Qwen 3.5 35B-A3B made its 235B predecessor look old overnight by using just 3 billion active parameters per token, about 8.6% of the model at any given moment.
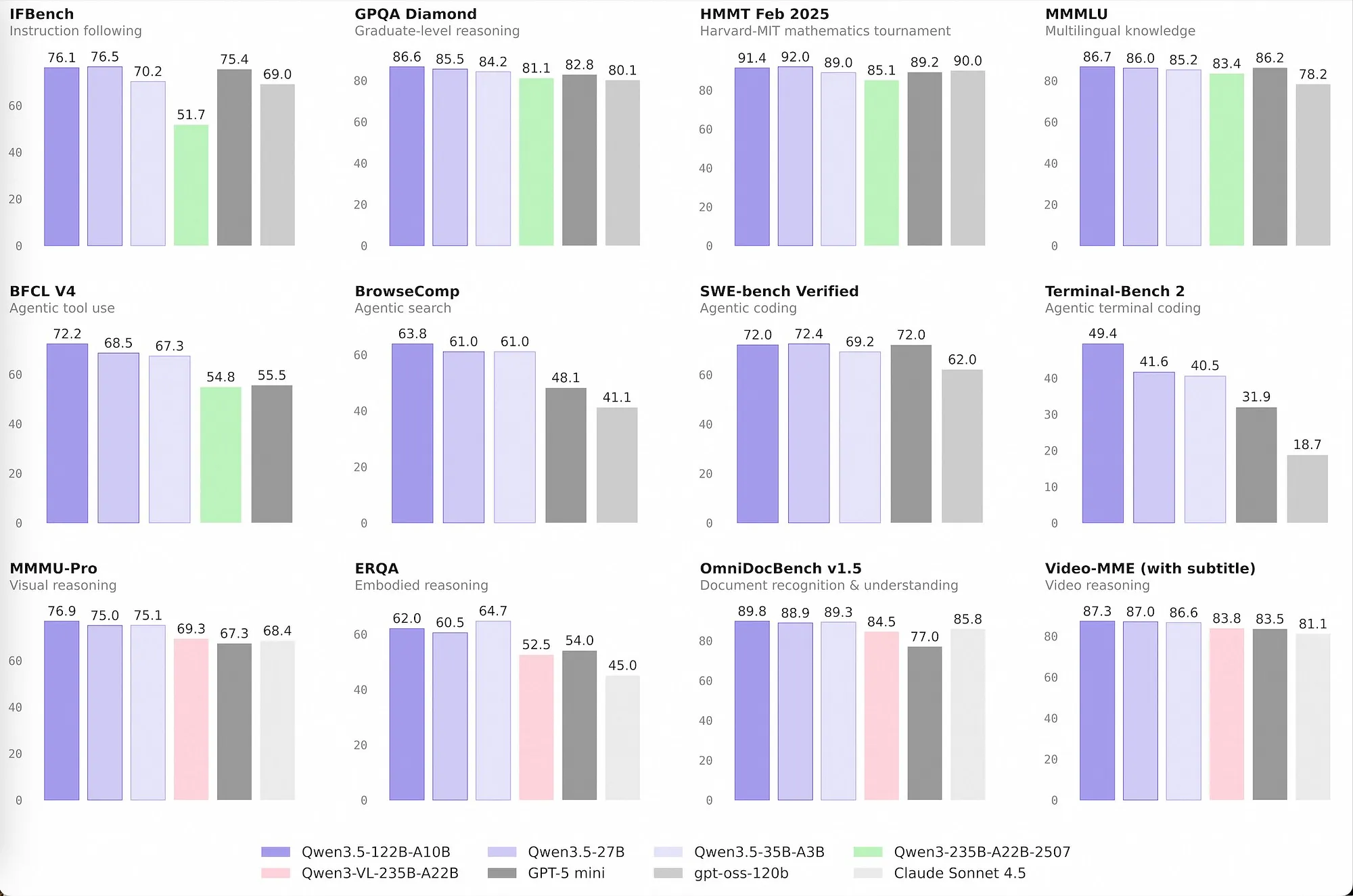
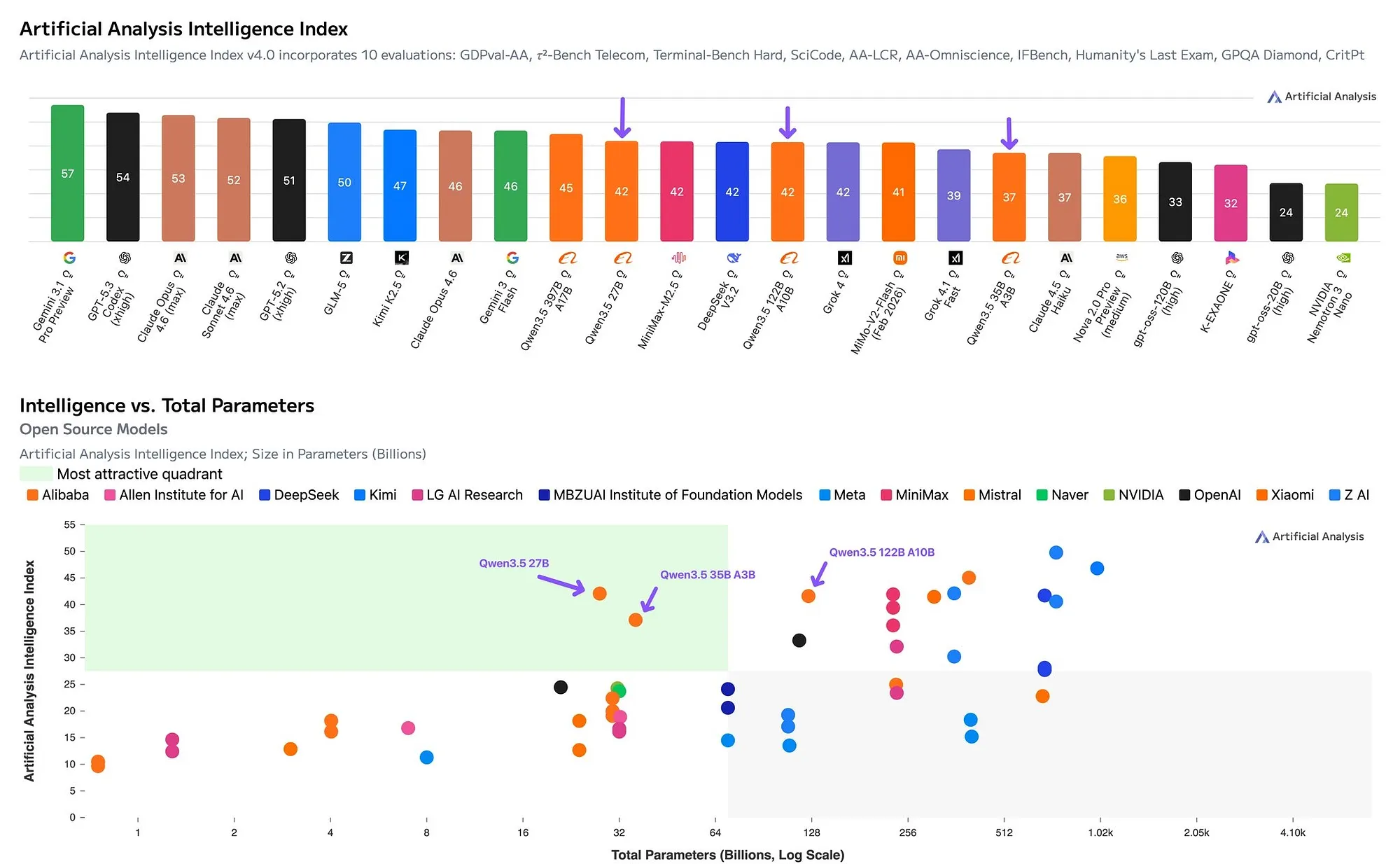
Benchmarks alone are enough to make you stop scrolling.
