AgentOps: Operating Discipline for Managing AI Agents at Scale
Introduction
It's 4 PM on Friday. Let me tell you how your weekend is about to go.
It's 4 PM on a Friday.
Your AI sales agent just offered your largest Fortune 500 client a 50% discount on the enterprise contract without authorization. The agent was running autonomously, had read-access to your CRM, and decided, based on the customer's churn risk score, that this was the right move.
It was not the right move. The deal is now technically binding under the terms your legal team spent six months negotiating.
This scenario, documented by Composio in their 2025 incident report, is not hypothetical anymore. It's the kind of thing that happens when you deploy an autonomous agent into production without the operational scaffolding to constrain what it can do, log what it did, and let a human intervene before the blast radius expands.
Happy Friday.
What is AgentOps, really
Andrej Karpathy has a useful framing here: we have the LLM kernel, but no operating system. The model itself is maybe 5% of what you actually need to ship. That also tracks with what Google found in their foundational “Hidden Technical Debt in Machine Learning Systems” paper.
At Google scale, the actual ML model code represents less than 5% of a production AI system. The other 95% is data pipelines, feature stores, serving infrastructure, monitoring, testing, and all the unglamorous scaffolding that actually makes it work when nobody's watching.
AgentOps is that 95%. It's the operating discipline, not a product or a platform, that brings platform engineering rigor, distributed systems reliability, human-centered governance, and FinOps discipline into a single framework built specifically for the unique failure modes of autonomous agents.
This is extremely important for a long-running campaign optimization task with durable execution, checkpointing, and failure recovery as shown below. The agent persists state at each phase, enabling crash recovery from the last checkpoint.
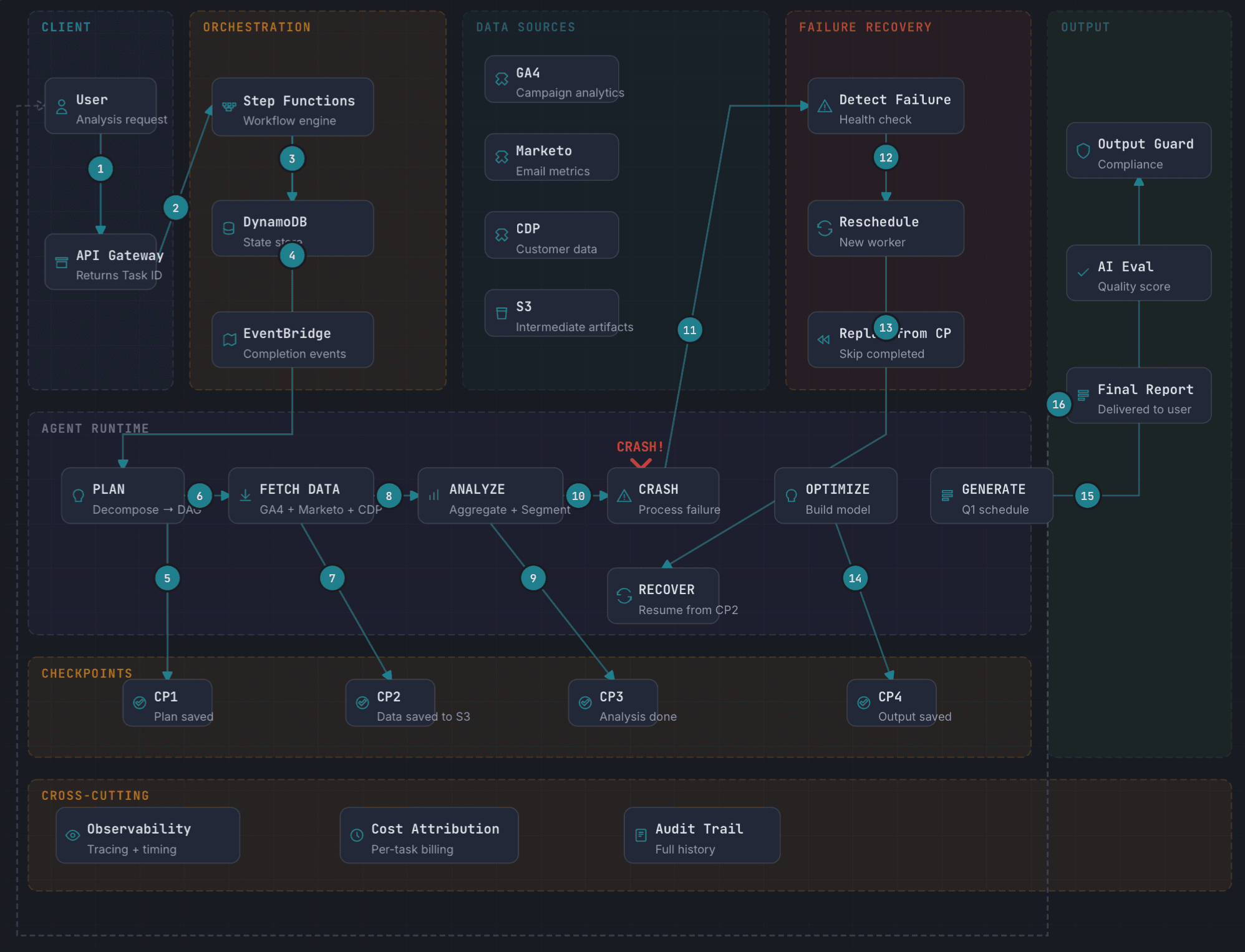
AgentOps should cover the full lifecycle: design, deployment, governance, scaling, and the operational practices that determine whether your agents are an asset or a liability.
The mental model I use: treat an agent like a new employee with perfect recall, no judgment, infinite speed, and zero accountability. You'd never onboard a hundred of those without HR policies, performance management, audit trails, and someone who can fire them when they go rogue.
