In short, a multi-agent system that previously required three separate API subscriptions running at $200/month each can now run on a single workstation with a couple of RTX 4090s, entirely offline, with no per-token costs.

Let me unpack that a little.
At 32-bit precision, the KV cache for a 70B-parameter model processing 100k tokens can eat 40+ GB of memory.
On a cloud GPU, that’s fine because you’re renting the hardware but on your local machine, that’s your entire system memory, on an edge device, it’s a fantasy.
Google’s TurboQuant is a quantization algorithm that compresses the KV cache down to 3 bits per value, from an industry standard of 32 bits.
That’s a 6x reduction in memory and up to 8x faster attention computation, with zero accuracy loss across five standard long-context benchmarks.
For example, it can run in llama.cpp on M5 Max with Metal kernels, and hit the compression benchmarks (4.9x at 3-bit), or HP ZGX now can fit 4,083,072 KV-cache tokens on GB10.
Note: Four million tokens of persistent context…
That’s an entire codebase or weeks of conversation history.
That’s a multi-agent system where every agent can see everything, all the time, without summarization, without eviction, without the lossy heuristics we’ve been writing to manage context windows.
Previous compression methods always made a trade like you could shrink the cache, but you’d lose quality.
Engineers accepted this Faustian bargain because there was no alternative but TurboQuant eliminates the trade entirely.
How TurboQuant Works
TurboQuant is elegant in its construction. It’s a two-stage pipeline built on two sub-algorithms:
Stage 1: PolarQuant
Instead of compressing vectors in standard Cartesian coordinates, PolarQuant converts them to a polar coordinate system.
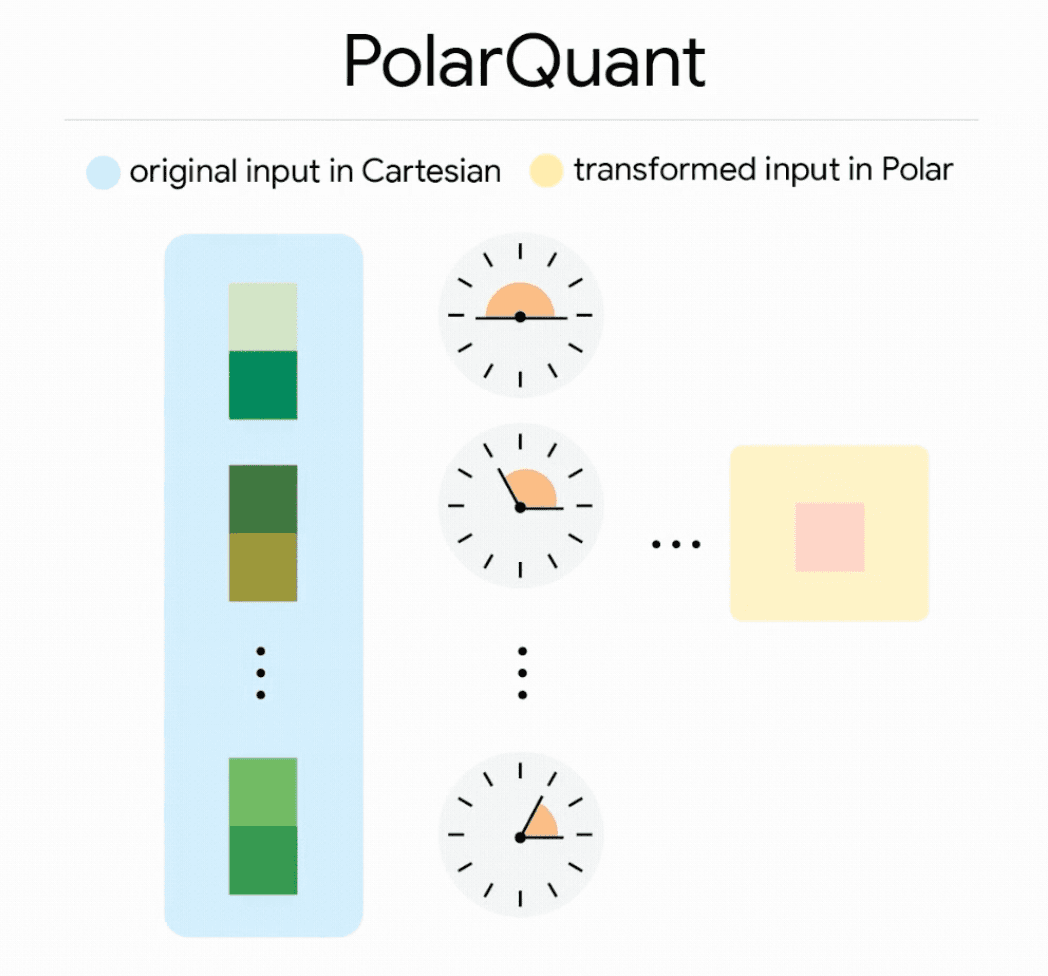
Think of it as replacing “go 3 blocks east, 4 blocks north” with “go 5 blocks at 37 degrees.”