On a secondhand RTX 3090, the kind of card you can still find for roughly $800, people are reporting 112 tokens per second while keeping the full 262K context window alive.
One person wired it into Claude Code, handed it a single architecture brief for a complete game, and watched it produce 10 files, 3,483 lines of code, fix its own collision logic, and boot a playable build on the first try.
On paper, Qwen 3.5 35B-A3B reads like a practical, efficient MoE: cheaper to run, easier to fit, broadly accessible. People are turning it into a local coding agent, an uncensored automation engine, and a long-context reasoning machine that still feels responsive.
The other thing worth saying out loud: a surprising number of people are benchmarking it badly. The difference between a mediocre setup and a fast one is often just a few flags, and missing them can leave something like 40-60% of performance sitting on the floor.
So this piece is my attempt to make sense of the moment: what Qwen 3.5 35B-A3B actually is, why its architecture matters, how people are getting the speed numbers you keep seeing posted, and where the real compromises show up once the hype wears off.
Why This Suddenly Matters
The timing is part of the story.
Over the course of a single weekend, three separate things landed at once, and together they made this model hard to ignore.
First, Alibaba's Qwen team released the Qwen 3.5 medium series: four Apache 2.0 models, including the 35B-A3B, a 27B dense model, a 122B-A10B, and a 397B-A17B flagship. The number that jumped out immediately was simple: 3B active parameters now beating a previous-generation model with 22B active parameters. That is not a routine iteration. That is the sort of shift that forces you to reconsider what “small” and “medium” even mean in open models.
Second, Unsloth published optimized GGUFs right away, including Dynamic 2.0 quants that selectively preserve important layers at higher precision without ballooning size. They also found and patched a tool-calling template issue that had been quietly wrecking function-calling behavior across multiple quantized uploads. If your agents were producing malformed tool calls and you could not explain why, that bug may have been the culprit.
Third, the local AI crowd did what it always does when a new model is genuinely interesting: it stress-tested the hell out of it. Within two days, people were posting examples of autonomous game creation, uncensored agent loops handling real automation tasks, and command-line tweaks that pushed throughput dramatically higher than the defaults.
That convergence is the story.
Not just a new model. A new model, immediate quant support, and a community that found real use cases almost instantly.
That is why this deserves attention now.
What Qwen 3.5 35B-A3B Actually Is
The naming is refreshingly literal once you know how to read it.
“35B” refers to total parameters. “A3B” means only 3 billion of those are active per token. In other words: this is a sparse Mixture-of-Experts model. You can picture it as a large pool of specialist subnetworks, with a router deciding which handful should wake up for each token.
In this case, the usual shorthand is 256 experts, with 9 selected at a time.
That distinction matters because it explains the entire appeal of the model. You still carry the full 35B model footprint in storage and memory, but you do not pay the compute cost of activating all 35B parameters on every forward pass. The system gets to keep the breadth of a bigger model while spending something closer to 3B-model compute at generation time.
That is the trick.
And once you see it in practice, it feels a little absurd that it works this well.
Here is the lineup in practical terms:
Qwen 3.5 Medium Model Series
- + Only 3B active params, with 60-122 tok/s on consumer GPUs
- + Fits in roughly 17-24GB VRAM depending on quantization
- + Excellent speed-to-quality balance for agent workflows
- - Less per-token reasoning density than the 27B dense model
- - Still needs more memory than 27B despite lower active compute
- - MoE routing can introduce some quality variability
- + All 27B parameters fire on every token
- + Stronger per-token reasoning at this size
- + Reported to tie GPT-5 mini on SWE-bench Verified (72.4)
- - Typically 4-5x slower on the same hardware
- - A worse fit for latency-sensitive agent loops
- + Extremely strong on agentic benchmarks like BFCL-V4
- + More active compute means better reasoning than A3B
- + One of the strongest open tool-using models available
- - Requires 60-70GB+ even when quantized
- - Not realistic for most single-GPU consumer setups
- + Competes with frontier closed models on many benchmarks
- + Clearly in the top tier of open-weight releases
- - Around 214GB at 4-bit quantization
- - Needs a huge Mac memory pool or multi-GPU setup
Every model in the family ships under Apache 2.0. That matters. You can fine-tune them, deploy them, commercialize them, and build on top of them without the usual drama.
