customers next quarter?”
A good architecture does this:
- The ingress layer normalizes the request, attaches tenant and compliance context, and starts a trace.
- The planner decides the job has four branches: policy analysis, codebase impact, support-ops impact, and data/reporting impact.
- Each branch becomes a task on a queue.
- A policy worker uses MCP-connected document and knowledge tools to retrieve relevant internal policies and regulatory references.
- A code worker scans the codebase, proposes touched services, and runs tests in a sandbox.
- A support worker inspects help center gaps and operational workflows.
- A reporting worker identifies metrics, dashboards, and backfill needs.
- All four workers emit artifacts to a store and publish status events to a topic.
- A reviewer agent checks for contradictions and missing assumptions.
- A final synthesis agent produces a recommendation memo and an implementation plan.
- If the plan suggests irreversible changes, a human sign-off gate blocks execution.
That distinction is what preserves sanity at scale.
Hub-and-spoke or spoke-to-spoke?
I generally prefer hub-and-spoke until the product proves it needs more autonomy.
In hub-and-spoke, a central orchestrator owns global policy, budget, and final synthesis and specialists do narrow work and report back.
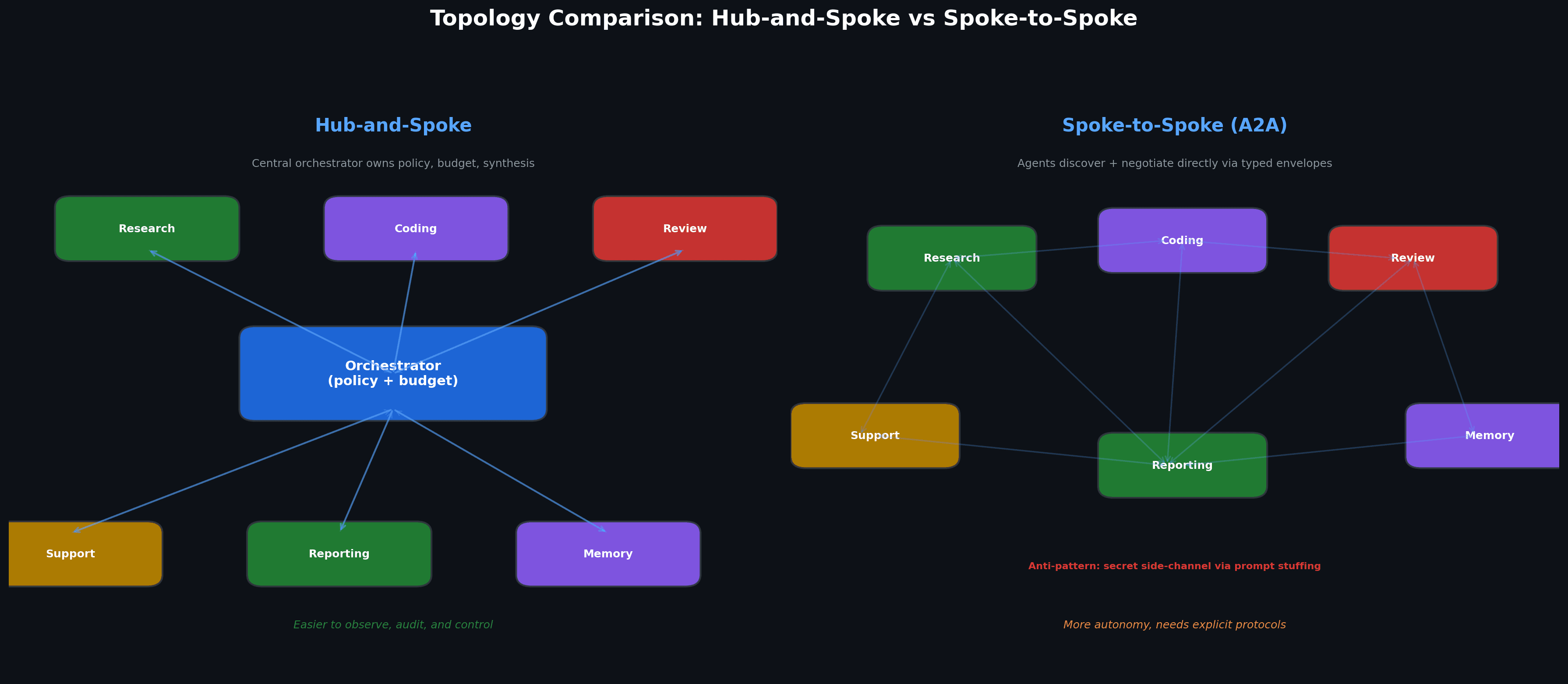
This is easier to observe, cheaper to audit, and much harder to let spiral.
Spoke-to-spoke collaboration becomes attractive when specialists need to negotiate directly or exchange intermediate artifacts without routing every detail through the center.
A2A’s concepts of capability discovery, task lifecycle, and artifact exchange are a good fit for that model but I still only allow spoke-to-spoke communication through explicit protocols and typed envelopes.
The anti-pattern is secret side-channel coordination through prompt stuffing and it feels fast at first but becomes unmaintainable almost immediately.
Concluding Thoughts
The long-term debate is the evolution is toward layered systems where different forms of intelligence operate under explicit contracts.
One product may still look like a single assistant on the surface, while internally it uses queues, topics, evaluators, artifacts, policy gates, MCP tool servers, and A2A-based delegation.
It is just what good platform or product engineering looks like when the workload includes reasoning.
Once you design the system that way, the topology starts doing a lot of the heavy lifting.