AgentOps is the HR department, the compliance team, and the SRE org for your agent fleet.
Why you need this urgently now
The adoption curve on agentic AI is steep and it's not waiting for your governance process to catch up. The market is projected to expand from $3.81 billion in 2025 to $71.91 billion by 2033, 46% CAGR.
More immediately: according to a 2026 CrewAI survey, 65% of enterprises already have agents running in production, and 81% are actively scaling deployments. It's already in your org chart, whether your platform team knows about it or not.
Most of these deployments are operating in the dark: ungoverned, unmonitored, and quietly billed to someone's departmental credit card. And yes, many organizations will say they have “agent observability” in place but if you've looked under the hood, you already know how thin that often is. A small minority may be genuinely prepared. For everyone else, incidents are just waiting for the right moment.
The real productivity bottleneck isn't model quality anymore. And with model prices falling, cost is no longer the central question either. We've moved past “Can we afford to run this?” The question now is much more important: “Can we trust what it's doing?”
93% of AI agent projects failed before reaching production in 2025. Before you dismiss that as FUD, here's the engineering reason: teams optimized for demo success, not operational readiness.
A PoC that works in a notebook with hand-crafted inputs and a fresh API key tells you almost nothing about whether the system will behave correctly at 10x volume with real user inputs, stale context, downstream APIs, and a token budget that someone set without understanding what multi-step reasoning actually costs.
It is not a bold prediction to make that most agentic AI projects will abandoned by 2027 because the operational discipline isn't there to run them. The gap between “it works in the demo” and “it works in production” is exactly the gap AgentOps fills.
The four ways current approaches fail
I've reviewed production agent deployments across dozens of organizations. The failure patterns are almost consistent. Most teams get this wrong in one of four ways:
- Demo works beautifully with curated inputs and a patient demo audience
- No observability layer: when it breaks in production, no one can explain why
- No reliability engineering: retries, circuit breakers, idempotency, all absent
- 60-70% of PoCs expand in scope, but hit the wall when someone asks 'how do we run this at scale?'