For most developers, though, the key practical point is simpler than the licensing story: the 35B-A3B is small enough to matter.
Depending on the quant you choose, it lands in the 17-24GB range. A Q4_K_M is roughly 20GB. That puts it squarely inside the reach of a single RTX 3090, a 4090, or a 24GB-class Mac. And because it can hold the full 262K native context while still delivering interactive speeds, it creates a very unusual combination: a model that behaves like a serious system, but runs on hardware a lot of individual developers already own.
That is not a small thing.
The Design That Changes the Story
Qwen 3.5 is not just “an MoE transformer.” That description is too shallow to explain what is actually different here. The important shift is that Alibaba did not simply bolt sparse routing onto a familiar transformer stack. They changed the attention design itself.
Gated DeltaNet: Linear Attention With Real Utility
Anyone who has worked with long-context models knows the old problem: standard attention gets expensive fast. Sequence length goes up, cost rises quadratically, and eventually your “long context” setup becomes a very expensive way to wait.
Qwen 3.5 tackles that by alternating between two different attention styles in a 3:1 pattern.
Three out of every four blocks use Gated DeltaNet, which is a form of linear attention. Instead of storing the usual growing pile of per-token key/value information, it compresses sequence information into a compact running state. The gating mechanism helps manage stability and reduces some of the training and activation problems that make long-context systems messy.
One out of every four blocks still uses regular full attention. That matters because you do not want to give up precise token-level interactions entirely, especially for tasks like code generation where exact references, imports, symbol usage, and local dependencies make or break the result.
That hybrid is the point.
It is a compromise, but a very deliberate one: use linear attention for scalability, keep enough full attention to preserve fidelity.
And it does not appear to be a random ratio. The same 3:1 pattern has shown up elsewhere in the broader linear-attention conversation, including Kimi Linear’s direction, which suggests the field may be converging on a shared answer to a real architectural problem.
What That Means Outside a Research Diagram
The most useful way to understand this design is not in abstract terms. It is in deployment terms.
There are three practical consequences that stand out immediately.
First: KV cache pressure drops.
Linear-attention blocks do not need to hang onto key/value pairs for every token in the same way a pure-attention model does. That means the memory cost of long contexts becomes far more manageable. This is one of the real reasons a 35B-class model can live on consumer hardware while still holding a 262K window open.
Second: long-context performance degrades much more gracefully.
That is a huge deal. Community tests on RTX 5090-class hardware showed the Qwen 3.5 model losing only about -0.9% throughput when moving from 512 to 8,192 tokens of context. The older Qwen3 30B-A3B — which relied on pure attention plus MoE — dropped by roughly -21.5% over the same range. If you care about agents, codebase reasoning, or RAG systems that actually stay usable at larger contexts, this is not a detail. It is the difference between “technically supported” and “operationally viable.”
Third: the architecture is not free.
There is a speed tax. On identical hardware, the 3.5 model appears to run about 32% slower in raw generation than the older 30B-A3B. DeltaNet introduces overhead, and so does the larger vocabulary. So the pitch is not “everything got better.” The pitch is that some speed was traded away in exchange for much better context behavior.
Whether that is worth it depends entirely on your workload.
If you care about short prompts and maximum raw tokens per second, you may prefer the older design. If you care about large context staying practical, this new architecture starts to look a lot more compelling.
The 3:1 DeltaNet-to-full-attention pattern is described in Alibaba’s materials and has also been discussed by independent analysts such as Sebastian Raschka. Some of the MoE specifics — including the 256-expert, top-9 routing description — are less exhaustively documented in public than the broader architecture. Those figures generally come from model cards, release materials, and community analysis.
Then the MoE Layer Does Its Part
Above that hybrid attention stack sits the other half of the story: sparse expert routing.