This eliminates the expensive normalization step that traditional quantizers require but because the angular distribution in polar space is highly concentrated and predictable, PolarQuant can map values onto a fixed grid without the per-block calibration constants that add overhead to every other method.
Stage 2: QJL (Quantized Johnson-Lindenstrauss)
The residual error left over from PolarQuant gets caught by a 1-bit error-correction layer based on the Johnson-Lindenstrauss transform.
This is a dimensionality-reduction technique that preserves pairwise distances.
QJL uses a single sign bit per value and requires zero memory overhead. It acts as a bias-eliminating error-checker that cleans up the approximation from Stage 1.
Google tested it across Gemma and Mistral models on LongBench, Needle-in-a-Haystack, ZeroSCROLLS, RULER, and L-Eval.
TurboQuant achieved perfect downstream results on needle-in-a-haystack tasks while reducing KV memory by 6x.
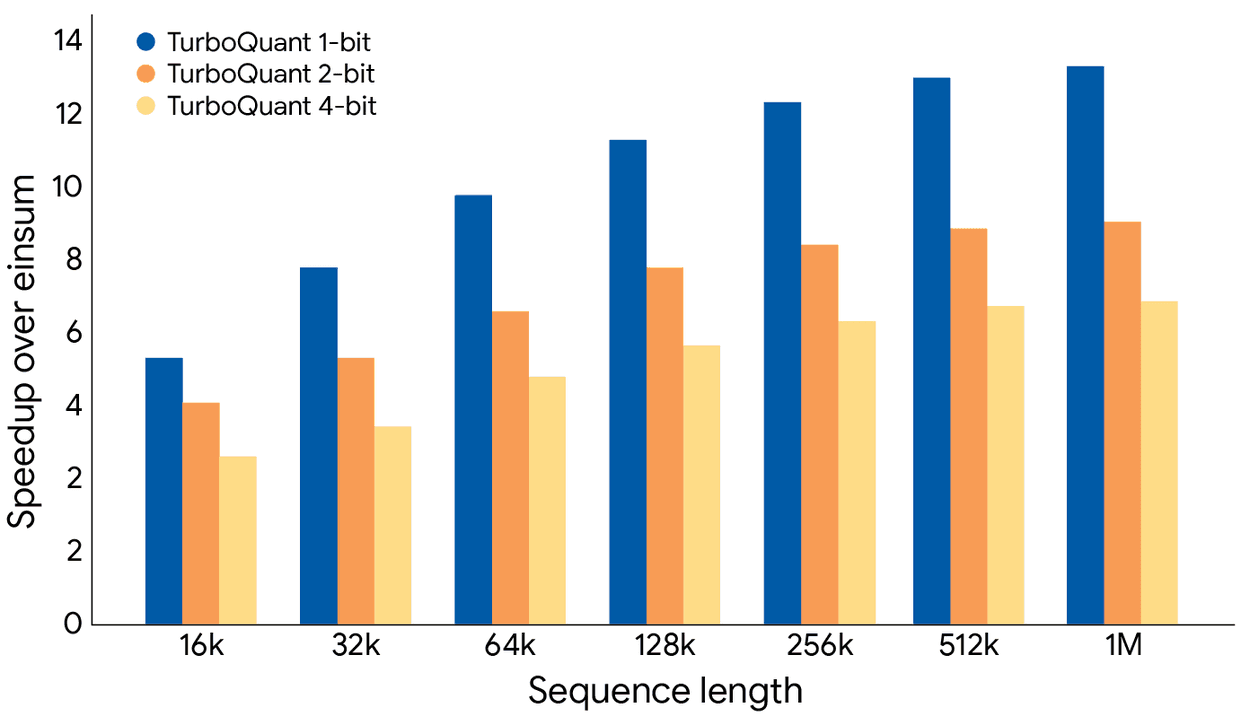
On H100 GPUs, 4-bit TurboQuant delivered up to 8x speedup over the unquantized baseline for computing attention logits.
And crucially: it requires no training or fine-tuning, you apply it at inference time. Your existing models just got dramatically more memory-efficient.
What This Means for Agents
With TurboQuant-level compression, a 128GB unified memory system (like the NVIDIA DGX Spark with the GB10 superchip) can hold over 4 million KV cache tokens.
Again, that’s a multi-agent system where every agent can see everything, all the time, without summarization, without eviction, without the lossy heuristics we’ve been writing to manage context windows.
It unlocks entirely a new level of developer experience.
A $1,600 graphics card running a quantized 32B model can now produce frontier class code completions.
A 14B model on a laptop can outperform o1-mini on math benchmarks.
Two consumer GPUs can match a $25,000 datacenter card at a quarter of the cost.
Open-source models like Qwen3–235B-A22B already outperform DeepSeek-R1 on 17 out of 23 benchmarks, and Llama 3.3 70B matches GPT-4-level performance across numerous tasks.