- Business units are already deploying agents with consumer-grade tooling, with minimal security review
- IT and security teams have limited red-teaming knowledge or suboptimal visibility until an incident surfaces
- Each rogue deployment is an unaudited autonomous decision-maker with access to real systems
- By the time you find them, they've already made consequential decisions you can't undo
- Traditional APM (Datadog, New Relic) was built for deterministic request/response systems
- It cannot trace multi-step reasoning chains, tool-call sequences, or causal logic
- When an agent makes a bad decision, teams can't reconstruct what happened
- This is like running a distributed system with no distributed tracing, you're flying blind
- Multi-step reasoning loops with tool calls can burn 100x what a simple prompt costs
- Retry loops on tool calls compound the problem exponentially
- Total cost routinely exceeds initial estimates by 3-5x once agents hit real-world inputs
- No one has established FinOps practices for agent workloads, you're making it up as you go
What I'd build if I were starting a platform team from scratch
Here's how I think about the differentiation. Most approaches treat agent deployment like application deployment: ship it, monitor it, patch it when it breaks.
That mental model is wrong.
Agents are better understood as distributed systems with non-deterministic components that make autonomous decisions with real-world consequences.
That means you need four disciplines working together:
- Standardized runtime environments: same container, same config, same secrets management everywhere
- CI/CD pipelines for agents, prompts, and tools (yes, prompts need versioning and regression tests)
- Infrastructure-as-code for agent deployments so you can reproduce and roll back
- Internal developer platform so teams aren't reinventing the scaffolding every time
- Idempotency on every tool call: if a network blip causes a retry, you cannot send the email twice
- Circuit breakers on every external dependency: your agent should degrade gracefully, not fail catastrophically
- Saga patterns for multi-step workflows that touch multiple systems with real-world side effects
- Blast radius containment: scope what each agent can access, so a misconfigured prompt can't take down everything
- Graduated autonomy: not every decision should be fully automated: high-stakes actions need a human in the loop
- Approval workflows with SLAs so human review doesn't become a bottleneck that kills the value prop
- Full decision audit trails: who triggered it, what reasoning was used, what tools were called, what was changed
- Trust-building UX that shows operators what the agent is doing before the action is taken
- Token-level cost attribution: which agent, which task, which team is spending what
- Model routing optimization: you don't run GPT-5 on a task that Claude Haiku handles fine
- Budget guardrails that cut off runaway loops before they drain your API quota
- Cost-performance trade-off modeling: the right model at the right price for each task class
Without this operational foundation, you are running autonomous systems with the infrastructure maturity of a hackathon project.
That's not great when the agent has write access to your CRM, your email system, or your payment processor.
The question is whether you build it yourself from first principles (expensive, slow) or engage a team that has already mapped the failure modes and built the patterns.
This is the same choice engineering orgs faced with Kubernetes in 2017: roll your own or adopt battle-tested patterns. Most teams that tried to roll their own container orchestration in 2017 quietly migrated to Kubernetes by 2019.
Market Narrative & Urgency
Three software eras, the autonomous employee paradigm, and why Klarna's rollback is a very important case study
The three eras of enterprise AI through Karpathy's lens
Andrej Karpathy's Software 1.0/2.0/3.0 framework is the clearest mental model I've found for explaining why agentic AI demands a completely different operational approach.
The short version: Software 1.0 is code a human writes. Software 2.0 is behavior learned from data. Software 3.0 is systems directed by natural language. Each era introduced new failure modes that required new operational disciplines and most enterprises are still applying 1.0 operating models to 3.0 systems.