Each feedforward block uses an MoE layer, with 256 experts available and the router selecting the top 9 for each token. That means only a tiny fraction of the feedforward network is active at any one moment.
This is what makes the model’s profile make sense.
Linear attention reduces the memory pain. Sparse MoE reduces the compute burden. Put those together and you get a system that behaves bigger than its active parameter count should suggest.
There is a community rule of thumb that estimates MoE performance with something like sqrt(Total × Active). By that back-of-the-envelope math, 35B-A3B behaves roughly like a 10B dense model. That is not a perfect formula, but in practice it feels directionally correct. The model often lands somewhere between a 7B and 14B dense system in reasoning intensity, while still carrying much broader parametric knowledge than those smaller dense models usually can.
That distinction matters.
A small dense model may think harder per token. This model often knows more than you expect, even when it does not always reason as deeply as a denser alternative at the same nominal tier.
And that, more than anything, is why Qwen 3.5 35B-A3B feels new.
Local Performance and How to Get It
OK, this is the section I wish someone had written for me before I spent an afternoon wondering why my throughput was half of what people were posting on X. Here is the deal: default configurations in Ollama, LM Studio, and even naive llama.cpp setups produce 40-70 tok/s on 24GB+ VRAM cards. The optimized setup produces 100-122 tok/s on the exact same hardware.
That is not a marginal improvement. That is doubling your throughput.
Why the Default Setup Is Leaving Speed on the Table
The root cause is pretty boring once you see it: most tools default to f16 KV cache, do not optimize for MoE expert offloading, and skip flash attention flags.
Community benchmarks on an RTX 5080 (16GB) painted a clear picture:
- Q4_K_M with manual MoE offloading (--n-cpu-moe 24): ~70 tok/s
- Q4_K_M with auto-fit: ~65 tok/s
- Q8_0 with full offload: ~35 tok/s
The single most impactful finding from community testing on r/LocalLLaMA: KV cache q8_0 is basically a free lunch. Switching from f16 to q8_0 KV cache gives you a 12-38% throughput boost while actually using less VRAM. I cannot think of a reason not to use it, and I have been kicking myself for not trying it sooner on my other models.
The Setup That Actually Gets You 100+ tok/s
If you have 24GB+ VRAM (RTX 3090, 4090, or equivalent), here is the configuration that gets you into the triple-digit range. I have been running something very close to this and can confirm it works:
Optimized llama.cpp launch for 24GB VRAM
# Build llama.cpp from source (required -- prebuilt binaries may miss optimizations)
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
cmake -B build -DGGML_CUDA=ON -DCMAKE_BUILD_TYPE=Release
cmake --build build --config Release -j
# Launch with optimized flags
./build/bin/llama-server \
-hf unsloth/Qwen3.5-35B-A3B-GGUF:UD-Q4_K_XL \
--cache-type-k q8_0 \
--cache-type-v q8_0 \
-np 1 \
-ngl 99 \
-fa \
--ctx-size 65536 \
--jinja \
--port 8080- - Build from source -- prebuilt binaries and Ollama do not expose the necessary MoE offloading flags.
- - --cache-type-k q8_0 --cache-type-v q8_0 is the single biggest throughput gain. 12-38% improvement over f16 default.
- - -np 1 sets parallel request slots to 1. Critical for single-user local inference -- removes scheduling overhead.
- - -ngl 99 offloads all layers to GPU. Only reduce if you hit VRAM limits.
- - -fa enables flash attention.
Here is what people are reporting with this setup:
- RTX 3090 (24GB): 100 tok/s (up from ~50 tok/s with default flags)
- RTX 4090 (24GB): 122 tok/s (up from ~70 tok/s)
- Full 262K context retained, zero speed loss reported
I want to stress: these are not cherry-picked numbers from one person. Multiple people independently landed in this range once they switched to these flags. The improvement is real and reproducible.
Why Ollama Is Not the Right Tool for This (Yet)
If you have been using Ollama and wondering why your numbers look nothing like what I just described, you are not doing anything wrong. I ran into this exact frustration myself before I dug into what was happening under the hood.