Now combine these capable open models with TurboQuant’s compression.
A multi-agent system that previously required three separate API subscriptions running at $200/month each can now run on a single workstation with a couple of RTX 4090s, entirely offline, with no per-token costs.
The economics of this are staggering.
Moreover, Apple’s MLX framework is now integrated with the M5’s Neural Accelerators, enables fast quantized inference natively on Apple Silicon.
vLLM-MLX achieves 464 tokens per second on M4 Max.
Hugging Face is shipping MLX-optimized versions of 120B-parameter models in 6-bit quantization for direct local inference on M-series Macs.
The community consensus is that MLX will likely ship TurboQuant support first, before llama.cpp, SGLang, or vLLM because Metal’s architecture is the most natively analogous to TurboQuant’s algorithms and requires the least adaptation work.
When that happens, a MacBook Pro becomes a platform for running a genuinely capable agent, a system that can maintain 100k+ tokens of context, call local tools via MCP, and execute multi-step reasoning workflows, all without an internet connection.
For developers building coding assistants, local CI/CD agents, or privacy-sensitive automation, this is the unlock.
Hardware Is Meeting Software Halfway
NVIDIA’s GB10 Grace Blackwell superchip puts a Blackwell GPU with 5th-generation Tensor Cores and 128GB of unified coherent memory on your desk, powered by a standard electrical outlet.
It supports FP4 and FP8 precision workloads natively.
Two units linked with ConnectX networking can run 405B-parameter models.
ARM’s Cortex-X925 cores in the Grace CPU provide the single-threaded performance needed for the CPU-bound parts of agent orchestration with task routing, tool dispatch, message parsing while the GPU handles inference.
Meanwhile, consumer hardware continues to improve.
DDR6 memory with 1600 GB/s bandwidth is expected with AMD’s Epyc Venice platform. PCIe Gen6 doubles the interconnect bandwidth. The hardware floor keeps rising.
These are all mind bending developments.
Open-Source Models Are Closing the Gap
A Nature publication from February 2026 made a remarkable argument:
Compressing a giant is more effective than training a dwarf.
The researchers demonstrated that large language models exhibit phase transitions under compression and that structural, numerical, and algebraic redundancy sources are orthogonal.
By combining pruning, quantization, and low-rank decomposition in a criticality-aware framework, they achieved near-lossless compression to 10% of original model size.
This aligns perfectly with what we’re seeing in practice.
Open-source models now represent 62.8% of the market by model count, and the expected date for open-closed performance parity is Q2 2026 at current improvement rates.
The Qwen ecosystem has seen explosive adoption, becoming the most downloaded model family as measured by cumulative downloads.
The gap between what you can run locally and what you’d get from a $200/month API subscription is narrowing every month.
TurboQuant compresses that gap further by making the models you can run locally dramatically more capable.
Quantization Itself Is Evolving Rapidly
TurboQuant is the headline, but it’s part of a broader quantization renaissance:
- GGUF i-quants (importance-matrix quantizations) use non-linear codebooks to allocate more bits to sensitive layers like attention mechanisms, enabling IQ4_XS to outperform standard Q4_K_M at smaller footprints.
- AWQ (Activation-Aware Weight Quantization) protects important weights by observing activation distributions, achieving 95% quality retention — the highest of any standard method. The Marlin-AWQ kernel combines AWQ quality with maximum throughput and is the current sweet spot for GPU inference.
- Red Hat’s LLM Compressor added attention and KV cache quantization, AutoRound (which optimizes rounding decisions and clipping ranges with trainable parameters), and experimental MXFP4 support for 4-bit floating-point quantization.
- GPTQ remains GPU-optimized with 5x faster inference than GGUF on pure CUDA with Marlin kernels.
Each of these advances chips away at the overhead of running capable models locally.
TurboQuant addresses the KV cache; weight quantization addresses the model itself.
Together, they’re making it possible to run models that were datacenter-exclusive six months ago on hardware you can buy at Best Buy.
Building for Local-First: A Practical Architecture
If you’re building agentic AI systems today, here’s the architecture I’d recommend thinking about:

Not every agent in your system needs the same model and you can route by capability requirements:
- Planning and complex reasoning: Use your largest local model (32B–70B quantized) or fall back to cloud for genuinely hard tasks.
- Execution and tool use: 8B-14B models handle code generation, API calls, and structured output extraction with high reliability.
- Verification and critique: A smaller model can check outputs against schemas, run assertions, or flag obvious errors.
- Embedding and retrieval: Local embedding models (BGE-M3, Nomic Embed) plus a TurboQuant-compressed vector index.
This Planner-Executor-Verifier pattern maps naturally to a tiered local inference setup.
Concluding Thoughts
Google just proved that the most expensive bottleneck in AI inference can be dissolved with software, no new hardware required.
Just better algorithms, applied at inference time, making the hardware you already own dramatically more capable.
The companies building for local-first AI right now are going to look very smart very soon.