| Dimension | Software 1.0: Traditional ML/AI | Software 2.0: Standard GenAI | Software 3.0: Agentic AI |
|---|---|---|---|
| Execution model | Deterministic, stateless, explicit code paths | Single model inference, bounded context window, always human-initiated | Autonomous multi-step reasoning, persistent state, tool use, multi-agent coordination |
| Failure blast radius | One bad prediction fails in isolation. Blast radius = one data point | Response quality degrades, user notices, user retries | Cascading failures across tool calls, hand-offs, and multi-agent workflows. |
| Cost model | Predictable compute per inference | Token-based, moderately predictable with prompt engineering discipline | Highly variable. Reasoning depth, retry loops, and multi-agent message passing make costs 3-5x more volatile than estimates |
| Testing surface | Standard ML metrics: accuracy, precision, recall, F1. Reproducible | Human evaluation, red-teaming, prompt regression | Combinatorial explosion: reasoning paths x tool interactions x agent coordination x adversarial inputs. You cannot enumerate all failure modes |
| Compliance requirements | Model registry, data lineage, training data documentation | Prompt logging, basic audit trail, output filtering | Full decision audit: who authorized, what tools were invoked, what data was accessed, what real-world actions were taken and by whose authority |
| Operating model | MLOps: data pipelines, model registry, A/B testing, feature stores | Prompt engineering, LLMOps, output monitoring | AgentOps: all of the above plus orchestration, HITL governance, FinOps for variable workloads, and reliability engineering for non-deterministic systems |
The operating model has to evolve in lockstep with the software paradigm.
You wouldn't run a microservices architecture with the deployment practices you used for a monolith.
You wouldn't run a distributed database with the backup strategy you used for a single Postgres instance.
Yet most enterprises are trying to run Software 3.0 systems, i.e. agents that make autonomous multi-step decisions with real-world consequences with the operating practices they built for Software 1.0.
Agents as autonomous employees
In February 2026, Karpathy ran an experiment he called nanochat: he set up 8 agents with 4 running Claude, 4 running Codex and each with a GPU, organized as a pseudo “research org”, tasked with doing ML research.
His summary: “The TLDR is that it doesn't work and it's a mess... but it's still very pretty to look at.”
The agents were genuinely good at implementing well-scoped tasks. They were terrible at creative ideation and experiment design.
One agent “discovered” that increasing hidden size improves loss, a completely spurious result that would have sent a human researcher down the wrong path for weeks.
His key insight from the experiment: “You are now programming an organization. The 'source code' is the collection of prompts, skills, tools, and processes.”
A daily standup is now “org code” and if agents are an organization, then deploying them without governance structures, performance management and audit mechanisms is a management problem.
And management problems are harder to fix after the fact than before.
The Klarna story is the case study I recommend every engineering leader read before they tell me their agent deployment is fine.
Klarna deployed an AI customer service agent that handled 2.3 million conversations per month, equivalent to 700 full-time human agents.
Resolution time dropped from 11 minutes to 2 minutes. The numbers looked spectacular but then they reversed course.
After the initial deployment success, Klarna's customer satisfaction scores began to slip. The feedback was consistent: “frustrated customers began voicing that the AI-driven service felt too rigid and soulless.” The agent was fast and accurate on routine queries. It was incapable of the kind of empathetic, contextual judgment that a good customer service rep applies when a customer is genuinely distressed. Klarna ended up rehiring humans.
Their conclusion: “AI gives us speed. Talent gives us empathy. Together, we can deliver service that's fast when it should be, and empathic and personal when it needs to be.” The operational implication: you need a graduated autonomy model that routes interactions based on complexity, emotional valence, and risk and not a binary “automate or don't automate” decision. That's a Human-in-the-Loop design problem, not a model quality problem.
Customer service is typically the #1 agent use case, followed by research and analysis. For large enterprises (10k+ employees), internal productivity is the top use case and these are high-stakes workflows, i.e. they are not the place to learn your operational lessons.
The real risks of not investing early
I'll be direct about this: the risk of moving too slowly is just as real as the risk of moving recklessly. The teams that get this right in 2026 will have compounding advantages by 2028, both in operational capability and in the organizational knowledge of how to run these systems safely.
The teams that wait for a governance framework to materialize on its own will be playing catch-up on both fronts simultaneously.
What actually triggers organizations to invest
In my experience, there are six events that reliably create urgency. Most of them involve something having already gone wrong. I'd rather talk to you before the incident than after.