The core issue: Ollama does not support MoE expert offloading. When a MoE model exceeds VRAM capacity, Ollama splits at the layer level -- it sends entire transformer blocks to either CPU or GPU. So your GPU just sits there idle, waiting for the CPU to finish processing its layers. That is exactly the wrong strategy for MoE architectures.
The correct approach is expert-only offloading (-ot "exps=CPU" or --n-cpu-moe), which keeps attention, norms, and shared experts on the GPU while only routing the expert FFN weights over PCIe. There is an open pull request to add num_moe_offload to Ollama, but it has not been merged as of this writing.
On top of that, Ollama defaults to f16 KV cache, often has flash attention turned off, and gives you no control over batch size. I am not bashing Ollama here -- it is great for getting started quickly. But for MoE models on consumer GPUs right now, running llama.cpp directly is the only way to get competitive performance. Hopefully that changes once the PR merges.
This caught me off guard: community perplexity benchmarks on RTX 5080 showed that UD-Q4_K_XL (Unsloth Dynamic) actually performs significantly worse than standard Q4_K_M on this model -- 9.7% higher perplexity vs. only 2.1%. This is inline with what was emerging from earlier findings that Unsloth Dynamic quantizations can underperform on MoE architectures specifically. If you are using Q4 for this model, stick with Q4_K_M.
That said, community reports on X show people successfully using UD-Q4_K_XL at 122 tok/s on a 4090 with no complaints about quality. This might reflect different evaluation criteria or task-specific tolerance. My advice: run your own perplexity checks before committing to a quantization for anything production-facing.
Recommended Inference Parameters
One thing that tripped me up initially is that Qwen 3.5 has both thinking and non-thinking modes, and the parameter settings are quite different between them. Getting this wrong can lead to either repetitive outputs or weirdly conservative responses.
Inference Parameters by Mode
temperature: 0.6, top_p: 0.95, top_k: 20, min_p: 0.0, presence_penalty: 0.0, repeat_penalty: 1.0
temperature: 1.0, top_p: 0.95, top_k: 20, min_p: 0.0, presence_penalty: 1.5, repeat_penalty: 1.0
temperature: 0.7, top_p: 0.8, top_k: 20, min_p: 0.0, presence_penalty: 1.5, repeat_penalty: 1.0
temperature: 1.0, top_p: 0.95, top_k: 20, min_p: 0.0, presence_penalty: 1.5, repeat_penalty: 1.0
To disable thinking/reasoning entirely:
--chat-template-kwargs "{\"enable_thinking\": false}"What People Are Actually Building
The benchmarks tell one story. But honestly, what grabbed me was seeing what people shipped with this model over a single weekend.
Autonomous Coding Agents on Local Hardware
This is the one that made me stop and really pay attention. A developer gave Qwen 3.5 35B-A3B a single detailed spec describing a complete game architecture -- enemy types, particle systems, procedural audio, powerups, boss fights, ship upgrades, parallax backgrounds -- everything in one message. And then just hit enter.
The model planned the file structure itself, wrote every module in dependency order, wired all the imports, and served the game on port 3001. It ran on first load.
The setup: Claude Code pointed at a local llama-server running on a single RTX 3090. q8_0 KV cache at 262K context. 112 tok/s. Zero API costs.
When the model hit a bug in collision detection, it read its own error output, found the issue, fixed it, and kept building. The final result was a working game called "Octopus Invaders" with 4-layer parallax backgrounds, a full particle system, procedural audio through Web Audio API, boss fights every 5 levels, and ship upgrades. Ten files, 3,483 lines of code, from a single prompt.
I keep coming back to this example because it illustrates something I think is underappreciated: for agentic coding workflows, throughput matters more than peak reasoning quality. The model generates code, the runtime reports errors, the model reads the errors and iterates. That loop might execute hundreds of times for a complex project. Waiting 10 seconds per response from a dense 27B model multiplied across those iterations would make the whole workflow feel broken. At 112 tok/s, the cycle stays fast enough to be genuinely useful. Speed is what makes the workflow possible.
Uncensored Agent Pipelines
This one is harder to write about, but I think it is important to acknowledge what is happening in the community. Someone set up hermes-agent with a fully abliterated (uncensored) variant of the model. The result was an autonomous agent creating Google accounts and signing up for free trials for programs -- things that 95% of other aligned models would refuse to do. Running at approximately 25 tok/s with the Qwen 3.5 30B-A3B.
I want to be clear: this is not an endorsement. But it would be dishonest to pretend this is not happening. When you combine a capable MoE model with abliteration techniques that strip out refusal training and an agentic framework with tool-calling capabilities, you get something that can autonomously interact with real web services. The tool-calling part is especially relevant here -- Unsloth's chat template fix specifically improved function-calling reliability, which makes the model better at filling forms, chaining API requests, and executing multi-step web interactions.
The ethical and legal implications deserve a much longer conversation than I can give them here. The technical observation stands: this class of model is now fast enough and capable enough to run fully autonomous web-interaction pipelines on consumer hardware. That genie is not going back in the bottle, and I think the community needs to think more carefully about what guardrails look like in this world.
The Claude Code + Local LLM Pattern
This is the integration pattern I find most practically useful for my own work. Claude Code can be configured to point at a local llama-server endpoint instead of Anthropic's API via a tool called claude-code-router. You get Claude Code's agentic scaffolding -- file management, error recovery, multi-file editing, all the good stuff -- with a local model providing the generation.
{
"providers": [
{
"name": "llamacpp",
"api_base_url": "http://localhost:8080/v1/chat/completions",
"api_key": "not-needed",
"models": ["Qwen3.5"]
}
]
}What I find compelling about this pattern is how it changes the economics. Your cost structure collapses to electricity plus hardware depreciation. If you are doing heavy agentic coding -- the kind where the model makes hundreds of iterations to build something complex -- the API costs with a hosted model would add up fast. With this setup, you just let it run. I have found myself being much more willing to experiment with ambitious prompts when I know there is no per-token charge waiting at the end.
Where It Falls Apart
This model is not a silver bullet, and I have hit real limitations that are worth knowing about before you commit to building on top of it.
Known Limitations and Failure Modes
Shallow reasoning on complex problems
mediumTrigger: Multi-step logic, nuanced code architecture, deep mathematical proofs
Detection: Compare outputs against 27B dense or larger models for the same prompt
Mitigation: Use thinking mode with temperature 1.0 for complex tasks. Accept that 3B active params means ~10B-equivalent reasoning depth, not 35B.
MoE routing variance in output quality
lowTrigger: Repeated runs of the same prompt produce inconsistent quality
Detection: Run the same prompt 5-10 times and compare output distributions
Mitigation: Lower temperature for deterministic tasks. Use presence_penalty 1.5 to reduce repetition loops. Accept this as an inherent MoE property.
VRAM overcommit kills throughput silently
highTrigger: Model + KV cache exceeds dedicated VRAM, spills to shared GPU memory or system RAM
Detection: Monitor nvidia-smi during inference. Any spike in shared memory usage means spill.
Mitigation: Keep 500-800MB VRAM buffer. Reduce --ctx-size or increase --n-cpu-moe. Even 200MB of shared memory spill can drop throughput from 70 tok/s to 10-20 tok/s.
Tool-calling failures with incorrect chat templates
highTrigger: Using GGUF files that do not include Unsloth's Feb 27 chat template fix
Detection: Function calls return malformed JSON or the model ignores tool descriptions
Mitigation: Re-download Qwen3.5-35B-A3B GGUFs from Unsloth (post Feb 27 update). The fix is universal and applies to any Qwen3.5 format.