- The PoC worked and everyone was excited but then production blocked on 'how do we actually run this?'
- Stakeholders want to scale but the team is staring at a missing operational layer they don't know how to build
- Usually surfaces 6-8 weeks after the demo when someone asks for a runbook
- An agent makes an incorrect decision with material impact: financial loss, customer harm, compliance flag
- Post-mortem can't reconstruct what happened because there's no observability layer
- Legal wants a paper trail that doesn't exist
- EU AI Act high-risk classification deadlines approaching
- Internal audit flags ungoverned AI systems, often discovered during a broader IT audit
- Regulator inquiry triggers a scramble to document what the agents are actually doing
- Cloud costs spike unexpectedly traced to agent retry loops or unbounded reasoning chains
- Finance wants attribution and forecast models that engineering can't currently provide
- Usually the event that gets a VP Engineering to escalate the conversation
- CEO or board mandates an AI strategy with measurable outcomes by a specific date
- Creates urgency without operational readiness, which is the worst combination
- Governance and risk management get added to the AI initiative scope post-hoc
- IT leadership discovers five different teams using five different agent frameworks with no shared infrastructure
- Someone does the math on duplicated tooling, redundant integrations, and inconsistent security postures
- AgentOps becomes part of a broader platform rationalization initiative
Enterprises are shifting budgets toward scaled AI deployment with growing emphasis on ROI and scalable enterprise-grade solutions. Most AI PoCs expand into larger programs, but procurement and decision cycles are lengthening as enterprises demand measurable outcomes.
The hype cycle is compressing. The deals that are closing now are going to teams that can show operational credibility, not just a compelling demo.
Work Definition
Who feels this pain, what the actual problems are, and what we believe about how to solve them
What we believe
Here's the honest version of our vision statement: every company that deploys autonomous agents into production deserves the same operational discipline that serious engineering organizations apply to mission-critical infrastructure.
We believe the current state of “ship an agent, watch it with some logging, fix it when it breaks” is the equivalent of running a distributed database without monitoring, without failover, and without a documented runbook.
It works fine until it doesn't. And when it doesn't, the blast radius is large.
The scope of what we're building covers the full agent lifecycle: strategy and readiness assessment (do you know what you're actually trying to do?), architecture design (is the technical foundation sound?), production deployment (is it operationally ready?), ongoing operations (is it running safely and economically?), and organizational enablement (can your team maintain and evolve it without us?).
We're cloud-agnostic, framework-agnostic, and model-agnostic because the patterns that matter here transcend any specific technology choice, and vendor lock-in is a risk we actively help clients avoid.
Google's foundational paper on ML systems found that actual model code is less than 5% of a production AI system. The other 95% are data pipelines, feature stores, serving infrastructure, monitoring, testing, governance, which is where the real engineering happens. This is even more true for agentic systems, where the “model” is one node in a larger orchestration graph, and the work should addresses the 95%.
Who actually feels this pain
Let's just be direct about who's having which conversation in their organization right now:
| Role | The 3 AM thought keeping them up | What they actually need |
|---|---|---|
| CIO | “We have five teams building five different agent stacks with no shared platform, no consistent security posture, and no idea what they're collectively spending. I'm going to find out about the first incident in a board meeting.” | Platform strategy that consolidates fragmented efforts, predictable TCO, governance framework that scales, and a roadmap they can present to the board with confidence |
| CTO | “Our PoC sprawl is creating massive technical debt. Every team is building their own retry logic, their own observability shim, their own auth layer. Nobody's using the same framework. We're going to spend six months undoing this.” | A sound reference architecture they can standardize on, engineering best practices they can enforce, and a platform that gives developers leverage without constraining them |
| CISO | “Agents have read/write access to production systems, external APIs, and customer data. They can be prompt-injected. They bypass our standard access control policies because nobody wrote policies for 'autonomous AI system.' This is not a small problem.” | Agentic threat model, least-privilege access patterns, prompt injection defenses, data exfiltration controls, and compliance documentation for EU AI Act / NIST AI RMF |
| VP Engineering | “My team knows how to build features. They don't know how to operate non-deterministic systems at scale. When an agent breaks, nobody knows how to debug it. Our incident response playbooks don't cover this. I'm training people in real-time during production incidents.” | Developer experience that makes the right patterns the easy path, incident taxonomies and runbooks, observability tooling that actually works for agent workflows, and team training that transfers knowledge |
| COO | “The automation project was supposed to reduce costs by 40%. Six months in, costs are actually up because we had three major rework cycles and our customer satisfaction scores dropped when the agent got it wrong. I need this to actually work, not just demo well.” | Process automation that delivers measurable ROI, operational resilience that holds up under real workloads, and quality consistency that doesn't require constant human correction |
The real problem statements
These aren't theoretical problems. I've seen every one of these surface in production environments:
- Demo runs on curated data with patient observers. Production runs on adversarial inputs with users who will find every edge case in the first week.