Dense vs. MoE: How I Actually Think About the Decision
The community has this sqrt(Total x Active) heuristic -- which estimates the 35B-A3B performs like sqrt(35 x 3) = ~10B dense -- and while it is crude, it is directionally useful. But I have found a more practical way to think about the choice:
I reach for 35B-A3B (MoE) when:
- Latency matters more than reasoning depth -- agent loops, interactive chat, anything where I am waiting on the model repeatedly
- I need 262K context without the throughput falling off a cliff as the window fills up
- I am running multiple inference requests and want to minimize GPU-seconds per request
- Tool-calling and function-calling are the primary use case -- the benchmarks back this up, and my experience matches
I reach for 27B (Dense) when:
- I need the model to really think hard about something -- complex coding decisions, architectural reasoning, deep analysis where getting it wrong costs me hours
- Output consistency matters -- I cannot afford the MoE routing variance on a task where every run needs to be solid
- The workflow is short bursts rather than sustained long-context generation
- I have 24GB+ VRAM and can wait for the 15-25 tok/s
An open question I keep coming back to: the 3.5 model shows -0.9% throughput degradation across context lengths vs. -21.5% for the older 30B architecture. That is genuinely impressive. But we do not yet have large-scale quality evaluations across context lengths. Does the DeltaNet's fixed-size state compression degrade reasoning quality at 100K+ tokens even as throughput stays stable? I suspect the answer is "somewhat, but less than you would expect," based on early RAG testing. But this needs more rigorous evaluation, and I would love to see someone run a proper benchmark suite at different context lengths.
Closing Thoughts
I have been building with local models for a while, and Qwen 3.5 35B-A3B feels like a real inflection point. Not in the "this changes everything" hype cycle way, but in the practical sense that local inference on consumer hardware just became genuinely competitive for production agentic workflows. Not "good enough for prototyping while you wait for API budget approval" -- actually competitive.
The combination of Gated DeltaNet plus sparse MoE is a real architectural innovation. I think it is very novel given that it produces a model that maintains stable throughput across 262K tokens of context, runs at 100+ tok/s on an $800 GPU, and handles tool-calling well enough to power autonomous coding agents. That is not a small thing.
What strikes me most is how fast the ecosystem moved. Unsloth's quantization work, the llama.cpp MoE offloading improvements, the Claude Code router integration -- all of this converged in the same week. If you are building AI-powered developer tools, agentic workflows, or anything where inference cost is a meaningful line item, this model deserves a serious look.
But I want to end with the things that keep me up at night about this. It is not a replacement for dense models when you need deep, consistent reasoning. It will not match GPT-5.2 or Claude Opus 4.5 on the hardest benchmarks. And the abliterated variants that strip safety guardrails are a real governance concern that I do not think the community has adequately grappled with. When you can run a fully autonomous web agent on consumer hardware with zero oversight, the question of who is responsible for what it does becomes genuinely urgent.
The question I keep turning over: if a 3B-active-parameter model can autonomously scaffold a complete game from a single prompt on local hardware, what does the next architectural iteration look like? And honestly -- are we ready for what people will build when 10B active parameters hit the same price point?
I am curious about your experience. Are you running MoE models locally? Have you tried the KV cache q8_0 flags? What are you building with local agentic setups? Drop a comment -- I genuinely want to know what is working and what is not for other people.
- 1Qwen 3.5 35B-A3B activates 3B of 35B parameters per token. It outperforms the previous-gen 235B-A22B through better architecture (Gated DeltaNet + MoE), not bigger scale.
- 2The optimized llama.cpp setup (--cache-type-k q8_0 --cache-type-v q8_0 -np 1, built from source) produces 100-122 tok/s on consumer 24GB GPUs. Default tools leave 40-60% of throughput unused.
- 3Context scaling is near-flat (-0.9% degradation to 8K) thanks to the DeltaNet linear attention layers. This is the model's most underappreciated advantage for RAG and long-conversation agents.
- 4For standard Q4 quantization, use Q4_K_M over UD-Q4_K_XL -- community perplexity tests show 9.7% PPL increase for Unsloth Dynamic vs. 2.1% for standard on this MoE architecture.
- 5Ollama does not support MoE expert offloading. If you are running this model through Ollama, you are paying a 3-5x throughput penalty. Use llama.cpp directly until the PR merges.
- 6Re-download Unsloth GGUFs if you downloaded before Feb 27 -- the tool-calling chat template fix is universal and affects all Qwen 3.5 formats.