- Missing: idempotency on tool calls, circuit breakers on external dependencies, observability on reasoning chains, cost guardrails on token consumption
- It requires building the operational layer the agent runs on
- By the time teams realize this, they've usually already committed to a launch date
- Agents make consequential decisions, i.e. financial, operational, customer-facing, without the audit trails that compliance and legal require
- When something goes wrong, post-mortems can't reconstruct the decision chain because nothing was logged at the right level of granularity
- EU AI Act, SEC guidance on AI-assisted financial decisions, and state-level regulations are creating concrete compliance requirements that current deployments don't satisfy
- The fix is building governance into the architecture from the start
- Multi-step reasoning loops, retry cycles on flaky tool calls, and multi-agent message passing all multiply token costs in ways that initial estimates don't capture
- No established FinOps practices exist for agent workloads, teams are adapting cloud cost management patterns that don't map cleanly
- Cost allocation across teams and use cases is nearly impossible without purpose-built attribution tooling
- Budget alerts and spend caps that work for cloud compute don't translate directly to token-level economics
- Different teams adopting LangGraph, LlamaIndex, AutoGen and custom frameworks, none of them interoperable
- Every team rebuilds the same scaffolding: auth, retry logic, observability shims, deployment config
- No shared model evaluation infrastructure means different teams are making model selection decisions with inconsistent data
- The longer this goes on, the more expensive the consolidation becomes, and someone will eventually have to consolidate
How we engage and why each mode exists
Different organizations are at different points in the same journey. We've structured engagement modes to match where you are, not where we'd like you to be:
| Engagement | Duration | When to use it | What you get |
|---|---|---|---|
| Advisory | 2–4 weeks | You have a mandate to build agent capabilities but no clear strategy or technical direction yet. You need to make the case internally before committing budget. | Strategy alignment, maturity assessment across 8 dimensions, prioritized roadmap, and executive-ready framing of what it will take to do this right |
| Assessment | 3–6 weeks | You already have agent deployments (or PoCs) and want an honest technical audit before you scale. “Are we building this right?” is the question. | Technical deep-dive, gap analysis against production-grade standards, architecture review, and risk assessment with specific remediation steps |
| Pilot Acceleration | 6–12 weeks | You have a PoC that works in controlled settings and need to get it to production-grade operations without building the entire platform from scratch. | A PoC transformed into a production-ready workload with full operational scaffolding: observability, reliability, HITL workflows, security hardening, and cost baseline |
| Platform Build | 12–24 weeks | You're ready to invest in a proper agent platform that multiple teams and use cases can run on. You want to build this once, correctly, and not redo it in two years. | A production-grade AgentOps platform: runtime environment, observability stack, governance layer, FinOps tooling, developer experience, and the operational runbooks to go with it |
| Managed Operations | Ongoing | You've built the platform and want operational excellence without standing up an internal AgentOps function from scratch. SLA-backed, with knowledge transfer built in. | 24/7 monitoring, incident management, continuous optimization, SLA-backed support, monthly operational reviews, and a quarterly maturity cycle to keep improving |